Базы данных Oracle - статьи
Архитектура HP Oracle Exadata Storage Server в составе HP Oracle Database Machine
В конце сентября 2008 г. Oracle анонсировала 2 программно-аппаратных решения: HP Oracle Exadata Storage Server, позиционируемый как интеллектуальное устройство хранения для реляционных баз данных, и HP Oracle Database Machine — оптимизированное прединсталлированное преконфигурированное DW на базе кластера Oracle Database с Real Application Clusters (RAC) и HP Oracle Exadata Storage Server. Хотя HP Oracle Exadata Storage Server и представляется как самостоятельное решение, оно не продается отдельно и поставляется только в составе HP Oracle Database Machine. Эти решения полностью реализованы на продуктах HP, изготавливаются и собираются на заводах HP по заказу Oracle. В настоящее время эти решения продвигаются и сопровождаются Oracle или ее сертифицированными партнерами.
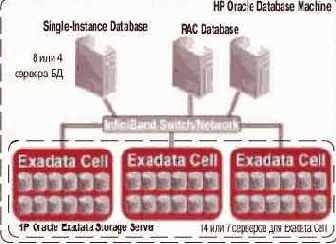
Рис. 4. Архитектура HP Oracle Database Machine.
HP Oracle Exadata Storage Server работает только в составе HP Oracle Database Machine, начиная с версии Oracle Database 11g, Release 11.1.0.7. HP Oracle Exadata Storage Server призван заменить внешние дисковые массивы (SAN/NAS) и, самое главное, значительно повысить производительность обработки запросов в многотерабайтньгх В1-хранилищах.
Поставляется две версии HP Oracle Database Machine — полная и "половинчатая", соответственно, стандартная 42U стойка или ее половина.
Общая архитектура HP Oracle Database Machine представлена на рис. 4. В ней один или множество (для RAC) серверов БД соединяются через Infiniband-коммутаторы с HP Oracle Exadata Storage Server.
В полной комплектации HP Oracle Database Machine содержит:
- 8 DL360 Oracle Database серверов (2 quad-core Intel Xeon, 32GB RAM) с установленными Oracle Enterprise Linux и Oracle RAC;
- 14 Exadata Storage Cells с дисками SAS или SATA, соответственно, допуская масштабирование до 21 Тбайт и 46 Тбайт некомпрессионных пользовательских данных;
- 4 InfiniBand-коммутатора по 24 порта;
- оборудование для управления (1 Gigabit Ethernet-коммутатор, Keyboard, Video, Mouse (KVM) hardware).
Каждый HP Exadata Storage Server имеет потоковую производительность до 1 Гбайт/c и реализован на базе сервера HP DL180 G5 (2 Intel quad-core processors, 8 Гбайт RAM, Dual-port 4X DDR InfiniBand card, 12 SAS- или SATA-дисков). Он поставляется со следующим установленным ПО: Oracle Exadata Storage Server Software, Oracle Enterprise Linux, HP Management Software (рис. 5).
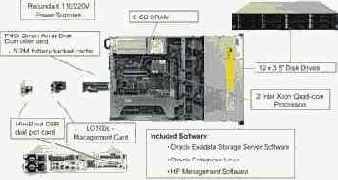
Рис. 5. Конструктивная реализация отдельной ячейки HP Exadata Storage Server.
Доступность данных на ячейках Exadata поддерживается за счет зеркалирования данных c помощью ПО Automatic Storage Management (ASM) и возможности горячей замены отдельных дисков. Зеркалирование данных отдельной ячейки на множестве других гарантирует, что отказ ячейки не будет вызывать потерю данных или снижать их доступность.
Каких-либо ограничений по масштабированию (по заявлениям Oracle) HP Oracle Exadata Storage Server не существует, поэтому приобретая дополнительные стойки Exadata, можно в онлайновом режиме объединять их в общее консолидированное хранилище.
В настоящее время поставки осуществляются только в виде двух вышеуказанных базовых конфигураций.
Где целесообразно использовать HP Oracle Exadata Storage Server?
HP Exadata Storage Server ориентирован, прежде всего, на работу с приложениями, которым приходится обрабатывать таблицы БД размером от сотен мегабайт до нескольких терабайт, и где часто необходимо выполнять полное сканирование таблиц. В качестве классических примеров можно назвать BI-системы, отчетные системы и им подобные. Транзакционные системы, имеющую высокую интенсивность по чтению/записи большого количества файлов размером до нескольких мегабайт и несколько больше преимуществ при работе с Exadata не получат или это будет не настолько эффективно как в первом случае.
Однако это не означает, что для разных классов приложений или групп пользователей требуется создание разных физических хранилищ данных. Exadata позволяет смешивать и приоритезировать различные нагрузки как между различными группами/классами пользователей/приложений внутри одной базы, так и между базами данных, гарантируя при этом заданный (в соответствии с SLA) уровень выделения ресурсов ввода/вывода (рис. 6). Например:

Рис. 6. HP Exadata Storage Server поддерживает гарантированное распределение IO-ресурсов как между БД, так и группами пользователей/приложений.
За счет чего достигается основное преимущество при использовании HP Exadata Storage Server?
Необходимо сразу отметить, что за счет устанавливаемого специализированного ПО каждая ячейка "понимает" структуру таблицы. Само повышение производительности при работе с таблицами большого размера происходит за счет двух факторов. Во-первых, при записи таблицы на HP Exadata Storage Server она равномерно "размазывается" на все ячейки — все серверы HP Exadata Storage Server. Поэтому при обработке запроса происходит его распараллеливание между всеми ячейками и, соответственно, чем и их больше, тем больше коэффициент параллелизма. Однако даже при наличии только одной ячейки эффект повышения производительности может быть многократным — это второй фактор. Это связано с тем, что за счет того, что сервер (ячейка) Exadata понимает структуру таблицы, при обработке запроса она не просто отсылает серверу БД часть таблицы (которая хранится на данной ячейки), а производит его обработку. Т.е. при использовании Oracle Exadata, обработка SQL перемещается с сервера базы данных к Oracle Exadata Storage Server. Oracle Exadata самостоятельно выполняет функцию отгрузки данных в дополнение к обеспечению традиционных блоковых сервисов к базе данных. Одна из уникальных вещей, которые Exadata-хранение делает по сравнению с традиционным хранением — возвращение только строк и столбцов, которые удовлетворяют запрос к базе данных, а не полную таблицу, как обычно делалось. Exadata выполняет SQL-запрос, максимально оптимизируя его для аппаратных средств, добиваясь максимального параллелизма работы дисков. В целом, это уменьшает загрузку центрального процессора на сервере базы данных, уменьшает требуемую полосу пропускания при перемещении данных между серверами базы данных и серверами хранения, обеспечивает балансировку нагрузки на ячейках Exadata.
Процесс фильтрации данных (в английской терминологии этот процесс еще называют Predicate Offload или Smart Scan), т.е. как именно Exadata возвращает меньше данных, чем обычный дисковый массив, является одним из ключевых преимуществ Exadata. Вот как описывает его более подробно в своем блоге Дмитрий Волков (менеджер по развитию бизнеса, Oracle).
Оптимизатор может использовать режим обращения Predicate Offload только, если запрос использует Direct Read Full table scan и таблица расположена на дисковой группе, которая состоит из дисков Exadata. Обычно, Direct Read производится, используя Parallel Query. В Parallel Query один процесс выполняет роль координатора, другие (PQ slaves) выполняют собственно чтение. PQ slave, определяет фильтр и набор записей, который ему нужно прочитать. Если это возможно, вместо кода чтения direct path вызывается код взаимодействия с Exadata (речь идет о kernel code path). Этот код, с помощью ASM, переводит имена сегментов в диски, смещения, необходимый объем для чтения. Дальше открывается специальный поток, в котором эти данные передаются на Exadata. Если у нас несколько cell, это также легко определить с помощью метаданных ASM. Таким образом, правильный набор команд посылается нужному cell.
Процесс CELLSRV на стороне Exadata, получает поток команд на чтение и необходимый фильтр. Далее с помощью библиотеки из состава ядра Oracle он выполняет необходимую фильтрацию и возвращает результат. Результат — это только необходимые нам записи и колонки.
Ячейкам Exadata (cell) нет необходимости общаться между собой в момент выполнения запроса. Каждая ячейка получает нужную ей команду.
Поскольку речь идет о Direct Path Read, нет проблемы c read consistency. Перед началом Direct Path Read всегда выполняется tablespace checkpoint object-checkpoint, т.е. сброс грязных блоков этого объекта.
DW на основе Exadata полностью прозрачно для приложений и не требует никакой модификации SQL-инструкций. При поставках HP Oracle Database Machine каких-либо модификаций приложения в целом также не требуется. Exadata одинаково хорошо работает как с единственным образцом (single-instance) Oracle БД, так и с Oracle БД, развернутой на Real Application Clusters. Функциональные возможности и управление такими инструментами БД, как: Data Guard, Recovery Manager (RMAN), Streams и др. те же самые, как с Exadata, так и без нее.
Развернутое покомпонентное представление архитектуры HP Oracle Database Machine дано на рис. 7.
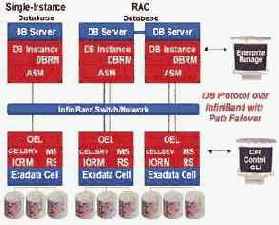
Рис. 7. Покомпонентное представление архитектуры HP Oracle Database Machine.
Сервер БД и Exadata Storage Server Software взаимодействуют, используя протокол iDB — Intelligent Database protocol. iDB реализован в ядре базы данных и прозрачно отображает операции базы данных к расширенным операциям Exadata. iDB используется, чтобы отправить SQL-операции к Exadata-ячейкам для выполнения и возвратить результат запроса к базе данных.
iDB построен на промышленном стандарте — Reliable Datagram Sockets (RDSv3) протоколе и работает на транспорте InfiniBand. ZDP (Zero-loss Zero-copy Datagram Protocol) и zero-copy имплементации RDS используются, чтобы устранить ненужное копирование блоков.
