Базы данных Oracle - статьи
Концепция Data mining
Data mining предлагает иной, "вверх дном" (bottom-up) подход. Data mining "просеивает" данные ("sifts" through the data), одну запись и одну переменную за один раз, раскрывая ранее скрытую информацию, которую, вы, наверное, раньше никогда не раскрывали, просто вследствие огромного количества данных. Разработаны масштабируемые инструменты data mining для решения этих сложных и больших, насыщенных данными и требующих большой вычислительной мощи проблем.
Давайте рассмотрим пример, чтобы понять как работает data mining.
Data mining просеивает данные, запись за записью и переменная за переменной. Разработан ряд методов, алгоритмов для data mining (или обучения машины - machine-learning) для поиска закономерностей (patterns) в данных, такие как нейронные сети (neural networks), деревья решений (decision trees) и алгоритмы кластеризации (clustering algorithms).
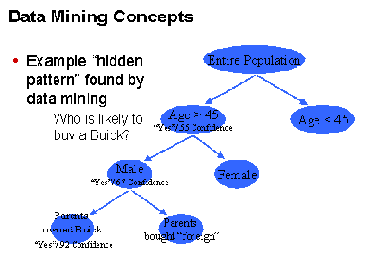
В этом случае мы используем алгоритм "дерево решений" для ответа на вопрос: "Кто, возможно, купит автомашину Buick?" При каждом расщеплении дерева клиенты делятся на две группы. В данном примере первое расщепление происходит на основе возраста и второе - на основе пола. Отметим, что по мере того как data mining "вкапывается" все глубже и глубже в данные, он создает все больше "отфильтрованных" (refined) сегментов однородных групп клиентов с похожим поведением.
Каждый конечный узел предоставляет "правило" ("rule"), которое описывает группу клиентов. Чем глубже вы спускаетесь по дереву, добавляя характеристики "правилу", тем выше уровень "уверенности" ("confidence") в точности предсказания. Например, правило нижнего левого узла дерева таково "Родители владеют автомобилем Buick, Мужчина, возраст более 45 лет" ("Parents owned Buick, Male, and Age is over 45") с уровнем уверенности 92%, что клиент с этим профилем купит Buick. Обладая такой информацией, компании могут взаимодействовать с клиентами индивидуализировано.
