в систему от различных источников,
Задания, поступающие в систему от различных источников, принимаются и обрабатываются специальным компонентом z/OS, который называется подсистемой управления заданиями JES (Job Entry Subsystem)1). JES принимает задания (рис. 5.19), поступающие с входных устройств, регистрирует их, осуществляет анализ и формирует очереди заданий, а затем передает задания на выполнение базовой управляющей программе BCP. После завершения выполнения задания и получения результатов от BCP, JES формирует отчет по заданию (листинг), передает его пользователю или выводит на указанные устройства. Чаще всего в установленных конфигурациях z/OS используется базовый компонент управления заданиями JES2, который и будет рассмотрен в данной главе. Альтернативой JES2 является опциональный компонент JES3, который в отличие от JES2 может использоваться для централизованного управления заданиями в многомашинной системе. Отметим, что JES2 работает в собственном адресном пространстве и имеет статус подсистемы (использует специальный SSI-интерфейс для взаимодействия с базовой управляющей программой z/OS). Кроме того, JES2 поддерживает собственные языковые средства, которые можно включать в текст задания (так называемые операторы JECL - Job Entry Control Language) и применять в виде консольных команд (системные команды JES2).
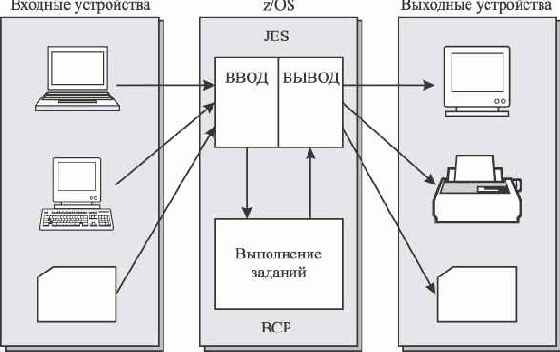
Рис. 5.19. Назначение подсистемы управления заданиями
На рис. 5.20 представлена схема, иллюстрирующая основные этапы обработки заданий после того, как они направлены в подсистему JES2 [13].
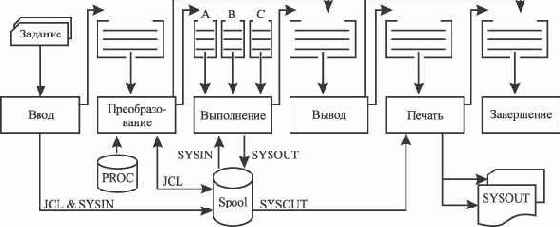
Рис. 5.20. Этапы обработки заданий
На этапе ввода (entry phase) осуществляется прием заданий, поступающих в систему от различных источников. Пользователь может задействовать для этих целей терминальные устройства, консоли, сетевые рабочие станции и т.п., применяя консольные команды START, MOUNT, команды TSO/E LOGON и SUBMIT. Существует возможность формировать и направлять задания на обработку из ранее запущенных программ и заданий. Поддерживается возможность удаленного RJE (Remote Job Entry) и сетевого NJE (Network Job Entry) ввода заданий, поступающих от узлов распределенной вычислительной сети.
JES2 контролирует все пути поступления заданий с помощью специальных встроенных программ ввода INTRDR (Internal Reader). Текст каждого поступившего задания (предложения JCL и JECL) и вложенные в него входные данные пользователя (обозначаемые как набор данных SYSIN) помещаются в специальный набор данных JES2, называемый "спул" (spool).
Спул используется для временного хранения данных, связанных с выполнением каждого поступившего в подсистему JES2 задания, и содержит:
JCL операторы задания и специальные операторы JES2 (JECL);исходные данные, представленные во входном потоке (набор данных SYSIN);выходные данные и сообщения, формируемые в процессе выполнения задания, и подготавливаемые для вывода в отчет (набор данных SYSOUT);управляющая информация JES2;сообщения для вывода в системный журнал SYSLOG.
На этапе ввода осуществляется регистрация задания, заключающаяся в присваивании заданию уникального идентификатора (JobID) и занесении учетной и статусной информации в специальный реестр JES2, получивший название очередь заданий (JOBQUEUE). Помимо идентификатора, JOBQUEUE содержит также значения класса, приоритета и текущего состояния задания. Фактически все множество очередей, представленных на рисунке, хранится в одной общей таблице JOBQUEUE. В этом случае выборка заданий производится по значению кода текущего состояния, показывающего, на каком этапе обработки задание находится в данный момент.
Все зарегистрированные задания поступают затем в очередь на следующий этап обработки.
На этапе преобразования (conversion phase) сначала производится анализ текста задания и трансляция его в специальный промежуточный код. Если обнаружены синтаксические ошибки, формируется отчет SYSOUT, включающий диагностические сообщения, и задание направляется на этап вывода, минуя стадию выполнения. В процессе анализа при необходимости происходит включение в текст задания и настройка параметров так называемых процедур JCL, вызываемых из внешних библиотек. Процедуры представляют собой готовые блоки предложений JCL, предназначенные для решения типовых пользовательских задач и хранящиеся в специальных наборах данных - библиотеках процедур (на рисунке обозначены как PROC).
JES2 располагает настраиваемым списком используемых стандартных библиотек процедур (самая известная среди них - SYS1.PROCLIB). Пользователь также имеет возможность указать собственный набор библиотек процедур с помощью оператора JCLLIB.
Если ошибки не обнаружены, промежуточный код задания помещается в спул, и задание передается в очередь на стадию выполнения. Следует отметить, что для каждого класса заданий формируется отдельная очередь. Внутри очереди задания упорядочены по приоритетам, назначаемым JES2 на основе установленной политики администрирования.
На этапе выполнения (execution phase) ключевую роль играют системные программы, получившие название инициаторов (initiators). Обычно запускается несколько инициаторов одновременно, так чтобы один инициатор обслуживал одну или несколько конкретных очередей заданий (по значениям класса). Каждый инициатор работает в собственном виртуальном адресном пространстве в соответствии со следующим алгоритмом:
инициатор формирует запрос к JES2 на получение нового задания из очередей обслуживаемых им классов;JES2 анализирует очередь заданий (JOBQUEUE) и передает инициатору сообщение о выбранном в соответствии с приоритетом задании;инициатор считывает из спула промежуточный код задания и входные данные (SYSIN), определяет, какие ресурсы необходимы для выполнения, и открывает соответствующие наборы данных, а также копирует в свое адресное пространство загрузочные модули вызываемых в задании программ;инициатор последовательно передает управление программам задания, контролируя ход их выполнения и поступающие сообщения; реальное управление выполнением программ реализуется базовой управляющей программой (BCP);при завершении задания (нормальном или аварийном) результаты работы программ передаются инициатором в набор данных SYSOUT спула, а задания поступают в очередь на стадию вывода.
Отметим, что в z/OS поддерживается два типа инициаторов: инициаторы JES и инициаторы WLM. Инициаторы JES2 обычно запускаются автоматически при инициализации системы в соответствии с настройками JES2 и назначаются на обслуживание определенных классов заданий.
Инициаторы WLM запускаются динамически в зависимости от текущей нагрузки системы и в соответствии с установленной политикой управления нагрузкой в целевом режиме.
Важно подчеркнуть, что для большинства заданий не создаются новые адресные пространства z/OS, поскольку их выполнение происходит в адресных пространствах инициаторов. Исключение составляют задания классов STC и TSU, которые не обрабатываются инициаторами. Для этих классов JES2 самостоятельно создает отдельные адресные пространства для каждого пользовательского сеанса TSO и каждой запускаемой процедуры, а также обрабатывает поступающие сообщения.
На этапе вывода (output phase) JES2 формирует отчет о выполнении задания в наборе данных SYSOUT в соответствии с требованиями и характеристиками назначенного выходного класса и указанными в задании атрибутами вывода. Выходной класс задания (всего доступно 36 классов, кодируемых символами A-Z или цифрами 0-9) определяется пользователем с помощью параметра SYSOUT оператора DD или оператора OUTPUT либо назначается подсистемой JES2 по умолчанию. Классы служат для группирования заданий с целью использования общих ограничений по выводу отчетов и для целей управления, но никак не связаны с используемыми для вывода устройствами. Подготовленные отчеты направляются в очередь на стадию печати или задерживаются на этапе вывода, если для задания установлен статус HOLD. Данный статус задается пользователем или устанавливается JES2 для некоторого класса или группы заданий. Дальнейшая обработка задержанных заданий производится по специальному указанию оператора (пользователя).
На этапе печати (hardcopy phase) производится вывод подготовленного отчета из набора данных SYSOUT на указанное пользователем или установленное JES2 выходное устройство (принтер, узел сети и т.п.), и задание передается в очередь на стадию завершения.
На этапе завершения (purge phase) JES2 осуществляет "очистку" спула и очереди заданий от информации, связанной с выполненным заданием, и формирует соответствующее сообщение.
Следует напомнить, что в z/OS существует специальный опциональный компонент SDSF, предназначенный для просмотра параметров текущего состояния всех запущенных в системе заданий и отчетов о выполнении, а также предоставляющий возможность изменять некоторые параметры и управлять ходом выполнения заданий динамически.
Оператор DD
Оператор описания данных DD (data definition) - это оператор определения данных и устройств, используемых в задании и его отдельных шагах. Операторы DD, относящиеся к определенному шагу задания, следуют за оператором EXEC этого шага задания. В одном шаге задания может быть описано не более 3273 операторов DD. Оператор DD может располагаться также за оператором JOB, если требуется описать наборы данных, общие для всего задания (например, библиотеки загрузочных модулей и др.).
Оператор DD может содержать один позиционный и около 60 ключевых параметров. Познакомимся с некоторыми наиболее важными из них, исключив из рассмотрения параметры, используемые для описания SMS и VSAM наборов данных.
Формат оператора DD:
//имя DD [позиционный параметр][,ключевые параметры] Позиционный параметр: * | DATA | DUMMY Ключевые параметры: [,DSN[AME] = имя_набора_данных] [,DCB = (список подпараметров)] [,UNIT = устройство] [,VOL[UME] =(список подпараметров)] [,SPACE = (список подпараметров)] [,DISP = (список подпараметров)] [,SYSOUT = (список подпараметров)] [,LABEL = (список подпараметров)] ...
Важнейшим атрибутом оператора DD является имя, связывающее описываемый набор данных с кодом вызываемой программы. Как отмечалось в п.5.1.3, в программе для каждого используемого набора данных с помощью макровызова DCB устанавливается так называемое dd-имя (ddname). Если в шаге задания указать оператор DD с таким же именем, то появляется возможность определить или изменить ряд параметров указанного набора данных через оператор DD задания, то есть в момент запуска программы. Таким образом, при выполнении любой программы пользователь должен в первую очередь выяснить, какие dd-имена следует применять для описания данных и устройств, необходимых для ее работы. Это можно сделать с помощью соответствующей документации и руководств. Например, для программы-компилятора языка ассемблера установлены следующие dd-имена:
SYSIN - для описания исходного модуля;
SYSPRINT - для вывода сообщений компилятора;
SYSLIN - для описания объектного модуля;
SYSUT1 - промежуточный набор данных.
Некоторые имена операторов DD зарезервированы системой для специальных целей. К ним относятся, например, следующие имена:
JOBLIB - для описания личной библиотеки загрузочных модулей, доступной заданию;
STEPLIB - для описания личной библиотеки загрузочных модулей, доступной для шага задания;
SYSABEND - для выходного набора данных, в который может быть записан дамп системного ядра и области памяти обрабатывающей программы, если шаг задания завершился аварийно;
SYSUDUMP - для выходного набора данных, в который может быть записан дамп области памяти обрабатывающей программы, если шаг задания завершился аварийно;
SYSCHK - для выходного набора данных контрольной точки;
SYSIN - для входного набора данных ввода заданий;
SYSPRINT - для набора данных, выводимого на печатающее устройство;
При использовании процедур могут применяться составные имена операторов DD, о чем речь пойдет немного ниже.
Только в одном случае у оператора DD может отсутствовать имя: при описании сцепленных наборов данных, рассматриваемых системой как единый набор данных:
//SCHETA DD ... // DD ... // DD ...
Система требует, чтобы у таких наборов данных были согласованы основные характеристики логических записей, такие как формат, длина и размер блока.
В языке управления заданиями имеется возможность определять значения некоторых параметров одного оператора DD посредством ссылки на значение этого же параметра другого оператора DD. В общем виде ссылку можно представить в следующих форматах:
*.имя_DD
или
*.имя_шага_задания.имя_DD
Первый формат используется при ссылке внутри шага задания, а второй формат применяется при ссылке на один из предшествующих шагов задания. Например:
//PR JOB SECT //ST1 EXEC PGM=SUN1 //UT1 DD DSNAME=LIB1,DCB=(RECFM=FB,LRECL=80,BLKSIZE=400) //UT2 DD DSNAME=LIB2,DCB=*.UT1 //ST2 EXEC PGM=SUN2 //GO DD DSNAME=LIB3,DCB=*.ST1.UT1
Теперь рассмотрим позиционный параметр оператора DD, который может принимать одно из трех взаимоисключающих значений:
* | DATA | DUMMY
Первое значение (*) служит для описания данных, размещаемых во входном потоке, то есть непосредственно в тексте задания вслед за оператором DD. Данные могут занимать одну или несколько строк задания и завершаться ограничительным оператором /*. В некоторых случаях ограничительный оператор может быть опущен. Признаком конца набора данных является в этом случае первый встретившийся управляющий оператор JCL с символами // в первых двух позициях строки.
Пример:
//SYSIN DD * 1 ИВАНОВ 12345 7.9 2 ПЕТРОВ 67890 3.8 3 СИДОРОВ 73452 9.0 /*
Если же входные данные включают управляющие операторы JCL, то есть строки, содержащие в первых двух позициях //, то необходимо вместо * использовать параметр DATA. В приведенном ниже примере в качестве входных данных определены две строки, содержащие предложения JOB и EXEC:
//MYJCL DD DATA //USER1A JOB ,BOB,MSGLEVEL=1 //ST1 EXEC IEFBR14 /*
Если во вводимых во входном потоке данных должны содержаться строки, начинающиеся с символов /*, то в этом случае можно определить другой ограничитель с помощью параметра DLM. В частности, при компиляции C/C++ приложений можно использовать этот прием следующим образом:
//PR JOB SECT //ST1 EXEC PGM=CCNDRVR //COMPILE DD *,DLM=<> # incude <stdio.h> /*комментарий*/ main(); ... <>
Здесь двухсимвольное значение <> в первых двух позициях строки служит для ограничения входного набора данных подобно /*.
Следует обратить внимание, что по умолчанию JES принимает для вводимого таким образом набора данных значения LRECL=BLKSIZE=80.
Значение позиционного параметра DUMMY применяется, чтобы объявить некоторый набор данных как фиктивный. В этом случае система не производит никаких действий над набором данных. Например, предложение
//SYSPRINT DD DUMMY
обеспечивает подавление вывода сообщений, направляемых программой в набор данных с dd-именем SYSPRINT.
//BIBL DD DSNAME=LIB1 //SYSIN DD DSN=D.USER1.DATA
Для указания раздела библиотеки в скобках записывают имя раздела:
//LOAD DD DSN=USERLIB(PROG1) //XXX DD DSN=MY.JCL(JOBTEST)
Перед именем временного набора данных записывают два знака амперсанда &&:
//SYSLIN DD DSN=&&LOADSET(GO) //SYSUT1 DD DSN=&&SYSUT1
Временные наборы данных автоматически уничтожаются системой после завершения шага задания. Отсутствие в операторе DD параметра DSNAME также означает, что набор данных временный. В этом случае имя набора данных будет сгенерировано автоматически, например, так:
SYSxxxxx.Txxxxxx.RA000.jobname.Rxxxxxx
где x - определенным образом сформированные цифры и символы.
В качестве значения параметра DSNAME можно указывать ссылки на другие операторы DD в формате *.имя_DD или *.имя_шага.имя_DD.
//STFG EXEC PGM=PROG1 //SYSUT1 DD DSN=DATA.IN ... //SYSLIN DD DSN=*.STFG.SYSUT1
Параметр DISP (диспозиция) определяет исходное состояние набора данных, а также действия, которые необходимо произвести с набором данных после завершения шага задания или всего задания: сохранить, уничтожить, каталогизировать и др. Формат записи параметра DISP включает три позиционных подпараметра:
DISP=([статус][,дисп_НЗ][,дисп_АЗ])
где статус - исходное (текущее) состояние набора данных, дисп_НЗ - действие при нормальном завершении шага задания, дисп_АЗ - действие, которое надлежит выполнить при аварийном завершении шага задания.
Подпараметр статус может принимать следующие значения:
NEW - в указанном шаге задания создается новый набор данных;
OLD - набор данных существует (создан ранее);
SHR - набор данных существует и может быть использован одновременно другим заданием, т.е. разделяется различными заданиями в режиме чтения;
MOD - набор данных существует и будет модифицироваться в указанном шаге задания (используется только для последовательных наборов данных).
Подпараметры диспозиции дисп_НЗ и дисп_АЗ могут принимать следующие значения:
DELETE - набор данных следует уничтожить;
KEEP - набор данных следует сохранить;
CATLG - набор данных следует сохранить и каталогизировать;
UNCATLG - набор данных нужно сохранить, но при этом исключить из системного каталога.
PASS - набор данных следует передать для использования в последующем шаге того же задания.
Последнее значение (PASS) может быть использовано только для подпараметра дисп_НЗ.
Примеры задания диспозиции:
DISP=(NEW,KEEP,DELETE) - набор данных создается и будет сохранен при нормальном завершении и удален при аварийном завершении шага задания;DISP=(SHR,KEEP,UNCATLG) - набор данных существует и будет сохранен при нормальном завершении и исключен из каталога при аварийном завершении шага задания.
Допускается не указывать некоторые или даже все подпараметры, учитывая следующие правила формирования их значений по умолчанию:
если не указан первый подпараметр (статус), то принимается значение NEW;если не указан второй подпараметр (дисп_НЗ), то принимается значение DELETE для нового и KEEP для существующего набора данных;если не указан третий подпараметр (дисп_АЗ), то принимается значение, заданное для второго подпараметра (дисп_НЗ);если не указан параметр DISP, то принимаются значения (NEW,DELETE,DELETE), то есть набор данных создается и уничтожается во время выполнения шага задания (временный).
Примеры:
DISP=(NEW,KEEP) и DISP=(,KEEP) соответствует DISP=(NEW,KEEP,KEEP) DISP=NEW и DISP=(NEW,,DELETE) соответствует DISP=(NEW,DELETE,DELETE) DISP=OLD соответствует DISP=(OLD,KEEP,KEEP) DISP=(OLD,,DELETE) соответствует DISP=(OLD,KEEP,DELETE) DISP=(SHR,,KEEP) соответствует DISP=(SHR,KEEP,KEEP)
Параметр UNIT назначает набору данных устройство ввода-вывода и определяется в большинстве случаев одним из трех значений (см. п. 5.1.3):
UNIT=адрес | типовое_имя | групповое_имя
Подпараметр адрес задает трех- или четырехразрядный физический адрес устройства (в шестнадцатеричном представлении). Подпараметр типовое_имя задает устройство по установленному производителем оборудования номеру модели, однозначно указывающему на тип устройства.
Подпараметр групповое_имя определяет устройство через логическое имя устройства или группы устройств, задаваемое системным программистом на этапе конфигурирования оборудования с помощью компонента HCD в таблице EDT. Ниже приведены примеры задания параметра UNIT различными способами:
//AD DD UNIT=220 - адрес устройства //TD DD UNIT=3390 - типовое имя //GD DD UNIT=SYSDA - групповое имя //GD DD UNIT=VIO - набор данных в виртуальной памяти
Параметр VOLUME (сокращенно VOL) указывает том или тома, на которых размещается набор данных. Рассмотрим наиболее употребительные варианты использования данного параметра.
В первом варианте том определяется посредством задания серийного имени тома в виде:
VOL=SER=имя[,имя]...
Например:
//DSETl DD DSN=YS,UNIT=SYSDA,VOL=SER=PTOM01
Здесь описан набор данных YS, находящийся на устройстве, принадлежащем к группе SYSDA с серийным номером тома PTOM01. Для многотомных наборов данных следует указывать список имен.
Во втором варианте том задается через ссылку, определяемую одним из трех способов:
VOL=REF=имя_набора_данных | *.имя_DD |.имя шага.имя_DD
В первом способе будет выбран том, на котором размещен ранее описанный в задании каталогизированный набор данных. Второй и третий способы используют стандартный формат ссылок. Рассмотрим пример:
//STEP1 EXEC PGM=.... //DD1 DD DSN=OLD.DATASET,DISP=SHR //DD2 DD DSN=DSET1,DISP=(,CATLG,DELETE),VOL=REF=*.DD1 //STEP2 EXEC PGM=... //DD3 DD DSN=DSET2,DISP=(,CATLG),VOL=REF=*.STEP1.DD1
Здесь создаваемые наборы данных DSET1 и DSET2 будут размещены на том же томе, что и существующий набор данных с именем OLD.DATASET.
Параметр DCB устанавливает характеристики логической организации набора данных, фиксируемые в блоке управления данными (Data Control Block), который создается системой для каждого набора данных. Блок управления данными представляет собой таблицу, которая после открытия заполняется информацией из описания набора данных в программе и дополняется данными из соответствующего оператора DD. Параметр DCB обычно имеет формат:
DCB=(список подпараметров)
Все подпараметры DCB являются ключевыми. Перечислим основные из них:
DSORG - тип организации набора данных;RECFM - формат записей;LRECL - длина логической записи;BLKSIZE - длина блока;BUFNO - число буферов ввода-вывода, выделяемых набору данных;BUFL - размер каждого буфера в байтах.
Подпараметр RECFM может принимать следующие значения: F - записи фиксированной длины; V - записи переменной длины; U - записи неопределенной длины. Выбор типа записи определяет пользователь. Если он группирует записи в блоки, то указывает это, добавляя к символу формата букву В. Например, указание RECFM=FB означает, что сблокированные записи имеют фиксированную длину.
Примеры:
Набор данных состоит из записей фиксированной длины по 128 байт, которые объединяются в блоки по четыре записи в каждом:
DCB=(RECFM=FB,LRECL=128,BLKSIZE=512) Набор данных содержит неблокированные записи фиксированной длины по 80 байт:
DCB=(BLKSIZE=80,RECFM=F)
Вместо ключевых подпараметров DCB можно записать ссылку на другой оператор DD, причем некоторые подпараметры можно переопределить заново:
//ST1 DD DSN=VAX,DCB=(RECFM=VB,LRECL=64,BLKSIZE=640) //PRINT DD DCB=(*.ST1,BLKSIZE=128)
Здесь подпараметры набора данных для параметра DCB копируются из оператора DD с именем ST1, кроме размера блока, который задается непосредственно.
Параметр SPACE задает требуемый объем памяти для размещения создаваемого набора данных на жестком диске, то есть набора данных с диспозицией NEW. Обычно этот параметр записывают в виде:
SPACE=(размер[,(количество[,приращение][,оглавление])][,RLSE])
Подпараметр количество указывает, сколько блоков памяти будет выделено набору данных первоначально, а подпараметр размер задает размер или тип одного блока и может принимать одно из следующих значений:
TRK - блок соответствует физической дорожке диска;
CYL - блок соответствует цилиндру диска;
число - определяет значение размера блока в байтах.
Так, параметр SPACE=(CYL,10) определяет область дисковой памяти размером 10 цилиндров, а параметр SPACE=(800,30) объявляет, что требуется память объемом в 30 блоков по 800 байт каждый.
Если указанный объем не может быть выделен (диск переполнен), система завершает шаг задания аварийно.
В том случае когда первоначального объема памяти недостаточно для размещения данных, система может выделить дополнительные блоки памяти, количество которых определяется подпараметром приращение. Установлено, что система может выделять дополнительные блоки не более 15 раз. Так, параметр SPACE=(CYL,(40,5)) запрашивает первоначально 40 цилиндров, а если этого объема памяти будет недостаточно, то система будет выделять по пять цилиндров до 15 раз, т. е. при необходимости всего будет выделено 40+5*15=115 цилиндров. Если приращение не указано, то дополнительные блоки не выделяются.
Параметр оглавление задается только для наборов данных с библиотечной организацией. Он определяет необходимое количество блоков, отводимых под оглавление библиотечного набора данных. Один блок оглавления содержит 256 байт. Так, например, параметр SPACE=(TRK,(100,10,5)) запрашивает память в 100 дорожек и по 10 дополнительных дорожек (до 15 раз), а также пять блоков по 256 байт оглавления библиотечного набора данных. Отсутствие подпараметра оглавление обычно косвенно указывает на набор данных с последовательной организацией.
Очевидно, что не всегда удается точно предсказать требуемый для набора данных объем внешней памяти. Подпараметр RLSE служит для освобождения памяти, выделенной, но не использованной под размещение данных. Освобождение свободной памяти производится при закрытии набора данных. Так, параметр SPACE=(TRK,(40,,8),RLSE) указывает, что запрашивается 40 дорожек без приращения. Для оглавления выделяется восемь блоков. Незанятая память после закрытия набора данных освобождается.
Параметр LABEL чаще всего используется для описания набора данных на магнитной ленте. В нем могут быть указаны порядковый номер набора данных на МЛ, тип метки, срок хранения набора данных, пароль. Наиболее употребительный формат параметра:
LABEL=([номер][,формат][PASSWORD][,IN|,OUT])
Подпараметр номер задает последовательный номер набора данных на ленточном томе.
Значения 0 или 1 указывают на первый по порядку набор данных. Для каталогизированных наборов данных, а также наборов данных, передаваемых из предыдущего шага задания (DISP=,PASS) , номер можно не указывать.
Подпараметр формат указывает используемый стандарт форматирования ленточного тома (тип меток наборов данных). Возможны следующие значения формата:
SL - стандартный формат IBM (используется по умолчанию, можно не указывать);
SUL - указывает, где набор данных имеет стандартные метки и метки пользователя;
AL - используется формат ISO/ANSI;
NSL - набор данных имеет нестандартные метки;
NL - набор данных не имеет меток;
BLP - необходимо обойти обработку метки набора данных.
Подпараметр, задаваемый ключевым словом PASSWORD, требует при изменении набора данных, чтобы пользователь ввел правильный пароль, используя консоль или терминал TSO.
Ключевые слова IN и OUT указывают, что набор данных обрабатывается для ввода или вывода соответственно.
В приводимом ниже примере открывается для чтения 5-й набор данных, имеющий нестандартные метки, на ленточном томе TAPE01:
//DD1 DD DSNAME=NAB1,UNIT=TAPE01, // VOL=SER=MT1,LABEL=(5,NSL,,IN)
Параметр SYSOUT идентифицирует набор данных как системный выходной набор данных. Наиболее употребительная форма для записи параметра:
SYSOUT=(выходной_класс[,имя_прог])
Чаще всего подпараметр выходной_класс определяет имя выходного класса для описываемого набора данных в виде символа А-Z или 0-9. Атрибуты выходных классов определяются при настройке JES. Если в качестве значения выходного класса указана звездочка (*), это означает, что следует использовать то же значение, что у параметра MSGCLASS, определенное в операторе JOB. Символ "запятая" (,) в позиции данного подпараметра задает так называемый "пустой" класс, означающий, что основные атрибуты вывода будут определены в операторе задания OUTPUT, ссылка на который должна быть указана далее с помощью параметра OUTPUT.
Подпараметр имя_прог позволяет указать имя программы (загрузочного модуля), обрабатывающей выходной набор данных.
Если подпараметр не указан, JES будет обрабатывать выходной набор данных стандартным способом, определенным для соответствующего класса.
Кроме указанных подпараметров, параметр SYSOUT может использовать подпараметры, управляющие форматированием выходного набора данных при выводе на печать (выбор шрифта, межстрочный интервал, размеры полей, количество копий и т.п.)
Примеры использования параметра SYSOUT:
определение выходного класса B:
//SYSPRINT DD SYSOUT=B определение выходного класса по значению MSGCLASS:
//YSl JOB ,,MSGCLASS=A //ST1 EXEC PGM=ZARPLATA //DD1 DD SYSOUT=* определение пустого выходного класса и ссылки на оператор OUTPUT:
//OUT1 OUTPUT BURST=Y,CHARS=(GT12),COPIES=3 ... //DS DD SYSOUT=(,),OUTPUT=*.OUT1 обработка выходного набора данных программой ввода заданий INTRDR:
//SYSUT2 DD SYSOUT=(X,INTRDR)
Итак, мы рассмотрели небольшую часть из общего числа параметров оператора DD, однако наиболее важную с точки зрения практического использования. Рассмотрим ряд примеров описания наборов данных при решении некоторых типовых задач [15].
Описание каталогизированных наборов данных на DASD. В этом случае достаточно указать только параметры DSN и DISP, поскольку остальную необходимую информацию о размещении набора данных система получит из каталога, например:
//CATDS1 DD DSN=AS30.MY.DSET,DISP=OLD //CATDS2 DD DSN=LIB.DATA(CHAR),DISP=SHR Описание некаталогизированных наборов данных на DASD. Здесь требуется указывать дополнительно значения параметров UNIT и VOLUME, например:
//NOCATDS DD DSNAME=AS30.MY.DSET,DISP=OLD, // VOL=SER=D01457,UNIT=3390 Описание нового non-SMS набора данных на жестких магнитных дисках. Требуется задавать параметры DCB и SPACE. В приводимом ниже примере создается библиотечный набор данных со 120-байтными записями фиксированной длины на выделенном пространстве внешней памяти размером 10 цилиндров с приращением в три цилиндра. На оглавление отводится два блока по 256 байт, при завершении шага задания неиспользуемая память будет освобождена, а набор данных сохранен.
//NEWDS DD DSNAME=D.AS32.DATA,DISP=(NEW,KEEP), // VOL=SER=BIBLIO,UNIT=3380, // DCB=(RECFM=F,LRECL=120), // SPACE=(CYL,(10,3,2),RLSE)
Оператор EXEC
Оператор выполнения EXEC (его также называют оператором шага задания) служит для указания программы или процедуры JCL, которую необходимо выполнить, а также для установления параметров выполнения шага. В задании должен присутствовать как минимум один оператор EXEC, но их может быть и несколько.
Формат оператора EXEC:
//[имя_шага_задания] EXEC позиционный параметр [,ключевые параметры]
Позиционный параметр:
PGM = имя_программы | *.имя_шага.имя_DD [PROC=]имя_процедуры Ключевые параметры: [,PARM = (значение, значение,...)] [,REGION = nК | nM] [,ТIМЕ = (мин,сек)] [,COND=((код_завершения,условие[,имя_шага]),...,[EVEN|ONLY])] ...
Напомним: как и ранее, квадратные скобки означают, что параметр необязателен. Таким образом, единственным обязательным параметром оператора EXEC является позиционный параметр, задающий выполняемую программу (через ключевое слово PGM) или процедуру (через ключевое слово PROC или без него), остальные параметры необязательны. Необязательно и имя шага задания, однако при его отсутствии могут возникнуть трудности анализа сообщений системы (неясно, к какому шагу задания они относятся), а также невозможно будет сделать ссылку на данный шаг задания.
Параметр PGM определяет программу, которая должна быть выполнена в данном шаге задания. Например:
//EXEPRIM1 EXEC PGM=MYPROG
Вызываемая программа задается по имени раздела библиотечного набора данных, содержащего соответствующий загрузочный модуль. z/OS устанавливает определенный порядок поиска загрузочных модулей. По умолчанию поиск ведется в системных библиотеках загрузочных модулей, список которых определен в разделе LNKLST реестра SYS1.PARMLIB. Первой в этом списке обычно стоит библиотека SYS1.LINKLIB. В системных библиотеках находятся наиболее часто используемые программы общего назначения. Однако можно настроить задание на выборку загрузочных модулей из личных библиотек - библиотечных наборов данных, в которых хранятся программы пользователей. Личные библиотеки должны быть явно описаны в задании с помощью операторов DD с зарезервированными для этой цели именами JOBLIB или STEPLIB.
Рассмотрим пример:
//JOBA1 JOB (A21,DEP3,007),,CLASS=C //JOBLIB DD DSN=USERLIB1,DISP=SHR //STEP1 EXEC PGM=PRG1 //STEP2 EXEC PGM=PGM2 //STEPLIB DD DSN=USERLIB2,DISP=SHR
В задании определены две личные библиотеки: библиотека задания USERLIB1, описанная с помощью оператора DD с именем JOBLIB, и библиотека шага задания USERLIB2, описанная с помощью оператора DD с именем STEPLIB. В этом случае поиск программы PRG1 будет производиться в следующем порядке: USERLIB1, библиотеки списка LNKLST, а поиск программы PRG2 - сначала USERLIB2 (так как именно в этом шаге описана данная библиотека), затем USERLIB1 и, наконец, библиотеки LNKLST.
Если позиционный параметр описан как PGM=*.имя_шага.имя_DD, то программа вызывается из библиотеки загрузочных модулей, описанной в одном из предыдущих шагов задания. Здесь имя_DD - это имя оператора DD, в котором описывается библиотека загрузочных модулей, имя_шага указывает шаг задания, в котором находится упомянутый оператор DD. В приведенном ниже примере в шаге ST2 будет выполнена программа, загрузочный модуль которой хранится в разделе CALC библиотеки MYLIB, как указывает ссылка *.ST1.DSPROG:
//ST1 EXEC PGM=MYPROG //DSPROG DD DSNAME=MYLIB(CALC),DISP=SHR //ST2 EXEC PGM=*.ST1.DSPROG
Второй формат позиционного параметра оператора EXEC с использованием ключевого слова PROC или без него служит для выполнения процедуры в шаге задания. Процедура представляет собой последовательность операторов JCL, оформленных как автономная JCL-программа. Процедура может храниться в системной или пользовательской библиотеке процедур либо описывается непосредственно в задании. Список используемых системных библиотек процедур определяется системным программистом в настройках JES. Особенности использования и вызова процедур будут описаны ниже.
Рассмотрим ключевые параметры оператора EXEC при вызове программ (загрузочных модулей). При вызове процедур формат параметров несколько меняется, о чем будет сказано дополнительно.
Параметр PARM служит для передачи программе, выполняемой в шаге задания, определенной управляющей информации или исходных данных.
Эта информация передается в виде текстовой строки длиной не более 100 символов, которая обычно включает ряд значений (подпараметров), разделенных запятыми. Если через PARM передается список значений, то весь список должен заключаться в апострофы или круглые скобки. Приведем примеры различных вариантов определения параметра PARM:
передача одного параметра:
//STEP1 EXEC PGM=PR1,PARM=12 //STEP2 EXEC PGM=PR1,PARM=LOAD передача двух параметров:
//STEP3 EXEC PGM=PR1,PARM=(LIST,NODECK) //STEP4 EXEC PGM=LOADER,PARM ='MAP,SIZE=150K' //PR1 EXEC PROC=РЕЗ,PARM='2000,YES'
Подпараметры, содержащие специальные знаки (например, русский текст, знак + и т. п.), следует заключать в апострофы или круглые скобки. Если апостроф встречается в подпараметре, то он повторяется дважды, например PARM = 'О''К!'. Информация, заключенная в апострофы, должна умещаться на одной строке, а заключенная в скобки может быть перенесена на другую строку.
Параметры REGION и TIME аналогичны параметрам оператора JOB с той лишь разницей, что в EXEC они определяют размер области виртуальной памяти и время выполнения для шага задания. Параметр TIME оператора JOB имеет преимущество перед параметром TIME оператора EXEC: если время, указанное параметром TIME оператора EXEC, превосходит время, установленное параметром TIME оператора JOB, то значение параметра TIME оператора EXEC игнорируется. Параметр REGION в операторе EXEC также игнорируется, если задан параметр REGION в операторе JOB. Примеры:
//SI EXEC PGM=A,REGION=40K //INT1 EXEC PGM=PR1,TIME=5 //INT2 EXEC PGM=PR1,TIME=(,45)
Параметр COND определяет условия для обхода шага задания. Он указывает, что возможность выполнения шага задания зависит от полученных значений кодов завершения на предшествующих шагах задания. Синтаксис параметра COND несколько отличается от аналогичного параметра оператора JOB:
COND = ((код_завершения,условие[,имя_шага])... [,EVEN|,ONLY])
Здесь наряду с подпараметрами код_завершения и условие, можно указывать имя одного из предыдущих шагов задания, по коду завершения которого будет вестись проверка (имя_шага).
Если имя_шага не указано, условие будет проверяться для всех предыдущих шагов. Подпараметры EVEN и ONLY следует использовать, когда выполнение текущего шага требуется поставить в зависимость от наличия в задании аварийно завершенных шагов (для таких шагов код завершения не сформирован). Подпараметр EVEN требует выполнять текущий шаг, даже если один из предыдущих шагов завершился аварийно, ONLY - только если один из предыдущих шагов завершился аварийно.
Параметр COND может содержать до восьми условий, включая EVEN и ONLY. Шаг задания не будет выполнен, если соблюдается хотя бы одно из заданных условий. Рассмотрим ряд примеров:
шаг ST3 не выполняется, если 8 > RC шага ST1:
//ST3 EXEC PGM=PROG3,COND=(8,GT,ST1) шаг ST6 не выполняется, если 8

//ST6 EXEC PGM=AP,COND=((8,LE,ST1),(8,LE,ST2)) шаг ST9 не выполняется, если 16

RC шага ST2, или ни один из предыдущих шагов не завершился аварийно:
//ST9 EXEC PGM=AP,COND=((16,GE),(90,LE,ST2),ONLY) шаг ST7 не выполняется, если 10
//ST7 EXEC PGM=AP,COND=((9,LT,ST5),EVEN)
Оператор JOB
Оператор задания JOB всегда располагается в начале задания и служит для определения основных пользовательских атрибутов задания, таких как класс, приоритет, время выполнения и др. Последовательность символов, указанная в поле имени предложения JOB, рассматривается как имя задания и должна присутствовать в обязательном порядке. Кроме того, в операторе JOB может быть определена учетная информация, параметры безопасности и производительности и некоторые другие.
Формат оператора JOB:
//имя JOB параметры Позиционные параметры: [(учетная информация)][,идентификатор программиста] Ключевые параметры: [,MSGLEVEL = (предложения,сообщения)] [,CLASS = класс задания] [,MSGCLASS = класс сообщений] [,REGION = nK | nM] [,ТIМЕ = (минуты, секунды)] [,COND=((код_завершения,условие)[,(код_завершения,условие)])
Из общего количества ключевых параметров приведены только пять наиболее употребительных.
Учетная информация (до 142 символов) содержит сведения, используемые учетными программами ОС, с помощью которых подсчитываются используемое заданием машинное время и другие ресурсы. Если учетная информация задается списком значений, то этот список должен быть заключен в апострофы или круглые скобки.
Идентификатор программиста (до 20 символов) служит для идентификации пользователя, подготовившего задание. В качестве идентификатора можно указать фамилию и имя (инициалы) автора задания, номер отдела, в котором он работает, шифр темы, название организации и т.п. Если в идентификаторе используются русские буквы или пробелы, то его следует заключать в апострофы.
Варианты записи учетной информации и идентификатора программиста могут выглядеть так:
//PR1 JOB 5,'ИВАНОВ И.Л.' //PR2 JOB (5,А1),'ПЕТРОВ В.А.' //PR3 JOB 'T801,378',BOB //PR4 JOB ,'сидоров' //PR5 JOB 840,PETROV //PR6 JOB ,'KOBZON I.D.'
Параметр MSGLEVEL (уровень полноты сообщений) определяет, какую информацию необходимо выдать в отчет о выполнении задания, и имеет следующий формат:
MSGLEVEL=(a,b)
Подпараметр a может принимать три значения: 0, 1 и 2.
Если программист указал цифру 0, то в отчет выводится только оператор JOB. Значение 2 указывает, что требуется вывод всех операторов задания и операторов JECL, а цифра 1 определяет, что нужно выводить не только все операторы задания, но и операторы вызываемых процедур после замены в них символических параметров фактическими значениями.
Подпараметр b может принимать два значения: 0 и 1. Значение 1 предписывает всегда выводить в отчет связанные с выполнением задания сообщения, инициируемые оператором, интерпретатором JCL, JES и подсистемой управления данными DFSMS. Значение 0 указывает, что в отчет будут включены только сообщения интерпретатора JCL. Если параметр MSGLEVEL опущен, то по умолчанию принимаются значения, установленные в настройках JES. Примеры:
//GOD JOB ,,MSGLEVEL=(1,1) //ST JOB I,STUPIN,MSGLEVEL=2 //ST JOB ,JOHN,MSGLEVEL=(,1)
Во втором примере подпараметр b, а в третьем - подпараметр a будут установлены по умолчанию.
Параметр CLASS (класс) относит задание к определенному классу выполнения заданий и задается символами A-Z, 0-9. Если класс не указан, то принимается значение, установленное в настройках JES в зависимости от источника задания.
Пример:
//U01A JOB 21,TOMA,CLASS=В
Параметр MSGCLASS (класс сообщений) определяет выходной класс для системных сообщений, формируемых в процессе выполнения задания. Класс задается символами A-Z, 0-9. Параметр MSGCLASS дает возможность выводить все системные сообщения и выходные наборы данных, формируемые в шагах задания, в один и тот же класс или в разные классы. Такое разделение иногда может оказаться полезным.
Пример. Предусмотреть вывод всех управляющих операторов задания и сообщений отдельно от выходных наборов данных:
//U JOB (5.1),'ПЕТР',MSGLEVEL=(1,1),CLASS=B,MSGCLASS=С //STl EXEC PGM=PRINT //OUT DD SYSOUT=A
Здесь для выполнения задания предусмотрен класс В, для вывода результатов шага задания (параметр SYSOUT оператора DD) - класс А, а для вывода системных сообщений - класс С.
Параметр REGION (область) задает максимальный размер области виртуальной памяти в пользовательском регионе, которую необходимо выделить для выполнения каждого шага задания.
Параметр REGION задается в виде:
REGION=nК | nМ
где n - целочисленное значение, определяющее число килобайт (K) или мегабайт (M) виртуальной памяти. Например, если указать REGION = 900К, то шагам задания будет отводиться по 900 килобайт. Максимальное значение параметра в килобайтах - 2 096 128, в мегабайтах - 2047. Значение 0К или 0М означает, что задание требует в свое распоряжение всю приватную часть виртуального адресного пространства. Если параметр REGION в операторе JOB опущен, то используется значение, указанное в операторах EXEC. Если и в этих операторах он не задан, то принимается стандартное значение, заданное в настройках JES. Отметим, что с помощью параметра ADDRSPC, указываемого дополнительно, можно потребовать выделить для задания с помощью параметра REGION область реальной памяти (ADDRSPC=REAL).
Параметр TIME (время) устанавливает максимальную продолжительность выполнения задания и имеет формат:
ТIМЕ=(мин,сек)|мин|1440|NOLIMIT
Время указывается в минутах и секундах либо только в минутах. Если секунды не указаны, можно не использовать скобки. Например, запись TIME = 30 означает, что заданию требуется выделить 30 минут процессорного времени. Число минут может быть не более 1440 (т.е. 24 часа), а секунд - не более 60. Если по истечении времени, указанного в TIME, задание не завершило работы, то система либо принудительно завершает задание, либо использует средства специальной обработки "просроченных" заданий. По умолчанию, когда параметр TIME не задан, ограничение на выполнение задания определяется настройками JES. Если в параметре TIME указать число 1440 или слово NOLIMIT, то время выполнения задания считается неограниченным.
Варианты описания времени выполнения задания:
//PRIMER1 JOB ,,TIME=10 //PRIMER2 JOB ,,TIME =(10,30) //PRIMER3 JOB ,,TIME =(,30)
Задание PRIMER1 выполняется не более 10 мин, задание PRIMER2 - не более 10 мин и 30 с, а задание PRIMER3 - 30 с.
Параметр COND (от condition - условие) задает условия, при которых следует прекратить выполнение задания, если полученный на каком-либо шаге результат не устраивает пользователя.
Для управления выполнением шагов задания используют коды завершения. Код завершения или код возврата (RC от Return Code) формируется выполняемой в шаге задания программой и может характеризовать "успешность" выполнения программы в зависимости от полученного результата. Например, для многих системных программ z/OS принято использовать следующие значения кодов завершения:
0 - при обработке программы ошибок не обнаружено (успешное выполнение);
4 - обнаружены несущественные ошибки, выдается предупреждающее сообщение, но выполнение программы было продолжено;
8 - обнаружены ошибки, которые могут привести к невозможности выполнения задания (выдается сообщение об ошибках);
12 - обнаружены серьезные ошибки, дальнейшая обработка программы невозможна (выдается сообщение о серьезной ошибке);
16 - обнаружены ошибки, которые делают невозможным выполнение программы (выполнение программы прекращается).
Используется следующий формат записи параметра COND:
COND=((код_завершения,условие)[,(код_завершения,условие)_])
Допустимое значение подпараметра код_завершения указывается в виде целого числа в диапазоне от 0 до 4095. Подпараметр условие задает условие проверки кода завершения мнемоническим отношением вида: GT - больше, чем, GE - больше или равно, EQ - равно, LT - меньше, чем, LE - меньше или равно, NE - не равно.
Если заданное отношение к коду возврата, выработанному программой, которая вызывается оператором EXEC, не соблюдается, то выполнение задания прекращается. Внешние скобки можно опустить, если задано только одно условие. Условие, задаваемое параметром COND, проверяется перед выполнением каждого шага задания следующим образом: если код возврата, полученный на одном из предыдущих шагов, соответствует условию, то выполнение задания прекращается. Например, запись COND=(0,NE) предписывает прекратить выполнение задания, если окажется, что код завершения одного из шагов не равен нулю. В записи COND=(4,LT) указано, что если 4 меньше полученного кода завершения, то шаги задания не выполняются.Условие COND=((50,GE),(70,LE)) предписывает, что если 50 больше или равно коду возврата или 70 меньше или равно коду возврата, то оставшиеся шаги задания не выполняются. Таким образом, здесь задание будет выполняться до тех пор, пока код возврата находится в диапазоне от 51 до 69.
Если параметр COND опущен, то проверка кода возврата не производится.
Параметр SPACE
Параметр SPACE задает требуемый объем памяти для размещения создаваемого набора данных на жестком диске, то есть набора данных с диспозицией NEW. Обычно этот параметр записывают в виде:
SPACE=(размер[,(количество[,приращение][,оглавление])][,RLSE])
Подпараметр количество указывает, сколько блоков памяти будет выделено набору данных первоначально, а подпараметр размер задает размер или тип одного блока и может принимать одно из следующих значений:
TRK - блок соответствует физической дорожке диска;
CYL - блок соответствует цилиндру диска;
число - определяет значение размера блока в байтах.
Так, параметр SPACE=(CYL,10) определяет область дисковой памяти размером 10 цилиндров, а параметр SPACE=(800,30) объявляет, что требуется память объемом в 30 блоков по 800 байт каждый. Если указанный объем не может быть выделен (диск переполнен), система завершает шаг задания аварийно.
В том случае когда первоначального объема памяти недостаточно для размещения данных, система может выделить дополнительные блоки памяти, количество которых определяется подпараметром приращение. Установлено, что система может выделять дополнительные блоки не более 15 раз. Так, параметр SPACE=(CYL,(40,5)) запрашивает первоначально 40 цилиндров, а если этого объема памяти будет недостаточно, то система будет выделять по пять цилиндров до 15 раз, т. е. при необходимости всего будет выделено 40+5*15=115 цилиндров. Если приращение не указано, то дополнительные блоки не выделяются.
Параметр оглавление задается только для наборов данных с библиотечной организацией. Он определяет необходимое количество блоков, отводимых под оглавление библиотечного набора данных. Один блок оглавления содержит 256 байт. Так, например, параметр SPACE=(TRK,(100,10,5)) запрашивает память в 100 дорожек и по 10 дополнительных дорожек (до 15 раз), а также пять блоков по 256 байт оглавления библиотечного набора данных. Отсутствие подпараметра оглавление обычно косвенно указывает на набор данных с последовательной организацией.
Очевидно, что не всегда удается точно предсказать требуемый для набора данных объем внешней памяти.
Подпараметр RLSE служит для освобождения памяти, выделенной, но не использованной под размещение данных. Освобождение свободной памяти производится при закрытии набора данных. Так, параметр SPACE=(TRK,(40,,8),RLSE) указывает, что запрашивается 40 дорожек без приращения. Для оглавления выделяется восемь блоков. Незанятая память после закрытия набора данных освобождается.
Параметр LABEL чаще всего используется для описания набора данных на магнитной ленте. В нем могут быть указаны порядковый номер набора данных на МЛ, тип метки, срок хранения набора данных, пароль. Наиболее употребительный формат параметра:
LABEL=([номер][,формат][PASSWORD][,IN|,OUT])
Подпараметр номер задает последовательный номер набора данных на ленточном томе. Значения 0 или 1 указывают на первый по порядку набор данных. Для каталогизированных наборов данных, а также наборов данных, передаваемых из предыдущего шага задания (DISP=,PASS) , номер можно не указывать.
Подпараметр формат указывает используемый стандарт форматирования ленточного тома (тип меток наборов данных). Возможны следующие значения формата:
SL - стандартный формат IBM (используется по умолчанию, можно не указывать);
SUL - указывает, где набор данных имеет стандартные метки и метки пользователя;
AL - используется формат ISO/ANSI;
NSL - набор данных имеет нестандартные метки;
NL - набор данных не имеет меток;
BLP - необходимо обойти обработку метки набора данных.
Подпараметр, задаваемый ключевым словом PASSWORD, требует при изменении набора данных, чтобы пользователь ввел правильный пароль, используя консоль или терминал TSO.
Ключевые слова IN и OUT указывают, что набор данных обрабатывается для ввода или вывода соответственно.
В приводимом ниже примере открывается для чтения 5-й набор данных, имеющий нестандартные метки, на ленточном томе TAPE01:
//DD1 DD DSNAME=NAB1,UNIT=TAPE01, // VOL=SER=MT1,LABEL=(5,NSL,,IN)
Параметр SYSOUT идентифицирует набор данных как системный выходной набор данных. Наиболее употребительная форма для записи параметра:
SYSOUT=(выходной_класс[,имя_прог])
Чаще всего подпараметр выходной_класс определяет имя выходного класса для описываемого набора данных в виде символа А-Z или 0-9. Атрибуты выходных классов определяются при настройке JES. Если в качестве значения выходного класса указана звездочка (*), это означает, что следует использовать то же значение, что у параметра MSGCLASS, определенное в операторе JOB. Символ "запятая" (,) в позиции данного подпараметра задает так называемый "пустой" класс, означающий, что основные атрибуты вывода будут определены в операторе задания OUTPUT, ссылка на который должна быть указана далее с помощью параметра OUTPUT.
Подпараметр имя_прог позволяет указать имя программы (загрузочного модуля), обрабатывающей выходной набор данных. Если подпараметр не указан, JES будет обрабатывать выходной набор данных стандартным способом, определенным для соответствующего класса.
Кроме указанных подпараметров, параметр SYSOUT может использовать подпараметры, управляющие форматированием выходного набора данных при выводе на печать (выбор шрифта, межстрочный интервал, размеры полей, количество копий и т.п.)
Примеры использования параметра SYSOUT:
определение выходного класса B:
//SYSPRINT DD SYSOUT=B определение выходного класса по значению MSGCLASS:
//YSl JOB ,,MSGCLASS=A //ST1 EXEC PGM=ZARPLATA //DD1 DD SYSOUT=* определение пустого выходного класса и ссылки на оператор OUTPUT:
//OUT1 OUTPUT BURST=Y,CHARS=(GT12),COPIES=3 ... //DS DD SYSOUT=(,),OUTPUT=*.OUT1 обработка выходного набора данных программой ввода заданий INTRDR:
//SYSUT2 DD SYSOUT=(X,INTRDR)
Итак, мы рассмотрели небольшую часть из общего числа параметров оператора DD, однако наиболее важную с точки зрения практического использования. Рассмотрим ряд примеров описания наборов данных при решении некоторых типовых задач [15].
Описание каталогизированных наборов данных на DASD. В этом случае достаточно указать только параметры DSN и DISP, поскольку остальную необходимую информацию о размещении набора данных система получит из каталога, например:
//CATDS1 DD DSN=AS30.MY.DSET,DISP=OLD //CATDS2 DD DSN=LIB.DATA(CHAR),DISP=SHR Описание некаталогизированных наборов данных на DASD. Здесь требуется указывать дополнительно значения параметров UNIT и VOLUME, например:
//NOCATDS DD DSNAME=AS30.MY.DSET,DISP=OLD, // VOL=SER=D01457,UNIT=3390 Описание нового non-SMS набора данных на жестких магнитных дисках. Требуется задавать параметры DCB и SPACE. В приводимом ниже примере создается библиотечный набор данных со 120-байтными записями фиксированной длины на выделенном пространстве внешней памяти размером 10 цилиндров с приращением в три цилиндра. На оглавление отводится два блока по 256 байт, при завершении шага задания неиспользуемая память будет освобождена, а набор данных сохранен.
//NEWDS DD DSNAME=D.AS32.DATA,DISP=(NEW,KEEP), // VOL=SER=BIBLIO,UNIT=3380, // DCB=(RECFM=F,LRECL=120), // SPACE=(CYL,(10,3,2),RLSE)
Понятие задания
В п. 5.1.1 мы определили задание (job) как внешнюю единицу работы z/OS. Это означает, что пользователь может запросить у системы выполнение какой-либо работы (конечно, связанной с запуском определенных приложений) с помощью специальным образом записанного и переданного системе текста. Это и есть задание. Задания составляются на языке управления заданиями JCL (Job Control Language) и направляются в систему пользователями через входные устройства и сетевые коммуникации, а также через ранее запущенные приложения. В задании зашифровано, какие программы, в какой последовательности и с какими данными должны быть исполнены, а также в какой форме и куда должны быть направлены результаты выполнения программ.
Все множество заданий в z/OS может быть представлено в виде трех групп:
пакетные задания (batch job), формируемые пользователями на языке JCL и направляемые на обработку по команде сеанса TSO SUBMIT или через сетевые интерфейсы.STC-задания, инициируемые с помощью консольных команд START и MOUNT и получившие название запускаемые процедуры (started task);TSU-задания, формируемые в результате запуска пользовательских сеансов TSO/E по команде LOGON и предназначенные для поддержки диалога с пользователем.
Задания, поступающие в систему от различных источников, образуют поток заданий, обрабатываемый специальным системным компонентом JES.
При выполнении STC и TSU заданий z/OS создает отдельные адресные пространства для каждой запускаемой процедуры и каждого пользовательского сеанса TSO. Для пакетных заданий новые адресные пространства не создаются, поскольку их выполнение производится в системных адресных пространствах программ-инициаторов, входящих в состав JES.
Каждое задание характеризуется набором атрибутов, среди которых необходимо выделить:
имя (jobname);идентификатор (jobID);класс выполнения или просто класс (class);приоритет (prty).
Имя задания - имя, присваиваемое заданию пользователем (для пакетных заданий) или формируемое автоматически (для STC/TSU-заданий). Идентификатор задания - уникальный код (номер) задания, устанавливаемый системой при вводе задания.
Именно по идентификатору система отличает одно задание от другого.
Класс задания устанавливает принадлежность задания к определенной группе в зависимости от формы запуска, атрибутов пользователя и требований к ресурсам. В z/OS поддерживается два специальных класса для STC и TSU заданий и до 36 классов для пакетных заданий. Классы пакетных заданий обозначаются символами A, B, ..., Z и цифрами 0, 1, ..., 9 и могут назначаться по усмотрению пользователей с помощью JCL. Если пользователь не указал класс, система сформирует его в соответствии с настройками по умолчанию.
Приоритет задания (число в диапазоне 0-15) служит для определения очередности выполнения заданий. Обычно приоритет устанавливается системой автоматически на основе текущих атрибутов задания и может динамически изменяться в зависимости от времени ожидания в очереди. Наивысшему приоритету соответствует значение 15.
С каждым заданием система ассоциирует два специальных набора данных: SYSIN и SYSOUT. Входной набор данных SYSIN отражает исходные данные, используемые приложениями задания. Эти данные могут быть представлены непосредственно в тексте задания (в этом случае говорят, что исходные данные размещаются во входном потоке) или содержаться в указанных наборах данных и/или устройствах. Выходной набор данных SYSOUT служит для размещения системных сообщений, а также сообщений и результатов работы, выполняемых в рамках задания программ. Система предоставляет возможность просмотреть и распечатать SYSOUT, который иногда называют отчетом или листингом задания.
Процедуры JCL
В языке управления заданиями, как и в других языках программирования, могут быть определены процедуры. Мы уже не раз упоминали этот важнейший элемент JCL при рассмотрении различных функций z/OS.
Процедура представляет собой последовательность предложений (операторов) JCL, оформленных как автономная JCL-программа. Процедура может храниться в системной или пользовательской библиотеке процедур либо непосредственно описываться в задании. Процедуры JCL, как и процедуры языков программирования, предназначены для решения типовых пользовательских задач на основе принципа: "один раз записал и сохранил, много раз использую". Такой подход существенно упрощает процесс составления заданий.
При обращении к процедуре входящие в ее состав операторы JCL вставляются в задание вместо вызывающего оператора EXEC. При этом могут быть изменены значения параметров операторов процедуры, целые операторы, а также добавлены новые операторы.
В JCL поддерживается два вида процедур: каталогизированные процедуры и процедуры во входном потоке. Каталогизированные процедуры размещаются в специальных наборах данных - библиотеках процедур. JES2 располагает настраиваемым списком используемых стандартных библиотек. Пользователь также имеет возможность указать собственный набор библиотек процедур с помощью оператора JCLLIB (о нем речь пойдет ниже). Процедуры во входном потоке описываются непосредственно в задании после оператора JOB.
Процедура начинается оператором процедуры PROC и заканчивается оператором конца процедуры PEND. Имя оператора процедуры является именем процедуры при размещении ее во входном потоке. В операторе PROC могут быть описаны параметры процедуры. Процедуры могут содержать различные операторы JCL, включая EXEC, DD, OUTPUT, IF/THEN/ELSE, INCLUDE, CNTL, ENDCNTL, SET, а также вызовы других процедур. Процедуры не должны содержать операторы DD * и DD DATA, оператор //JOBLIB DD, операторы JES и описания других процедур (операторы PROC и PEND).
Каждый оператор EXEC вместе с принадлежащими ему операторами DD называется шагом (пунктом) процедуры.
Имя оператора EXEC является именем шага процедуры. В общем виде процедура имеет следующую структуру:
//имя PROC параметры // EXEC // DD ... // EXEC // DD ... // PEND
В теле процедуры могут быть записаны так называемые символические или формальные параметры, которые при вызове процедуры могут быть заменены на заданные пользователем значения (фактические параметры). Формальные параметры представляются в виде &имя, и могут быть указаны в процедуре в качестве параметра, подпараметра или значения в любом операторе. Фактические значения для символических параметров устанавливаются в вызывающем процедуру операторе EXEC, в виде списка, каждый элемент которого выглядит так:
имя=фактическое_значение
Рассмотрим пример некоторой абстрактной процедуры, на котором будут показаны особенности построения и использования процедур:
//MYPROC PROC UNT=SYSDA,PRN=A,TOM=DISK8,P=P2,NAME=DS.OPT //ST1 EXEC PGM=SUV,REGION=50K //LIB DD DSN=SYSLIB,DISP=OLD //SYSIN DD DSN=&NAME,DISP=(NEW,KEEP), // VOL=SER=&TOM,UNIT=&UNT, // SPACE=(TRK,(10,1,10)) //SYSOUT DD SYSOUT=&PRN //ST2 EXEC PGM=CALC,PARM=(P1,&P,P3) //TABL DD DSN=TABL.DATA,DISP=SHR // VOL=SER=WORK1,UNIT=DISK // PEND
Данная процедура с именем MYPROC содержит два шага (ST1 и ST2). В теле процедуры выделено пять формальных параметров. В операторе PROC представлен список фактических стандартных значений формальных параметров, которые будут использоваться по умолчанию в случае, если пользователь не определит собственные фактические значения. Например, если процедура будет вызвана в задании следующим образом:
//PRIM1 EXEC MYPROC
то это как раз такой случай: все значения формальных параметров будут выбраны из оператора PROC.
Если же пользователь захочет изменить все или некоторые стандартные значения, их необходимо указать непосредственно в операторе EXEC:
//PRIM2 EXEC MYPROC,NAME=BIBL,UNT=3390
В данном случае устанавливаются новые значения для формальных параметров NAME и UNT, а остальные параметры примут стандартные значения, записанные в операторе PROC.
При изменении значений параметров пользователь обязан следить, чтобы модифицированная таким образом процедура была корректной как синтаксически, так и семантически. Очевидно, что значения символических параметров, назначенных пользователем в операторе EXEC, действуют только в текущем шаге задания. На другие шаги задания их действие не распространяется, и там могут быть установлены другие значения.
Наряду с использованием символических параметров, существует возможность модифицировать целиком или частично операторы процедуры EXEC и DD. Например, модификация параметров операторов EXEC может производиться следующим образом:
//PRIM3 EXEC MYPROC,REGION.ST1=100K,COND.ST2=(8,LE,ST1)
Здесь пользователь требует изменить значение параметра REGION, используемого в шаге процедуры ST1, и добавить параметр COND к оператору шага ST2. Синтаксис записи модифицируемых параметров вполне очевиден.
Модификация параметров операторов DD осуществляется несколько иначе. Например, при необходимости изменить имя и диспозицию набора данных, описанного в операторе DD с именем LIB шага ST1, и отказаться от определения параметров в VOL и UNIT операторе DD с именем TABL шага ST2, при вызове процедуры следует записать:
//PRIM4 EXEC MYPROC,NAME=XXXXX.YY,P=P5 //ST1.LIB DD DSN=USERLIB,DISP=SHR //ST2.TABL DD DSN=TABL1.DATA,VOL=,UNIT=
Обратите внимание, что имена модифицирующих DD операторов задания записываются как составные: сначала указывается имя шага процедуры, затем, после разделительной точки, имя модифицируемого оператора DD процедуры.
Точно таким же образом может производиться добавление в процедуру новых операторов DD:
//PRIM5 EXEC MYPROC,PRN=* //ST2.SYSPRINT DD SYSOUT=A
Здесь к шагу ST2 процедуры будет добавлен оператор DD с именем SYSPRINT. Таким способом можно обойти ограничение на использование в теле процедур операторов DD * и DD DATA.
Значительную роль в работе пользователей z/OS играют имеющиеся в системе каталогизированные процедуры. Как уже отмечалось, обычно существует несколько стандартных библиотек процедур (самая известная среди них - SYS1.PROCLIB), определяемых системным программистом в настройках подсистемы JES2.
Библиотеки содержат множество готовых процедур, предназначенных для решения типовых задач пользователей и администраторов, включая процедуры поддержки разработки приложений (компиляция, редактирование связей и выполнение программ), процедуры запуска и настройки системных компонентов, процедуры управления данными и т.п.
Для вызова таких процедур в задании необходимо указать имя каталогизированной процедуры и при необходимости фактические параметры, а также модифицирующие операторы. Важно подчеркнуть, что в качестве имени каталогизированной процедуры используется имя раздела библиотеки процедур, а не имя оператора PROC! Отметим также, что каталогизированные процедуры могут вызываться по команде оператора START, при этом порождаются запускаемые процедуры (STC-задания), о которых упоминалось ранее. Примеры применения некоторых каталогизированных процедур при разработке приложений будут рассмотрены в п. 5.1.8.
Помимо системных библиотек процедур, доступных пользователям по умолчанию, существует возможность создания и использования личных библиотек процедур. В этом случае потребуется сообщить системе имена таких библиотек с помощью оператора JCLLIB. Данный оператор имеет единственный параметр ORDER, с помощью которого можно задать список личных библиотек, используемых в задании:
ORDER=(библиотека1[,библиотека2]...)
В приведенном ниже примере определен список из двух библиотек (USER1.PROCLIB,USER1.WORKLIB), которые система будет использовать для поиска процедуры SMETA в первую очередь. Если поиск завершится неудачей, будут просматриваться системные библиотеки:
//USER1 J0B ... //USERLIB JCLLIB ORDER=(USER1.PROCLIB,USER1.WORKLIB) // EXEC PROC=SMETA
Структура отчета о выполнении задания
Как отмечалось ранее, все сообщения и результаты работы программ, выполняемых в рамках задания, группируются JES2 в наборе данных SYSOUT. На основе этих данных формируется отчет о выполненном задании. У пользователя есть несколько способов получить и вывести отчет, используя средства TSO/E, ISPF/PDF или SDSF. На рис. 5.22 представлен общий вид отчета (листинга) о выполнении задания.

Рис. 5.22. Пример отчета о выполненном задании
Стандартный листинг состоит из нескольких информационных блоков:
Общая информация, определяемая при инсталляции системы.Статистическая информация, формируемая подсистемой управления заданиями JES.Текст задания на языке JCL, если заданы соответствующие значения параметра MSGLEVEL и сообщения о синтаксических ошибках.Системные сообщения о ходе и результатах выполнения задания.
Основным признаком правильности выполнения задания является значение кода завершения (Condition code), отображаемое в блоке 4 листинга в виде:
СOND CODE = XXXX
Если код завершения равен 0000, то задание выполнено успешно. Ненулевое значение кода означает, что задание завершилось аварийно (состояние ABEND). Каждому значению кода завершения соответствует определенная причина, а в отчете содержатся поясняющие диагностические сообщения.
Структура пакетного задания JCL
Итак, прежде чем передать пакетное задание системе, пользователь должен подготовить его текст на языке JCL. Обычно текст задания создается в некотором наборе данных с помощью текстового редактора, откуда специальными средствами пользовательского интерфейса его можно направить на обработку в подсистему JES2. z/OS требует, чтобы для представления заданий использовались только последовательные и библиотечные наборы данных с параметрами RECFM=FB и LRECL=80. Текст задания вводится, как правило, прописными буквами.
Задание состоит из последовательности управляющих предложений JCL (job control statement)2). Каждое предложение имеет следующую структуру:
//ИМЯ ОПЕРАТОР ОПЕРАНДЫ КОММЕНТАРИЙ
В первых двух позициях всегда (или почти всегда) указываются две косые черты (знак слэш /), которые являются главным отличительным признаком предложений JCL.
Поле имя начинается с третьей позиции и служит для идентификации представленного в предложении оператора. Фактически это метка, на которую можно ссылаться из различных предложений задания или других заданий. Имя может содержать не более восьми символов, включающих латинские буквы, цифры и специальные знаки ($ # @). Имя должно начинаться с буквы или специального знака, русские буквы и пробелы использовать нельзя. В некоторых специальных случаях применяют составные имена, использующие в качестве разделителя точку. Пробел в третьей позиции является признаком отсутствия имени.
Примеры правильных имен: STOUT1, SYSPRINT, IVANOV, IVAN#S
Примеры неправильных имен: 3DIAGNOZ (начинается с цифры), DIAGNOSTIKA (содержит более восьми символов), ТОМ+И (содержит недопустимый символ И).
Вслед за полем имени следуют другие поля, отделяемые друг от друга одним или несколькими пробелами.
| JOB | Начало задания и режим выполнения задания |
| EXEC | Начало шага задания, указание выполняемой программы или процедуры |
| DD | Описание набора данных и используемых устройств |
| COMMAND | Ввод системной (консольной) команды MVS или команды JES |
| PROC | Начало процедуры и описание параметров процедуры |
| PEND | Конец процедуры |
| JCLLIB | Список библиотек для поиска процедур, указанных в задании |
| OUTPUT | Параметры формирования отчета о выполнении задания (SYSOUT) |
| INCLUDE | Имя раздела библиотеки, текст которого необходимо включить в указанное место задания |
| CNTL/ENDCNTL | Начало и конец блока управляющих параметров, передаваемых программе во входном потоке |
| IF/THEN/ELSE/ENDIF | Условное выполнение шагов задания (ветвление) |
| SET | Инициализация или изменение значений символических параметров |
| /* | Оператор ограничения данных, представленных во входном потоке |
| // | Пустой оператор (конец задания) |
| //* | Оператор комментария |
Поле оператор определяет тип управляющего оператора JCL, который задается одним из ключевых слов, представленных в таблица 5.4. Назначение и использование основных операторов (JOB, EXEC, DD) будет рассмотрено в данной главе.
Поле операнды предложения JCL содержит список разделенных запятыми параметров, которые записывают вслед за именем оператора (через один или несколько пробелов). С помощью параметров сообщают информацию, необходимую для выполнения оператора. Различают позиционные и ключевые параметры.
Позиционные параметры часто имеют произвольный формат записи, но всегда указываются в строгой последовательности и всегда перед ключевыми параметрами. Если позиционный параметр опускается, то запятая, которая должна следовать за параметром, остается (исключение составляет случай, когда опускается последний параметр в списке позиционных параметров). Примеры записи позиционных параметров:
333,TEST,,0.8E-15 NEW,,DELETE
Ключевые параметры задаются с использованием предопределенных ключевых слов в виде: ключевое_слово=значение. Например, CLASS=B, REGION=100M, COND=(1,LE). Последовательность записи ключевых параметров - произвольная.
Отдельные параметры могут включать подпараметры, которые также задают в виде списка, заключенного в апострофы или круглые скобки. Как и параметры, подпараметры могут быть позиционными и ключевыми. Скобки или апострофы опускаются, если в списке указывается один подпараметр. Например:
DISP=(NEW,,DELETE) - позиционные подпараметры параметра DISP
DCB=(RECFM=FB,LRECL=80) - ключевые подпараметры параметра DCB
В поле комментарий предложения JCL помещают произвольную текстовую информацию, поясняющую назначение или особенности использования отдельных операторов. Отметим, что для этой цели может применяться специальный оператор комментария //*. Этот текст не обрабатывается при выполнении задания.
Поля предложений JCL не должны выходить за пределы 71-й позиции строки. Если же текст предложения не умещается в одной строке, то его (кроме предложения комментария //*) разрешается продолжить на следующей.
При этом если необходимо перенести на следующую строку некоторые параметры из списка, то следует соблюдать такие правила:
Разрыв строки необходимо сделать точно в том месте, где располагается разделительная запятая списка параметров.В следующей строке в позициях 1 и 2 нужно указать символы //. Продолжить ввод списка параметров, начиная не ранее 4-й, но не позднее 16-й позиции строки.
Вот как выглядит запись многострочного предложения JCL:
//OUT DD UNIT=SYSDA,VOL=SER=UB1, // DISP=NEW,SPACE=(1000(5,4)), // DSN=&&TEMP1
Исключением из этого правила является ситуация, когда перенос требует "разорвать" параметр, заключенный в апострофы. В этом случае следует вводить текст предложения до 71-й позиции включительно, а продолжение располагать точно с 16-й позиции следующей строки.
Структуру задания в z/OS схематично можно представить в виде последовательности операторов (рис. 5.21). Первым всегда указывается оператор задания JOB, который отмечает начало задания. Непосредственно за оператором JOB могут следовать другие операторы (DD, JCLLIB, OUTPUT), с помощью которых описывают общие ресурсы задания в целом (наборы данных, библиотеки процедур, параметры вывода результатов).

Рис. 5.21. Структура задания
Последующие операторы задания группируются по шагам или пунктам. Шаг (пункт) задания (job step) - это последовательность операторов JCL, начинающаяся с оператора EXEC и включающая некоторое количество иных операторов (в основном DD). Оператор EXEC (его называют иногда оператором шага задания) устанавливает, какую программу (загрузочный модуль) или процедуру JCL необходимо выполнить. С помощью операторов DD в шаге задания описывают наборы данных и/или устройства, используемые при выполнении указанной в операторе EXEC программы (процедуры). Шаги задания выполняются строго последовательно. Однако есть возможность пропуска (невыполнения) некоторых шагов в зависимости от результатов работы предыдущих шагов с помощью операторов IF/THEN/ELSE или параметра COND операторов JOB и EXEC.Общее количество шагов задания не может превышать 255, включая шаги всех вызываемых в задании процедур.
Далее приводится обзор основных операторов языка управления заданиями, который, однако, не претендует на полноту и не может служить заменой стандартной документации [14], [15]. Многие операторы и особенности их применения представлены без некоторых деталей, которые могут понадобиться при практическом использовании JCL. При описании формата операторов используются привычные мнемонические правила:
информация, заключенная в квадратные скобки, является необязательной и может быть опущена;символ | используется для указания альтернативных значений, из которых следует выбрать одно.
Нужно отметить, что язык JCL достаточно подробно описан в отечественной литературе [16], [17], [18], в том, правда, виде, в каком он сложился к началу 90-х годов.
Управление заданиями и язык JCL
Рассмотрим ключевые параметры оператора DD.
Параметр DSNAME (допускается сокращенная запись DSN) определяет имя набора данных (простое или составное), например:
//BIBL DD DSNAME=LIB1 //SYSIN DD DSN=D.USER1.DATA
Для указания раздела библиотеки в скобках записывают имя раздела:
//LOAD DD DSN=USERLIB(PROG1) //XXX DD DSN=MY.JCL(JOBTEST)
Перед именем временного набора данных записывают два знака амперсанда &&:
//SYSLIN DD DSN=&&LOADSET(GO) //SYSUT1 DD DSN=&&SYSUT1
Временные наборы данных автоматически уничтожаются системой после завершения шага задания. Отсутствие в операторе DD параметра DSNAME также означает, что набор данных временный. В этом случае имя набора данных будет сгенерировано автоматически, например, так:
SYSxxxxx.Txxxxxx.RA000.jobname.Rxxxxxx
где x - определенным образом сформированные цифры и символы.
В качестве значения параметра DSNAME можно указывать ссылки на другие операторы DD в формате *.имя_DD или *.имя_шага.имя_DD.
//STFG EXEC PGM=PROG1 //SYSUT1 DD DSN=DATA.IN ... //SYSLIN DD DSN=*.STFG.SYSUT1
Параметр DISP (диспозиция) определяет исходное состояние набора данных, а также действия, которые необходимо произвести с набором данных после завершения шага задания или всего задания: сохранить, уничтожить, каталогизировать и др. Формат записи параметра DISP включает три позиционных подпараметра:
DISP=([статус][,дисп_НЗ][,дисп_АЗ])
где статус - исходное (текущее) состояние набора данных, дисп_НЗ - действие при нормальном завершении шага задания, дисп_АЗ - действие, которое надлежит выполнить при аварийном завершении шага задания.
Подпараметр статус может принимать следующие значения:
NEW - в указанном шаге задания создается новый набор данных;
OLD - набор данных существует (создан ранее);
SHR - набор данных существует и может быть использован одновременно другим заданием, т.е. разделяется различными заданиями в режиме чтения;
MOD - набор данных существует и будет модифицироваться в указанном шаге задания (используется только для последовательных наборов данных).
Подпараметры диспозиции дисп_НЗ и дисп_АЗ могут принимать следующие значения:
DELETE - набор данных следует уничтожить;
KEEP - набор данных следует сохранить;
CATLG - набор данных следует сохранить и каталогизировать;
UNCATLG - набор данных нужно сохранить, но при этом исключить из системного каталога.
PASS - набор данных следует передать для использования в последующем шаге того же задания.
Последнее значение (PASS) может быть использовано только для подпараметра дисп_НЗ.
Примеры задания диспозиции:
DISP=(NEW,KEEP,DELETE) - набор данных создается и будет сохранен при нормальном завершении и удален при аварийном завершении шага задания;DISP=(SHR,KEEP,UNCATLG) - набор данных существует и будет сохранен при нормальном завершении и исключен из каталога при аварийном завершении шага задания.
Допускается не указывать некоторые или даже все подпараметры, учитывая следующие правила формирования их значений по умолчанию:
если не указан первый подпараметр (статус), то принимается значение NEW;если не указан второй подпараметр (дисп_НЗ), то принимается значение DELETE для нового и KEEP для существующего набора данных;если не указан третий подпараметр (дисп_АЗ), то принимается значение, заданное для второго подпараметра (дисп_НЗ);если не указан параметр DISP, то принимаются значения (NEW,DELETE,DELETE), то есть набор данных создается и уничтожается во время выполнения шага задания (временный).
Примеры:
DISP=(NEW,KEEP) и DISP=(,KEEP) соответствует DISP=(NEW,KEEP,KEEP) DISP=NEW и DISP=(NEW,,DELETE) соответствует DISP=(NEW,DELETE,DELETE) DISP=OLD соответствует DISP=(OLD,KEEP,KEEP) DISP=(OLD,,DELETE) соответствует DISP=(OLD,KEEP,DELETE) DISP=(SHR,,KEEP) соответствует DISP=(SHR,KEEP,KEEP)
Параметр UNIT назначает набору данных устройство ввода-вывода и определяется в большинстве случаев одним из трех значений (см. п. 5.1.3):
UNIT=адрес | типовое_имя | групповое_имя
Подпараметр адрес задает трех- или четырехразрядный физический адрес устройства (в шестнадцатеричном представлении).
Подпараметр типовое_имя задает устройство по установленному производителем оборудования номеру модели, однозначно указывающему на тип устройства. Подпараметр групповое_имя определяет устройство через логическое имя устройства или группы устройств, задаваемое системным программистом на этапе конфигурирования оборудования с помощью компонента HCD в таблице EDT. Ниже приведены примеры задания параметра UNIT различными способами:
//AD DD UNIT=220 - адрес устройства //TD DD UNIT=3390 - типовое имя //GD DD UNIT=SYSDA - групповое имя //GD DD UNIT=VIO - набор данных в виртуальной памяти
Параметр VOLUME (сокращенно VOL) указывает том или тома, на которых размещается набор данных. Рассмотрим наиболее употребительные варианты использования данного параметра.
В первом варианте том определяется посредством задания серийного имени тома в виде:
VOL=SER=имя[,имя]...
Например:
//DSETl DD DSN=YS,UNIT=SYSDA,VOL=SER=PTOM01
Здесь описан набор данных YS, находящийся на устройстве, принадлежащем к группе SYSDA с серийным номером тома PTOM01. Для многотомных наборов данных следует указывать список имен.
Во втором варианте том задается через ссылку, определяемую одним из трех способов:
VOL=REF=имя_набора_данных | *.имя_DD |.имя шага.имя_DD
В первом способе будет выбран том, на котором размещен ранее описанный в задании каталогизированный набор данных. Второй и третий способы используют стандартный формат ссылок. Рассмотрим пример:
//STEP1 EXEC PGM=.... //DD1 DD DSN=OLD.DATASET,DISP=SHR //DD2 DD DSN=DSET1,DISP=(,CATLG,DELETE),VOL=REF=*.DD1 //STEP2 EXEC PGM=... //DD3 DD DSN=DSET2,DISP=(,CATLG),VOL=REF=*.STEP1.DD1
Здесь создаваемые наборы данных DSET1 и DSET2 будут размещены на том же томе, что и существующий набор данных с именем OLD.DATASET.
Параметр DCB устанавливает характеристики логической организации набора данных, фиксируемые в блоке управления данными (Data Control Block), который создается системой для каждого набора данных. Блок управления данными представляет собой таблицу, которая после открытия заполняется информацией из описания набора данных в программе и дополняется данными из соответствующего оператора DD.
Параметр DCB обычно имеет формат:
DCB=(список подпараметров)
Все подпараметры DCB являются ключевыми. Перечислим основные из них:
DSORG - тип организации набора данных;RECFM - формат записей;LRECL - длина логической записи;BLKSIZE - длина блока;BUFNO - число буферов ввода-вывода, выделяемых набору данных;BUFL - размер каждого буфера в байтах.
Подпараметр RECFM может принимать следующие значения: F - записи фиксированной длины; V - записи переменной длины; U - записи неопределенной длины. Выбор типа записи определяет пользователь. Если он группирует записи в блоки, то указывает это, добавляя к символу формата букву В. Например, указание RECFM=FB означает, что сблокированные записи имеют фиксированную длину.
Примеры:
Набор данных состоит из записей фиксированной длины по 128 байт, которые объединяются в блоки по четыре записи в каждом:
DCB=(RECFM=FB,LRECL=128,BLKSIZE=512) Набор данных содержит неблокированные записи фиксированной длины по 80 байт:
DCB=(BLKSIZE=80,RECFM=F)
Вместо ключевых подпараметров DCB можно записать ссылку на другой оператор DD, причем некоторые подпараметры можно переопределить заново:
//ST1 DD DSN=VAX,DCB=(RECFM=VB,LRECL=64,BLKSIZE=640) //PRINT DD DCB=(*.ST1,BLKSIZE=128)
Здесь подпараметры набора данных для параметра DCB копируются из оператора DD с именем ST1, кроме размера блока, который задается непосредственно.
Элементы z/OS UNIX
z/OS UNIX является базовым компонентом z/OS и включает ядро системных сервисов UNIX (UNIX System Services Kernel) и прикладные сервисы (UNIX System Services Application Services). Основные элементы z/OS UNIX и связанные с ней компоненты z/OS представлены на рис. 5.23.
Ядро z/OS UNIX интегрировано в базовую управляющую программу z/OS и служит для реализации функций интерфейса системных вызовов (API UNIX), связанных с управлением процессами, файловой системой HFS и коммуникациями. Другие, поддерживаемые в API функции, обрабатываются непосредственно z/OS с помощью так называемых вызываемых сервисов
(callable services). Вызываемые сервисы могут быть использованы в программах на ассемблере и языках высокого уровня для доступа к функциям z/OS UNIX. Ядро z/OS UNIX обычно активизируется при загрузке z/OS и работает в собственном адресном пространстве MVS.
Прикладные сервисы z/OS UNIX представлены командным интерпретатором shell, набором стандартных утилит и отладчиком dbx. Командный интерпретатор поддерживает стандартный пользовательский интерфейс shell, позволяющий запускать приложения и утилиты, а также создавать и использовать командные файлы, называемые скриптами. Вводимые пользователем команды реализуются средствами ядра.
Отладчик dbx предназначен для автоматизированной интерактивной отладки приложений, создаваемых на языке C/C++. Отладчик располагает набором команд, хорошо известных пользователям UNIX.
Рис. 5.23. Компоненты z/OS UNIX
На рис. 5.23 представлены также стандартные компоненты z/OS, тесно связанные с поддержкой системных сервисов UNIX. К ним относятся:
TSO/ISPF - служат для выполнения команд и утилит, манипулирования файлами UNIX, а также для подключения пользователей к shell;компилятор C/C++ - используется для создания переносимых UNIX-приложений;языковая среда (LE), включающая библиотеку времени выполнения RTL (Run Time Library) для поддержки приложений (в том числе и на языке C/C++), - используется для выполнения команд shell и утилит;подсистема управления данными DFSMS - управляет наборами данных HFS, которые содержат файлы файловой системы UNIX;файловая система zFS (zSeries File System) - представленная в рамках сервисов поддержки распределенных вычислений DCE высокопроизводительная UNIX-подобная файловая система (начиная с z/OS V1R2). Может быть интегрирована в HFS как монтируемая файловая система.менеджер управления рабочей нагрузкой WLM - управляет созданием процессов UNIX;модуль сбора статистики SMF - фиксирует данные об используемых ресурсах;модуль управления доступом к ресурсам RACF - управляет доступом к файлам и приложениям UNIX;RMF - сбор данных и составление отчетов о функционировании сервисов UNIX.
Механизм выполнения приложений UNIX в z/OS
Для понимания механизма функционирования UNIX-сервиса необходимо установить соответствие между понятиями, используемыми в промышленных UNIX-системах, и соответствующими понятиями, применяемыми в MVS и z/OS. В частности, пользователи UNIX хорошо знакомы с понятием процесса.
Процесс представляет собой основную единицу работы в операционной системе UNIX и соответствует находящейся в стадии выполнения программе со всеми выделенными ей ресурсами. В зависимости от типа программы различают системные и пользовательские процессы. Среди системных выделяют процессы-демоны (daemon), работающие в фоновом режиме и предназначенные для поддержки вспомогательных системных сервисов (вывод на печать, электронная почта, запуск программ по расписанию и т.п.). Аналогом демонов в MVS могут считаться запускаемые процедуры (STC).
Каждый процесс имеет уникальный идентификатор PID и может по своей инициативе порождать новые (дочерние) процессы с помощью системных вызовов fork() и spawn(). Таким образом, у каждого процесса (кроме одного, самого первого) существует родительский процесс, связь с которым поддерживается благодаря еще одному атрибуту процесса PPID - идентификатору родительского процесса.
Процессы, порождаемые UNIX-приложениями в z/OS, могут выполняться исключительно в адресных пространствах (АS) MVS, причем как в собственных, так и в адресных пространствах родительского процесса (рис. 5.24). При использовании системного вызова fork() всегда создается новое адресное пространство, являющееся копией родительского. При использовании системного вызова spawn() может быть как создано новое адресное пространство, так и запущена новая задача внутри родительского АS. Адресные пространства, содержащие UNIX-процессы, могут порождаться и по инициативе MVS-приложений при обращении к вызываемым сервисам z/OS UNIX.
Рис. 5.24. Процессы в z/OS UNIX
Теперь познакомимся более подробно с механизмом выполнения приложений UNIX в z/OS, представленным на рис. 5.25.
Как уже отмечалось, для ядра z/OS UNIX выделяется отдельное адресное пространство (OMVS), создаваемое на этапе инициализации системы и функционирующее в соответствии с настройками, определенными в разделе BPXPRMxx системного реестра SYS1.PARMLIB.
Организация файловой системы HFS
Организация хранения данных в операционной системе UNIX имеет существенные отличия от традиционного способа управления данными, принятого в MVS. В первую очередь файлы UNIX, в отличие от наборов данных MVS, обрабатываются системой как простая совокупность байтов без деления на логические записи, при этом логический уровень представления данных передается приложениям. Имена файлов могут содержать до 255 алфавитно-цифровых символов, при этом различают прописные и строчные буквы. Разделение файлов UNIX по типам производится в соответствии с их функциональным назначением и по типу данных. В частности, выделяют следующие типы файлов:
обычные - файлы общего назначения, используемые для хранения программ и данных любого типа;каталоги - служат для размещения справочной информации о размещении файлов, принадлежащих данному каталогу;устройства - ассоциируются с устройствами ввода-вывода;символические ссылки - содержат ссылки на другие файлы;именованные каналы - служат для обмена данными между процессами;сокеты - служат для реализации сетевого взаимодействия.
Файлы группируются по соподчиненным каталогам, образуя иерархическую древовидную структуру, представленную на рис. 5.26. Вершиной дерева и единой точкой входа в файловую систему является корневой каталог (/). Таким образом, у каждого файла существует полное или абсолютное имя, однозначно определяющее его местоположение в файловой системе: /u/user1/docs/abc, /u/user2/prg и т.п.
Рис. 5.26. Структура файловой системы UNIX
Наиболее важные системные программы, данные и конфигурационные файлы UNIX размещаются в специальных каталогах: /bin - команды и утилиты; /usr - файлы для поддержки решения пользовательских задач; /dev - специальные файлы устройств ввода-вывода; /etc - утилиты администрирования и конфигурационные файлы; /lib - включаемые библиотеки C/C++; /tmp - временные файлы; /var - сообщения и системные журналы; /samples - примеры программ и настроечных файлов.
ОС UNIX использует собственную систему разграничения прав доступа к файлам (на чтение, запись и выполнение) для трех категорий пользователей: владельца файла, членов группы владельца и всех остальных.
Все указанные выше особенности файловой системы UNIX поддерживаются системными сервисами UNIX в z/OS. Для размещения файлов UNIX и реализации иерархической структуры доступа создаются специальные однотомные SMS-управляемые наборы данных, получившие название наборов данных HFS (рис. 5.27). Каждый набор данных HFS содержит определенный сегмент файловой системы, точкой входа в который является один из каталогов [20]. Объединение сегментов HFS производится с помощью специальной операции "монтирования", выполняемой на этапе инициализации системы или динамически. Первым всегда монтируется сегмент, содержащий корневой каталог файловой системы (/), к которому затем могут добавляться другие сегменты. Создание и управление наборами данных HFS осуществляется стандартным компонентом z/OS DFSMS.
Рис. 5.27. Наборы данных HFS и файловая структура
Пользовательский интерфейс z/OS UNIX
Основой пользовательского интерфейса UNIX является командный интерпретатор shell, реализующий взаимодействие с пользователем через терминальное устройство. Shell поддерживает язык интерактивных команд, регламентированных стандартом POSIX 1003.2, и принимает запросы пользователя на выполнение утилит и приложений. Язык shell позволяет создавать и использовать командные файлы, называемые скриптами. В z/OS UNIX включены два типа командных интерпретаторов, базирующихся на известных в мире UNIX оболочках:
z/OS shell на основе UNIX System V shell и Korn shell;tcshell на основе Berkeley C shell;
Для пользователей z/OS UNIX поддерживается несколько различных режимов интерактивного доступа к системным сервисам UNIX, как с помощью shell, так и некоторыми другими способами, представленными на рис. 5.28. Рассмотрим эти возможности в условиях TCP/IP-соединения с рабочей станцией (терминалом) пользователя.
Рис. 5.28. Режимы доступа пользователей к z/OS UNIX
Первый режим подключения является традиционным для пользователей z/OS и основан на использовании компонентов TSO/E и ISPF. В TCP/IP-сети терминалы TSO поддерживаются на основе специального протокола TN3270, представляющего собой адаптированный вариант стандартного протокола telnet. Терминалы TN3270 являются синхронными, то есть обслуживаются в режиме построчного ввода, что накладывает определенные ограничения на использование некоторых интерактивных действий пользователя по сравнению с классическими UNIX-системами.
В рамках сеанса TSO/ISPF пользователи располагают следующими средствами доступа к сервисам UNIX [19]:
Команда OMVS - запускает для пользователя индивидуальную сессию командного интерпретатора shell, при этом обеспечивается: поддержка большинства команд shell;поддержка команд TSO;поддержка команд shell для копирования (перемещения) данных между файлами HFS и наборами данных MVS;использование текстового редактора ISPF;поддержка нескольких параллельных сессий.Команда ISHELL (то есть ISPF shell) - запускает адаптированный в стиле диалогов ISPF интерфейс для доступа к файловой системе z/OS UNIX, с возможностью просмотра каталогов и выполнения стандартных операций над файлами (редактирование, удаление, переименование, копирование и т.д.); поддерживает средства запуска приложений и администрирования.Команда OSHELL (скрипт REXX) - служит для выполнения команд shell и запуска приложений UNIX непосредственно из командной строки TSO/E.Набор специальных команд TSO/E для работы с файлами UNIX и копирования (перемещения) данных между файлами HFS и наборами данных MVS (MKDIR, OGET, OPUT и т.д.).Утилита BPXBATCH - предназначена для запуска команд, скриптов и приложений UNIX в пакетных заданиях, при этом для описания файлов HFS используются специальные параметры оператора DD (PATH, PATHDISP, PATHOPT, PATHMODE).
Второй режим доступа к сервисам UNIX основан на подключении с использованием стандартных прикладных протоколов TCP/IP rlogin или telnet. Такой способ получил название "прямого подключения" к z/OS UNIX shell и поддерживает традиционные для UNIX асинхронные терминалы, обеспечивающие посимвольный ввод. Возможность прямого подключения требует инициализации и настройки серверных компонентов telnet и rlogin, а также разрешений на доступ в профиле RACF пользователя. В отличие от режима OMVS, здесь можно задействовать текстовый редактор vi, но ограничена поддержка команд TSO.
Третий режим доступа к сервисам UNIX основан на использовании ftp-протокола, также являющегося стандартным прикладным протоколом TCP/IP. В данном режиме поддерживается ряд команд, с помощью которых можно получать доступ к данным MVS и UNIX и производить операции по их копированию (перемещению) на рабочую станцию пользователя и обратно, а также запускать на выполнение подготовленные на рабочей станции пакетные задания.
OS UNIX, являются неотъемлемым компонентом
Системные сервисы UNIX, получившие в новейших версиях название z/ OS UNIX, являются неотъемлемым компонентом z/OS, превратившим ее в открытую операционную систему [19], [20]. Начиная с версии OS/390 V1R2 реализована полная поддержка стандартов POSIX (Portable Operating System Interfaces Unix) и XPG 4.2 (X/Open Portability Guide), принятых многими разработчиками UNIX-систем. Таким образом, в z/OS UNIX реализовано два открытых системных интерфейса:
интерфейс системных вызовов (API) для приложений, написанных на языке C, что дает возможность запускать стандартные UNIX-приложения в z/OS;интерактивный интерфейс пользователя (shell), обеспечивающий выполнение в z/OS стандартных команд, утилит и скриптов UNIX в форме, привычной для пользователей UNIX-систем.
Кроме этого, для хранения данных в z/OS UNIX реализована поддержка иерархической файловой системы UNIX, получившей название HFS (Hierarchical File System). Файлы UNIX размещаются в SMS-управляемых наборах данных z/OS специального типа (их называют HFS-наборами данных).
Важно отметить, что z/OS UNIX представляет собой не надстройку или оболочку, эмулирующую интерфейсы UNIX, а является неотъемлемой частью системного ядра BCP и тесно интегрирована с другими модулями и компонентами z/OS, такими как DFSMS, RACF, WLM, SMF, RMF, SDSF, TSO/E, ISPF/PDF и др. Многие системные функции z/OS (например, TCP/IP, HTTP server), реализованы как UNIX-приложения. То же самое можно сказать и о популярных системах промежуточного слоя, таких как DB2 и Websphere Application Server.
Приложения UNIX выполняются в адресных пространствах MVS и могут запускаться как из пользовательской среды shell, так и из среды TSO/ISPF, пакетных заданий и STC-процедур. Файлы UNIX, хранящиеся в HFS, доступны как приложениям UNIX, так и классическим приложениям z/OS (MVS) и могут обрабатываться с помощью команд TSO/ISPF и JCL-заданий. Поддерживается свободное копирование и перемещение данных между файлами HFS и наборами данных MVS.
У пользователей существует возможность интерактивного взаимодействия с UNIX-сервисами как через стандартный TSO/ISPF-интерфейс, так и путем прямого подключения к UNIX shell через telnet/rlogin протокол в рамках TCP/IP-соединения.
Дублирование строк (R)
Формат команды:
1) R[n] 2) RR[m]
Строчная команда R (Repeat) служит для дублирования строки, содержащей эту команду, заданное (n) число раз в последующих строках. Для однократного дублирования одной строки значение n не указывается.
Для дублирования группы строк может использоваться команда RR. Команда RR вводится в первой и последней строках дублируемого строчного фрагмента. Первая и последняя строки фрагмента необязательно должны быть на одной странице экрана. Для повторения группы строк более одного раза необходимо указать число повторений группы строк m в команде RR в первой или последней строке либо в той и другой.
Пример дублирования строчного фрагмента (строки 1-3) и дважды строки 5:
rr0001 Это первая строка 000002 Это вторая строка rr0003 Это третья строка 000004 Это четвертая строка r20005 Это пятая строка 000006 Это шестая строка
Результат:
000001 Это первая строка 000002 Это вторая строка 000003 Это третья строка 000004 Это первая строка 000005 Это вторая строка 000006 Это третья строка 000007 Это четвертая строка 000008 Это пятая строка 000009 Это пятая строка 000010 Это шестая строка
Импорт данных. Команды COPY и MOVE
Под импортом данных понимают процедуру перемещения или копирования данных из какого-либо раздела или набора данных в редактируемый раздел (набор). В текстовом редакторе EDIT импорт реализуется функциональными командами COPY или MOVE, с помощью которых указывается, откуда, и строчных команд A или B, которые указывают, куда данные должны копироваться или перемещаться.
Функциональная команда редактора COPY используется для копирования содержимого раздела библиотечного набора данных или последовательного набора данных в редактируемые данные.
Формат команды:
COPY [имя_paздeлa]
Необязательный параметр имя_paздeлa определяет имя раздела, который необходимо скопировать в редактируемые данные. Если раздела с таким именем не существует, выполнение команды блокируется и выдается сообщение об ошибке. Если операнд имя_paздeлa опущен, на экране появляется диалоговое окно, в котором пользователь должен определить имя копируемого последовательного набора данных или раздела библиотечного набора данных.
Строчная позиция редактируемых данных, куда будет произведено копирование, задается с помощью строчных команд A или B, за исключением случаев, когда редактируется новый раздел или пустой последовательный набор данных.
При копировании больших наборов данных пользователь может существенно сократить время обработки. Это достигается путем отмены режима нумерации (NUMBER OFF) до выполнения операции копирования и повторного его включения после завершения.
В отличие от команды COPY команда MOVE служит для перемещения данных, что приводит к удалению раздела библиотечного набора данных или последовательного набора данных, из которого выполнена пересылка. Для последовательности сцепленных библиотек удаляется только раздел, находящийся в первой библиотеке последовательности. В остальном действие команды MOVE не отличается от команды COPY.
Использование утилит ISPF/PDF
Одними из наиболее полезных компонентов ISPF/PDF являются так называемые утилиты, доступные в главном меню как функция 3 (Utilities). Утилиты в первую очередь предназначены для управления последовательными и библиотечными наборами данных, включая функции создания, переименования, удаления, каталогизации, печати, сравнения и др.
Рис. 5.43. Панель выбора утилит
Меню выбора утилит, представленное на рис. 5.43, содержит следующие утилиты:
Library (библиотека) - обслуживание библиотечных наборов данных, включая сжатие и печать наборов данных; печать оглавления; печать, переименование, удаление, просмотр и редактирование разделов библиотек.Data Set (набор данных) - обслуживание произвольных наборов данных, включая создание (распределение), переименование, удаление, каталогизацию, исключение из каталога, просмотр служебной информации о наборах данных.Move/Copy (перемещение/копирование) - перемещение и копирование наборов данных, а также разделов библиотек.Dslist (список наборов данных) - работа со списком наборов данных и выполнения операций над ними; печать и просмотр информации об оглавлении тома (VTOC).Reset (сброс) - корректировка статистической информации о разделах библиотек ISPF.Hardcopy (печать твердой копии) - печать наборов данных на указанном устройстве.Download (загрузка) - загрузка различных компонентов системы и наборов данных с хоста на рабочую станцию (включая модули поддержки режима клиент-сервер ISPF C/S и др.).Outlist (выходной листинг) - просмотр, печать и удаление листинга выполненного задания.Commands (команды) - создание и корректировка таблицы команд ISPF.Format (формат) - настройка параметров представления данных для терминалов IBM 5550, использующих набор символов формата DBCS (Double-Byte Character Set).SuperC и SuperCE - сравнение наборов данных (простая и расширенная версии).Search-For и Search-For (поиск) - поиск текстовых строк в наборе данных (простая и расширенная версии).
Утилиты принято обозначать двойным номером в соответствии с их местоположением в иерархии панелей ISPF/PDF и способом выбора с уровня панели главного меню PDF: 3.1 - Library, 3.4 - Dslist и т.п.
Следует обратить внимание на тот факт, что одни и те же функции обслуживания наборов данных могут быть выполнены с привлечением различных утилит. В частности, утилита 3.4 (Dslist) является вообще универсальной, так как с ее помощью можно выполнить практически любую операцию с набором данных (или разделом библиотеки), включая переименование, копирование, перемещение, удаление и т.п. Эту утилиту часто называют "файловой оболочкой" z/OS по аналогии с известными программами для MS-DOS и Windows. Пользователь выбирает для себя тот способ, который ему больше подходит.
В этой главе основное внимание будет уделено средствам распределения новых наборов данных с помощью утилиты 3.2 (Data Set) и средствам манипулирования данными с помощью утилиты 3.4 (Dslist). Прежде чем будут рассмотрены указанные утилиты, необходимо познакомиться со средствами ввода имен наборов данных и работы со списком разделов библиотек, которые являются универсальными для всех функций PDF.
При использовании утилит, как и некоторых других функций, существует два основных способа ввода имени набора данных в соответствии с двумя типами используемых в ISPF/PDF наборов данных:
библиотеки ISPF;произвольные последовательные и библиотечные наборы данных.
Термин библиотека ISPF (ISPF Library) используется для обозначения каталогизированных библиотечных наборов данных (PDS и PDSE), для которых выполняются следующие правила:
имя набора данных состоит из трех квалификаторов и имеет вид: project.group.typeквалификатор project определяет общий идентификатор для выполняемого совместно с другими пользователями проекта либо идентификатор пользователя (User ID) для личных данных;квалификатор group определяет отдельную часть проекта или личных данных (например, указывает этап проекта или задачу и т.п.);квалификатор type определяет тип информации, содержащейся в библиотеке (например, текстовые документы, задания (JCL), исходные программы, загрузочные модули и т.п.);имена разделов определяются произвольно и характеризуют отдельные документы, программы, модули и т.п.
в составе библиотеки.
При этом выполняются все стандартные соглашения о формирования простых имен. Примеры имен библиотек ISPF: ASOUP.SUB01.PL1, USER23.Y2002.TEXT
При вводе имен библиотек ISPF составные квалификаторы имени вводятся раздельно в специальные поля панели, отмеченные надписями project, group, type и member. (рис. 5.44a). В поле member в этом случае вводится имя раздела. Наличие нескольких полей ввода уровня group обусловлено возможностью осуществлять конкатенацию (слияние) нескольких наборов данных одного типа, созданных в рамках единого проекта.
Имена произвольных последовательных и библиотечных наборов данных ("не библиотек ISPF") могут быть любыми допустимыми именами, в том числе и такими, как у библиотек ISPF. Различия заключаются только в способе ввода имени набора данных при работе с функциями ISPF (рис. 5.44b).

Рис. 5.44. Ввод имени набора данных
Для ввода имени произвольного набора данных используется поле Data Set Name. Имя вводится в стандартном формате (например, my.test.data или my.test.data(mem1)) с указанием имени раздела, если это необходимо. Обычно введенное имя заключается в апострофы, в противном случае ISPF/PDF автоматически добавит к имени префикс пользователя, записанный в профиле. Для некаталогизированных наборов данных дополнительно указывается серийный номер тома (поле Volume Serial). Следует иметь в виду, что при вводе имени библиотеки ISPF или произвольного набора можно воспользоваться системными или пользовательскими списками ссылок
на наборы данных (referral lists). В эти списки автоматически заносятся имена наборов данных, которые использовались в работе в последнее время или требовались наиболее часто.
Для работы с последовательным набором данных имя раздела, конечно, не задается. Для библиотечного набора данных существует три способа определения имени раздела:
Имя раздела указано явно при задании имени набора данных, как в приведенных примерах. В этом случае ISPF непосредственно обращается к данному разделу.Имя раздела при задании имени набора не указано.
В этом случае после нажатия клавиши ВВОД на экран будет выведен список разделов библиотеки (рис. 5.45), где пользователь должен выбрать тот раздел, который он будет обрабатывать, отметив его, например, строчной командой S (Select) и нажав на клавишу ВВОД.Имя раздела указано в виде шаблона. Шаблон задается в виде комбинации алфавитно-цифровых символов и специальных символов шаблона: * и %. Символ * означает, что в данной позиции может размещаться произвольное количество любых допустимых символов. Символ % заменяет ровно один произвольный символ. При этом необходимо помнить, что имя раздела не может содержать более восьми символов. Например, шаблон вида M*R% соответствует выбору следующих имен разделов: M2002R1, MEMBERX, M2R9, MAKARR. В случае задания шаблона на экран будет выведен список разделов библиотеки, соответствующих данному шаблону, где и следует выбрать требуемый раздел.
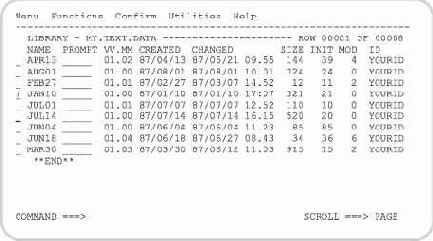
Рис. 5.45. Панель списка разделов библиотечного набора данных
Рассмотрим далее универсальные приемы работы со списком разделов библиотечного набора данных, ориентируясь на рис. 5.45. Отображение списка разделов можно получить при выполнении функций просмотра View (1), редактирования Edit (2), выполнения программ в интерактивном (Foreground, 4) и пакетном (Batch, 5) режимах, при работе с утилитами Library (3.1), Move/Copy (3.3), Dslist (3.4) и некоторыми другими. Для этого при задании имени библиотечного набора во всех случаях, кроме утилиты Dslist, следует либо оставить поле имени раздела пустым, либо ввести специальный шаблон имени, как указано выше. Утилита Dslist располагает собственными средствами инициирования вывода списка разделов.
При отображении списка ISPF выводит в виде таблицы статистическую информацию для каждого раздела, сформированную в момент его создания или редактирования. Эта информация генерируется и сохраняется ISPF в оглавлении набора данных и включает (в скобках указаны принятые наименования параметров):
имя раздела (Name);номер версии и номер модификации в формате (VV.MM); при создании устанавливается в состояние 01.00;дата создания текущей версии (Created);дата и время последней модификации текущей версии (Changed);текущий размер в строках (Size);начальный размер в строках (Init);количество строк, которые были добавлены или изменены (устанавливается 0, если строки не перенумеровывались) (Mod);идентификатор пользователя, производившего последнюю корректировку (ID).
При использовании функций редактирования и просмотра пользователь может изменять значения номера версии и модификации раздела с помощью специальных команд. Приведенный выше набор статистических параметров формируется в ISPF для всех типов библиотек, за исключением библиотек загрузочных модулей, которые дополнительно характеризуются и другими параметрами.
По умолчанию список упорядочен по имени разделов. Если список не умещается целиком в пределах экрана, следует использовать средства прокрутки.
Основное назначение списка разделов - предоставление удобного способа выполнения операций над разделами. Поля слева от имен разделов предназначены для ввода строчных команд, общий перечень которых представлен в таблице 5.6.
| E | Edit | Переход в режим редактирования |
| V | View | Переход в режим просмотра View |
| B | Browse | Переход в режим просмотра Browse |
| D | Delete | Удалить раздел |
| R | Rename | Переименовать раздел |
| P | Вывести раздел в набор данных печати | |
| M | Move | Переместить раздел |
| C | Copy | Копировать раздел |
| G | Reset | Сброс статистики раздела |
| J | Submit | Передать на выполнение в пакетном режиме |
| T | TSO Cmd | Выполнить команду TSO |
| W | WS Cmd | Выполнить команду рабочей станции |
| S | Select | Выбрать раздел |
| = | Повтор последней команды |
Если пользователь забыл какую-либо команду, он может получить список выбора допустимых команд во всплывающем окне, введя в поле строчной команды символ "/" или просто установив курсор слева от имени раздела и нажав клавишу ВВОД.
Сообщение о выполненной строчной команде выводится в поле Prompt списка разделов одним словом.Например, после выполнения команды удаления раздела в соответствующей строке появляется сообщение: *DELETED
Во всех утилитах ISPF разрешается вводить строчные команды сразу для нескольких разделов. В этом случае операции, требующие дополнительных данных или связанные с открытием новых панелей, будут выполняться последовательно. При завершении выполнения одной такой команды необходимо вновь нажать клавишу ВВОД. Все команды, не требующие вмешательства пользователя, выполняются сразу.
Отметим, что после выполнения некоторых строчных команд автоматического обновления списка не происходит. Для обновления рекомендуется сначала выйти из панели списка (F3), а потом снова открыть ее одним из ранее указанных способов.
Экспорт данных. Команды CREATE и REPLACE
Под экспортом данных понимают процедуру перемещения или копирования данных (всех или частично) из редактируемого раздела в другой раздел или набор данных. В текстовом редакторе EDIT экспорт реализуется с помощью функциональных команд CREATE или REPLACE и строчных команд M или C.
Функциональная команда редактора CREATE используется для создания нового раздела библиотечного набора данных и копирования или перемещения в него строк из редактируемых данных.
Формат команды:
CREATE [имя_paздeлa]
Необязательный параметр имя_paздeлa определяет имя раздела, который необходимо создать в редактируемом библиотечном наборе данных. Для последовательности сцепленных библиотек новый раздел всегда записывается в первую библиотеку последовательности. Если раздел с таким именем уже существует, выполнение команды блокируется и выдается соответствующее сообщение. Если параметр имя_paздeлa не указан, на экране появляется всплывающее диалоговое окно, в котором пользователь должен определить имя создаваемого раздела.
Данные для перемещения или копирования в новый раздел указываются с помощью строчных команд M (MM) или C (CC). При использовании строчной команды M (MM) отмеченный строчный фрагмент удаляется из редактируемых данных при завершении операции перемещения. Если требуется скопировать (переместить) весь редактируемый раздел, необходимо в первой строке редактируемого раздела указать строчную команду C99999 (или M99999). Данные, которые записываются во вновь созданный раздел, перенумеровываются, если установлен как режим нумерации, так и режим автоматической пepeнyмepaции (NUMBER ON, AUTONUM ON). Если установлен режим автоматической записи (AUTOLIST ON), то происходит запись текста в набор данных печати ISPF/PDF.
В отличие от команды CREATE, команда REPLACE служит для замещения уже существующих разделов библиотечного набора данных либо последовательных наборов данных информацией, копируемой или перемещаемой из редактируемых данных. В остальном действие команды REPLACE от действия команды CREATE не отличается.
Формат команды:
REPLACE [имя_paздeлa]
Как отмечалось ранее, пользователь может воспользоваться командами CREATE или REPLACE для сохранения редактируемых данных в другом разделе или наборе данных. Для этого необходимо:
Ввести строчную команду C99999 или M99999 в первой строке данных для указания того, что все строки должны копироваться или перемещаться.Ввести команду CREATE или REPLACE без параметра в области ввода команд (команда CREATE используется только в том случае, если местом сохранения является раздел библиотечного набора данных) и нажать клавишу ВВОД.Указать имя набора данных или раздела в открывшемся диалоговом окне ввода команды CREATE или REPLACE и нажать клавишу ВВОД.
Элементы пользовательского интерфейса ISPF
Пользовательский интерфейс ISPF ориентирован на применение терминалов типа IBM 327х и 3290, использующих алфавитно-цифровой дисплей с текстовым представлением информации в формате 24х80 (24 строки по 80 символов каждая) и стандартную клавиатуру. Пользователи рабочих станций на базе персональных компьютеров (ПК) должны задействовать специальную программу эмуляции терминала 3270 (протокол TN3270).
Существует ряд специальных клавиш, которые должны поддерживаться при работе с ISPF/PDF на клавиатурах любого типа. Клавиша ВВОД (на клавиатуре ПК ее заменяет правая клавиша Ctrl) служит для завершения ввода информации и передачи ее мэйнфрейму на обработку. Пользователь имеет возможность вводить и редактировать информацию только в специальных областях экрана, называемых полями ввода. Попытка ввода информации вне поля ввода вызывает блокирование клавиатуры. Выход из состояния блокирования производится по клавише СБРОС (левая клавиша Ctrl на ПК). Для перемещения курсора только по предназначенным для ввода полям рекомендуется использовать клавишу табуляции (Tab) или перевода строки (Enter). Следует отметить, что в текстовом режиме ISPF не поддерживает мышь. Исключение составляет режим доступа на базе ПК. В этом случае левая кнопка мыши позволяет лишь устанавливать курсор в указанной позиции экрана и не производит активных действий (например, при выборе элемента меню), а также позволяет выделять и копировать фрагменты текста в пределах экрана.
Основу взаимодействия пользователя с ISPF составляют специальные полноэкранные формы, называемые панелями. Понятие "панель" в ISPF соответствует понятию "окно" или "форма" для графических операционных систем. С помощью экранных панелей и клавиатуры пользователь осуществляет выбор функций операционной системы, ввод и редактирование данных, подготовку и запуск программ и заданий и т.п.
Основные элементы панелей ISPF представлены на рис. 5.32. В верхней строке панели размещается горизонтальное меню действий (action bar), с помощью которого реализуется доступ к различным функциям, как связанным с данной панелью, так и общесистемным.
Меню действий присутствует на всех без исключения панелях ISPF. Выбор и активизация пункта меню осуществляется путем позиционирования курсора на его наименовании и нажатия клавиши ВВОД.
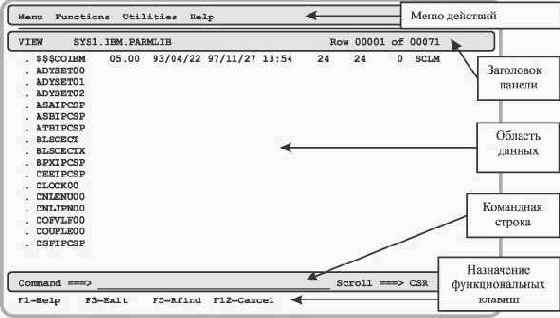
Рис. 5.32. Элементы панелей ISPF
Ниже уровня горизонтального меню располагается область заголовка панели, содержащая наименование панели и, где это необходимо, имя обрабатываемого набора данных и другую информацию. В этой же строке справа предусматривается поле для вывода так называемых "коротких сообщений" (short messages), используемых для отображения:
позиций текущей строки и колонки для функций просмотра и редактирования;признака успешного завершения выполняемой функции;сообщения об ошибке.
Отдельная строка панели используется для ввода команды или выбора необходимой функции. Это командная строка, которая отмечена ключевым словом Option или Command. Командная строка может размещаться как в верхней, так и в нижней части панели, в зависимости от настройки пользователя.
Как правило, в этой же строке справа от поля ввода команды располагается область, предназначенная для ввода и отображения шага перемещения содержимого панели при прокрутке. Эта область помечается ключевым словом Scroll.
Одна из строк верхней части панели резервируется для отображения так называемого "длинного сообщения" (long message), содержащего более полную информацию об ошибке. В обычном состоянии эта строка остается пустой или содержит часть отображаемых данных. При настройке ISPF/PDF существует возможность задать вывод длинного сообщения во всплывающем (popup) окне.
Нижние строки панели обычно используются для отображения информации о назначении программируемых функциональных клавиш (ПФК), используемых для быстрого ввода стандартных команд управления панелями (перемещение изображения, возврат, отмена, вызов справки и др.).
Основную часть панели занимает область данных (тело панели), которая служит для отображения значимой для пользователя информации, определяющей назначение (выполняемую функцию) данной панели.
Область данных может быть разделена на несколько подобластей по типу отображаемой информации или функциональному признаку.
В зависимости от структуры области данных в ISPF используются панели пяти основных типов:
панель выбора (меню);панель ввода данных;панель списка;информационная панель;панель просмотра/редактирования наборов данных.
В панели выбора область данных содержит нумерованный список предлагаемых функций (операций), расположенный вертикально. В некоторых случаях функции списка не нумеруются, а кодируются буквенными символами. Пользователь выбирает нужную функцию из списка путем ввода ее номера в поле Option и нажатия клавиши ВВОД. Типичным примером панели выбора является панель главного меню ISPF/PDF, представленная на рис. 5.31.
Следует отметить, что функции главного меню можно выбирать с помощью приема, получившего название point-and-shoot, что может быть переведено как "укажи (прицелься) и выстрели". Этот прием очень прост: пользователь должен установить курсор на названии функции и затем нажать клавишу ВВОД. Такой прием может применяться при работе с различными панелями.
Панели ввода служат для ввода и выбора значений исходных данных с помощью следующих элементов управления:
поле ввода/редактирования;переключатель;список выбора.
Поле ввода/редактирования данных определяет область панели, которая служит для ввода или корректировки значения какого-либо параметра непосредственно с клавиатуры. Характерный вид поля ввода/редактирования представлен на рис. 5.33a.
Переключатели (рис. 5.33b) служат для определения значений параметров, принимающих только два значения (да/нет, включено/выключено). Например, с помощью переключателя можно указать, следует ли выдавать дополнительное подтверждение при удалении набора данных. Как правило, утвердительное значение требует указания в поле переключателя символа "/", при отрицательном значении поле остается пустым.
Список выбора представляет собой горизонтально или вертикально расположенный нумерованный список возможностей или альтернатив и служит для выбора единственного варианта, который указывается в специальном поле в виде номера (или символа), соответствующего выбранному элементу списка (рис. 5.33с).
Элементы списка, недоступные для выбора в данный момент, отмечаются слева символом "*".
Рис. 5.33. Основные элементы управления панелей ввода данных
Во многих случаях поля панели ввода сохраняют ранее введенные значения или содержат значения, установленные по умолчанию при конфигурировании ISPF/PDF. Часто панель ввода включает элементы, характерные для панели выбора, например дополнительное меню функций. Для перемещения курсора только по предназначенным для ввода полям рекомендуется использовать клавишу табуляции (Tab) или перевода строки (Enter). После завершения ввода данных требуется нажать клавишу ВВОД, чтобы инициировать выполнение функции, связанной с данной панелью. В некоторых случаях при этом появляется новая панель. Пример панели ввода, использующей различные элементы управления (поля ввода, переключатели, списки), приведен на рис. 5.34.
Панели списка в основном предназначены для отображения наборов данных или разделов библиотек, хранящихся на устройствах внешней памяти, и служат для просмотра и выполнения различных операций над ними. Внешний вид такой панели на примере панели списка наборов данных приведен на рис. 5.35. Слева от элементов списка линией подчеркивания выделены поля ввода строчных команд. Эти поля предназначены для выполнения операций над выбранными элементами списка. Панель содержит также поле Command для ввода системных команд и поле Scroll для управления прокруткой списка в вертикальном и горизонтальном направлениях. В области коротких сообщений отображается диапазон номеров видимых на экране элементов списка.
Рис. 5.34. Панель настройки ISPF как пример панели ввода
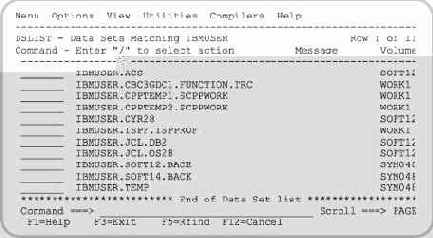
Рис. 5.35. Панель списка наборов данных
Информационные панели служат для отображения какого-либо текста и не включают полей ввода данных и выбора функций, кроме поля Command. Как правило, в виде информационных панелей отображаются справочные и обучающие текстовые данные.
Панель просмотра/редактирования данных связана с реализованным в ISPF/PDF текстовым редактором EDIT, который будет рассмотрен позднее.
Командный режим TSO/E
TSO/E является компонентом операционной системы MVS, обеспечивающим для множества пользователей возможность интерактивного совместного доступа к ресурсам мэйнфрейма при разработке и выполнении приложений и заданий, а также управлении данными. Для работы с подсистемой TSO/E необходим терминал типа 3270, подключенный к мэйнфрейму. Чаще всего в качестве терминала используют стандартный персональный компьютер (ПК) с установленной терминальной программой (например, IBM Personal Communication). Связь ПК с мэйнфреймом осуществляется по сети на основе протоколов TCP/IP или SNA.
Каждый пользователь TSO/E получает уникальный идентификатор (user ID) и пароль, устанавливаемые администратором RACF. Открытие сеанса работы производится по команде LOGON, которая требует ввода указанных и некоторых других атрибутов для авторизации и настройки пользовательской среды. Ввод команды LOGON приводит к созданию нового адресного пространства z/OS, в котором функционируют системные приложения поддержки диалогового сеанса и могут запускаться пользовательские приложения.
В рамках сеанса пользователь может выполнять интерактивные действия в стиле командной строки, используя специальный язык команд TSO. Приглашением к вводу команды обычно является выводимое на экран сообщение READY.
Команда TSO/E состоит из имени команды, за которым обычно следуют один или более операндов. Имя команды отделяется от первого операнда одним или несколькими пробелами. Операнды друг от друга отделяются пробелами или запятой. В качестве имен команд чаще всего используются подходящие англоязычные слова, соответствующие их функциональному назначению. Почти все команды и ключевые операнды команд TSO/E имеют дополнительные сокращенные имена, которые можно использовать наряду с полными именами. Перечень основных команд TSO/E с указанием выполняемых функций приведен в таблице 5.5.
| ALLOCATE | ALLOC | Распределение (создание) новых наборов данных |
| CALL | CALL | Загрузка и выполнение программ |
| CANCEL | CANCEL | Прерывание выполнения пакетного задания |
| DELETE | DEL | Удаление наборов данных или разделов библиотек |
| EDIT | E | Ввод и/или редактирование наборов данных |
| FREE | FREE | Освобождение ранее распределенных наборов данных |
| HELP | H | Получение информации о выполняемых функциях, синтаксисе и операндах команд, а также о сообщениях |
| LISTALC | LISTA | Вывод списка наборов данных, распределенных в текущем сеансе TSO/E |
| LISTCAT | LISTC | Вывод списка наборов данных, имена которых начинаются с префикса пользователя или наборов данных в личном каталоге |
| LISTDS | LISTD | Вывод списка атрибутов наборов данных |
| LOGOFF | LOGOFF | Завершение терминального сеанса TSO/E (выход из системы) |
| LOGON | LOGON | Начало терминального сеанса TSO/E (вход в систему) |
| OUTPUT | OUT | Вывод листинга задания |
| PRINTDS | PR | Печать набора данных на системном принтере |
| PROFILE | PROF | Просмотр и редактирование профиля пользователя |
| RECEIVE | RECEIVE | Получение отправленного сообщения или набора данных |
| RENAME | REN | Переименование каталогизированного набора данных или раздела библиотеки |
| RUN | R | Компиляция, загрузка и выполнение исходной программы из указанного набора данных |
| SEND | SE | Отправка сообщений другим пользователям TSO/E или системному оператору |
| SMCOPY | SMC | Копирование одного набора данных в другой |
| STATUS | ST | Проверка текущего состояния выполняемого задания |
| SUBMIT | SUB | Запуск пакетного задания на исполнение |
| TERMINAL | TERM | Просмотр и редактирование параметров терминала пользователя |
| TRANSMIT | XMIT | Отправка сообщений или наборов данных пользователям системы или других систем |
Операнды служат для указания информации, необходимой для выполнения команды, причем могут быть как позиционными, так и ключевыми. При вводе команд можно использовать как прописные, так и строчные буквы. Поддерживается два способа ввода команд, представленных на рис. 5.30 на примере команды RENAME (переименовать набор данных) [22]. Команда RENAME имеет два позиционных параметра: имя переименовываемого набора данных (здесь OLD.DATA) и новое имя, которое устанавливается для этого набора данных (NEW.DATA).

Рис. 5.30. Способы использования команд TSO/E
В первом случае команда вводится полностью со всеми требуемыми операндами, во втором вводится только имя команды, после чего система выдает пользователю запросы на ввод необходимых операндов (режим с подсказками).
Для начального знакомства с командами TSO/E удобно использовать команду HELP. Команда HELP без операндов выводит на экран перечень всех доступных команд:
HELP LANGUAGE PROCESSING COMMANDS: ASM INVOKE ASSEMBLER PROMPTER AND ASSEMBLER F COMPILER. CALC INVOKE ITF:PL/1 PROCESSOR FOR DESK CALCULATOR MODE. COBOL INVOKE COBOL PROMPTER AND ANS COBOL COMPILER. FORT INVOKE FORTRAN PROMPTER AND FORTRAN IV G1 COMPILER . . .
Пользователь может потребовать также вывести справку по любой команде, указав ее имя в качестве операнда команды HELP:
HELP RENAME
Такая справка содержит описание функции команды, ее синтаксиса и назначение каждого из операндов.
Помимо собственных команд TSO/E поддерживает возможность выполнения пользовательских приложений в двух режимах: интерактивном (Foreground) и фоновом (Background). В интерактивном режиме программа запускается по специальной команде (RUN или CALL) в адресном пространстве текущего пользовательского сеанса TSO/E. Процесс выполнения программы при этом полностью контролируется с пользовательского терминала, на который выдаются сообщения и результаты работы и с которого могут вводиться исходные данные. Пока выполняется интерактивная программа, пользователь не может задействовать терминал для другой работы.
Команда RUN служит для выполнения программ, представленных в исходном коде. При этом автоматически производится компиляция, редактирование связей, загрузка и исполнение. Однако для использования команды RUN необходимо, чтобы в системе были установлены соответствующие программные средства, включая компиляторы с различных языков программирования и редактор связей (Binder).
Команда CALL служит для загрузки и запуска подготовленных к выполнению программ, т.е. программ, представленных в виде загрузочного модуля. Это могут быть либо пользовательские прикладные программы, либо системные программы, такие как компиляторы или утилиты. Пользователь должен указать имя загрузочного модуля, которое должно соответствовать имени раздела библиотечного набора данных, например:
CALL 'USER5.MYPROG.LOADMOD(PROG3)'
или
CALL 'SYS1.LINKLIB(IEUASM)'
Использование апострофов позволяет отменить автоматическую модификацию имени набора данных, принятую в TSO/E по умолчанию и связанную с добавлением к имени старшего квалификатора, совпадающего с идентификатором пользователя.
Существует возможность передать программе параметры. Для этого необходимо ввести значения параметров, заключенные в апострофы, сразу же после имени набора данных:
CALL 'PROGRAM(MYPROG)' 'FIRST,SECOND'
Для выполнения программы в фоновом (пакетном) режиме необходимо составить задание с использованием языка управления заданиями JCL и разместить его в наборе данных. Задание можно передать на выполнение по команде SUBMIT:
SUBMIT 'U.JCLLIB.CNTL(JOB1)'
При этом задание передается подсистеме управления заданиями и будет выполнено в адресном пространстве инициатора JES. Результаты работы программы помещаются в набор данных SYSOUT, который можно просмотреть в любое время. В данном режиме пользователь может продолжать использовать терминал, не дожидаясь завершения выполнения задания.
В пакетном режиме следует выполнять программы, которые не используют средства диалога и могут потребовать значительного количества системных ресурсов и времени.
Такие программы нецелесообразно выполнять в интерактивном режиме, поскольку терминал не будет доступен для работы в течение длительного времени и пользователь вынужден будет пассивно дожидаться их завершения.
Когда задание направляется на выполнение, система присваивает ему идентификационный номер, ссылаясь на который можно получить информацию о текущем состоянии задания (команда STATUS), потребовать у системы выдать листинг, когда задание завершит работу (команда OUTPUT), а также в любой момент прервать выполнение задания (команда CANCEL).
Пользователю TSO/E предоставляется возможность создавать командные процедуры, используя специальные языки, такие как CLIST и REXX. Данные языки позволяют с помощью стандартных команд TSO/E, а также специальных операторов и встроенных функций, создавать интерпретируемые программы, которые можно запускать на выполнение непосредственно из командной строки. С помощью командных процедур можно работать с наборами данных в интерактивном режиме, настраивать и запускать пакетные задания, создавать диалоги ISPF.
Копирование строк (С)
Формат команды:
1) С[n] 2) СС
Строчная команда C (Copy) используется для копирования одной строки или строчного фрагмента в заданную строку (последовательность строк). Строчный фрагмент задается либо с помощью параметра n (количество строк), либо путем ввода команды СС в первой и последней строке фрагмента.
Совместно с командой С используются дополнительные строчные команды A или B, в точном соответствии с описанием, приведенным выше при рассмотрении команды M.
Пример копирования строки 4 в позицию после строки 1 с дублированием:
a20001 Это первая строка 000002 Это вторая строка 000003 Это третья строка с00004 Это четвертая строка 000005 Это пятая строка
Результат:
000001 Это первая строка 000002 Это четвертая строка 000003 Это четвертая строка 000004 Это вторая строка 000005 Это третья строка 000006 Это четвертая строка 000007 Это пятая строка
Начало и завершение работы с ISPF/PDF
Для доступа к системе z/OS с рабочей станции на базе ПК необходимо запустить программу IBM Personal Communications (или сокращенно PComm), воспользовавшись стандартными средствами Windows. Дальнейшие действия пользователя должны производиться по следующему сценарию.
В появившемся окне указать имя программы z/OS, с которой будет взаимодействовать пользователь, для чего в поле Application необходимо ввести tso и нажать клавишу ВВОД.В ответ на запрос
IKJ56700A ENTER USERID -
ввести личный идентификатор пользователя (Userid) в установленном системным администратором формате и нажать клавишу ВВОД. Например: USER1.
В окне PComm появится панель подключения к подсистеме TSO/E (рис. 5.39).
Рис. 5.39. Панель подключения к подсистеме TSO/E
В поле Password необходимо ввести пароль, установленный для данного пользователя, оставив прочие поля без изменения, и нажать клавишу ВВОД. После появления на экране сообщения "***" следует вновь нажать клавишу ВВОД.
Если идентификатор и пароль введены правильно, на экране появится панель главного меню TSO/E, обеспечивающего доступ к основным компонентам z/OS (рис. 5.40).
Рис. 5.40. Главное меню TSO/E
Для работы с компонентами z/OS требуется в поле командной строки (Option) ввести команду выбора в виде символического имени компонента, приведенного в крайнем левом столбце предлагаемого меню. Для работы с компонентом ISPF/PDF требуется ввести команду Р. При этом на экране терминала появится панель первичного (главного) меню ISPF/PDF, представленная на рис. 5.31, с которой и начинается сеанс работы.
При первом входе пользователя в систему создается специальный набор данных, называемый профилем пользователя (user profile). Этот набор данных служит для хранения сведений о пользователе, а также текущих значений параметров среды ISPF, которые определяют внешний вид панелей и особенности реализации некоторых функций, установленные пользователем. Каждый раз, когда пользователь открывает новый сеанс работы, эти значения автоматически активизируются.
Кроме того, в профиле сохраняются вводимые пользователем значения некоторых полей. Эти значения подставляются при повторном открытии панелей в качестве значений по умолчанию.
Состояние профиля постоянно обновляется в результате действий пользователя. В начале нового сеанса состояние профиля будет в точности таким, каким оно сложилось в момент завершения предыдущего.
Профиль пользователя включает следующие параметры:
характеристики терминала, определения функциональных клавиш, значения параметров скроллинга;параметры наборов данных печати и персонального журнала пользователя;параметры настройки текстового редактора (профиль редактирования);информация о распределяемых наборах данных;параметры настройки компиляторов для различных языков программирования;параметры менеджера сопровождения разработки программного обеспечения (SCLM);параметры JCL, используемые для выполняемых в пакетном режиме заданий, формируемых ISPF.
Перед началом работы рекомендуется произвести настройку некоторых параметров среды ISPF, определяющих условия работы пользователя и характеристики представления данных, включая:
характеристики терминала;параметры обработки наборов данных печати (LIST) и персонального журнала (LOG);назначение программируемых функциональных клавиш (ПФК);размещение командной строки на экране;характеристики списков наборов данных;параметры графической печати данных модуля GDDM;параметры режима отладки диалогов;используемые цветовые атрибуты изображения;значения элементов стандартных CUA-панелей;опции команды ENVIRON.
Функция 0 ISPF/PDF "Settings" позволяет просмотреть и установить значения перечисленных параметров. Изменения настроек остаются действительными до тех пор, пока не будут введены новые значения параметров (не только в текущем сеансе).
В состав ISPF входит компонент, получивший название Workstation Agent (WSA) ("агент рабочей станции"), который предназначен для использования диалогов ISPF в распределенной вычислительной среде в соответствии с технологией клиент-сервер.
С его помощью можно выполнять диалоги и отображать панели ISPF на рабочих станциях с использованием функций установленных на них операционных систем, разгружая таким образом мэйнфрейм, играющий роль сервера. WSA поддерживает OS/2, Microsoft Windows, AIX, HP-UX и Sun Solaris. Такой режим работы часто называют графическим (GUI mode), поскольку он использует возможности графического пользовательского интерфейса поддерживаемых WSA платформ. Например, в среде MS Windows панели ISPF превращаются в стандартные окна с привычными элементами управления (поля ввода, кнопки, списки, переключатели и т.п.) и реализуется полная поддержка мыши для управления интерфейсом (рис. 5.41).
Рис. 5.41. Графический интерфейс ISPF/PDF в режиме клиент-сервер
К особенностям реализации графического интерфейса по сравнению со стандартным режимом работы ISPF относятся:
функции клавиши ВВОД начинает исполнять клавиша Enter в основном блоке клавиатуры ПК;меню действий полностью управляется мышью и поддерживает "горячий" вызов с помощью клавиш Alt+символ;функциональные клавиши и поля типа point-and-shoot отображаются в виде кнопок;поля ввода отображаются в виде стандартных полей ввода текста Windows (text box);переключатели отображаются в виде элементов интерфейса Windows типа check Box;списки выбора отображаются в виде так называемых радиокнопок (radio button);недоступные для выбора элементы меню, списков, кнопки выделяются серым цветом;команда разделения на логические экраны SPLIT создает отдельное окно и может выдаваться многократно.
Одно из важных преимуществ режима клиент-сервер заключается в возможности выполнять так называемое распределенное редактирование данных. Пользователь может применять любой текстовый редактор, установленный на рабочей станции, для редактирования наборов данных ISPF, и в то же время текстовый редактор ISPF может быть использован для редактирования файлов, размещенных на рабочей станции. Отметим, что WSA поддерживает распределенное редактирование как в графическом, так и в терминальном режиме работы ISPF.
Для завершения сеанса работы у пользователя есть несколько возможностей. Если пользователь не находится в режиме разделения экрана, то завершить сеанс работы с ISPF/PDF он может одним из следующих способов:
ввести команду END (F3) в главном меню;выбрать функцию Х главного меню (Exit - "Выход");ввести команду RETURN в главном меню. Ввод команды RETURN в главном меню аналогичен вводу функции Х;ввести команду "=Х" в любой панели ISPF/PDF.
После ввода одной из указанных команд на экране обычно отображается панель завершения сеанса, в которой пользователь может указать режимы обработки специальных наборов данных - набора данных печати (LIST) и персонального журнала (LOG). Набор данных печати заполняется пользователем в процессе работы всевозможной информацией: текстами исходных модулей программ, отчетами о выполнении программ и заданий, списками наборов данных и разделов библиотек и т.п. Вся выбранная пользователем для печати информация не выводится на принтер немедленно, а временно помещается системой в специальный набор данных печати (LIST data set), которому по умолчанию присваивается имя вида:
prefix.userid.SPFn.LIST
Здесь prefix - префикс для наборов данных, установленный в пользовательском профиле TSO, userid - идентификатор пользователя, с которым он открыл сеанс работы, n - целое число от 0 до 9. Если префикс совпадает с идентификатором пользователя, то квалификатор prefix не используется.
Аналогично формируется еще один временный набор данных, в котором отражается вся информация, фиксирующая основные действия пользователя. Такой набор данных называется персональным журналом пользователя (LOG data set) и имеет имя вида:
prefix.userid.SPFLOGn.LIST
Значения квалификаторов формируются так же, как для набора данных печати.
Панель завершения сеанса позволяет определить способ обработки персонального журнала и набора данных печати. На рис. 5.42 показан вариант панели завершения для случая, когда в ходе сеанса использовался только набор данных печати.
Если же во время сеанса использовались оба набора данных (LOG и LIST), отображается панель завершения, включающая списки вариантов обработки для обоих наборов.

Рис. 5.42. Панель завершения сеанса
На панели представлены следующие возможности по обработке набора данных печати:
Распечатать набор данных и удалить его.Удалить набор данных без вывода на печать.Сохранить набор данных без вывода на печать, использовать тот же самый набор данных в следующем сеансе работы.Сохранить набор данных без вывода на печать, в следующем сеансе работы создать новый набор данных печати.
Если эти наборы данных необходимо распечатать, то пользователь должен указать класс вывода SYSOUT или идентификатор печатающего устройства, а также информацию оператора задания JОВ для печати в пакетном режиме.
Задав способ обработки, необходимо нажать клавишу ВВОД для завершения сеанса ISPF/PDF и возврата в среду TSO/Е. Сеанс TSO/Е можно завершить, введя команду logoff или просто закрыв окно программы PComm.
Обзор функций просмотра
Как отмечалось выше, PDF располагает функциями просмотра данных в двух режимах, определяемых как VIEW и BROWSE. Режим VIEW полностью поддерживает все средства, используемые в режиме редактирования, за исключением команд сохранения результатов. При завершении просмотра данных в режиме VIEW любые произведенные изменения будут проигнорированы, а просматриваемый набор данных останется без изменений. В режиме просмотра BROWSE, в отличие от режима VIEW, не могут производиться действия, изменяющие просматриваемые данные. В то же время поддерживается ряд специальных команд для поиска строк и контекста, а также средства переключения в режимы редактирования и VIEW.
Компоненты просмотра поддерживают наборы данных с любым форматом записи (фиксированной, переменной или неопределенной длины), блокированные или неблокированные (RЕСFМ=F,V,U,FВ,VВ), с длиной записи (LRECL) не превышающей 32 КB.
Доступ к режимам просмотра производится либо через функцию 1 (View) главного меню ISPF/PDF, либо с помощью утилит Library (3.1) или утилиты Dslist (3.4).
В первом случае на экране представляется входная панель View (рис. 5.57). Пользователь должен указать имя библиотеки ISPF или произвольного набора данных, серийный номер тома (если набор данных не каталогизирован) и пароль (если набор данных защищен паролем). Для библиотечных наборов данных дополнительно можно указать имя раздела, который пользователь желает просмотреть. Если имя раздела не указано, то будет выдан список разделов данной библиотеки, из которого пользователь должен выбрать тот раздел, который он хочет просмотреть. После нажатия на клавишу ВВОД будет открыта панель просмотра. Следует обратить внимание на положение переключателя Browse Mode. Если в этом поле введен символ "/", то будет включен режим BROWSE, в противном случае - режим VIEW.
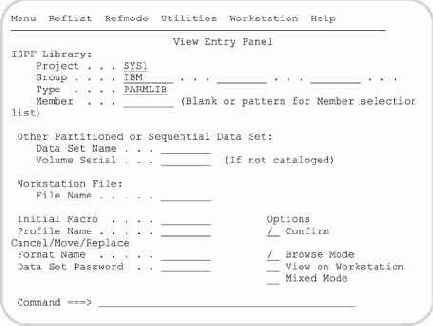
Рис. 5.57. Входная панель режима просмотра VIEW
Структура панели просмотра точно такая же, как и у панели редактирования. Просматриваемый текст можно прокручивать стандартными способами.
Для завершения просмотра следует ввести команду END (F3). После просмотра отмеченного раздела пользователь снова увидит на терминале список разделов.
В режиме BROWSE пользователь может применять следующие функциональные команды:
LОСАTЕ - поиск строк;COLUMNS - отображение шкалы колонок;RESET - отмена отображения шкалы колонок;FIND - поиск цепочки символов;CAPS - установка режима прописных букв;НЕХ - установка режима отображения символов в шестнадцатеричном формате;EDIT - переключение в режим редактирования;VIEW - переключение в режим просмотра VIEW;SUBMIT - запуск просматриваемого задания на выполнение.
Большинство из представленных команд совпадают по назначению с соответствующими командами редактора EDIT. Здесь будет рассмотрена только команда поиска строк LОСАTЕ.
По команде LOCATE (сокращенно LOC) строка текстового набора данных, указанная в команде, появляется вверху экрана. Строка может быть указана либо с помощью относительного номера, либо с помощью предварительно определенной метки. Во время просмотра текущее положение окна экрана определяется с помощью номера строки и колонки, которые отображаются в верхнем правом углу экрана. Номер строки относится к первой строке данных, отображенных на экране, т.е. к первой строке после двух строк заголовка панели. Этот номер указывает относительное положение строки в потоке данных и не имеет никакого отношения к номерам следования, которые могут содержаться внутри данных. Строка с сообщением "начало данных" рассматривается как строка с относительным номером 0.
Формат команды LOCATE:
LОСАTЕ относительный_номер_строки LОСАTЕ метка
Пользователь должен ввести либо относительный номер строки, либо метку в качестве операнда.
Относительный_номер_строки - указывает номер строки относительно начала данных. Относительный номер строки отображается в правом верхнем углу экрана.
метка - указывает предварительно определенную метку строки. Для того чтобы присвоить строке метку, необходимо добиться того, чтобы она была первой строкой данных на экране, и ввести в области ввода команд метку, представляющую собой точку, за которой следует до семи алфавитно-цифровых символов.Например:
DАTА5
Метка, определенная таким образом, является внутренним символическим именем, которое присваивается первой строке данных экрана. При определении метки точка обязательна. Однако при ссылке на метку в команде LOCATE, кроме случая, когда метка начинается с цифры, точку можно не ставить.
Однажды определенная метка может использоваться в качестве операнда в последующих командах LOCATE. Более позднее определение метки замещает более раннее ее определение. Одной и той же строке может быть присвоено несколько меток. При завершении функции просмотра метки не сохраняются.
Основные приемы работы в ISPF
Рассмотрим основные приемы работы в ISPF, которые чаще всего применяют при использовании функциональных панелей. К таким приемам относятся управление курсором и скроллинг (прокрутка экрана), управление терминалом, вызов справки, использование команд TSO/E. При описании некоторых команд ISPF в скобках будет указываться стандартная функциональная клавиша, которую можно использовать для вызова команды.
Стандартным средством управления курсором служат клавиши-"стрелки", с помощью которых курсор может быть установлен в произвольную позицию панели. Однако в ISPF поддерживаются команды и специальные клавиши, позволяющие повысить эффективность этой процедуры. Удобным средством управления курсором является команда ACTION (F10), которая служит для "быстрого" перемещения курсора в область горизонтального меню действий, а при повторном нажатии - обратно в текущую позицию панели.
Ряд панелей ISPF, включая панели списка, просмотра и редактирования, поддерживают средства прокрутки содержимого панели (скроллинг), которые позволяют перемещать информацию на экране вверх, вниз, вправо и влево. Для скроллинга предназначены четыре команды: UP (вверх), DOWN (вниз), LEFT (влево), RIGHT (вправо), которые обычно привязываются к функциональным клавишам F7, F8, F10, F11 соответственно. Во всех случаях, когда прокрутка допускается, должна быть задана величина (шаг) перемещения данных, то есть число строк или колонок, перемещаемых при однократном использовании команды перемещения. Величина перемещения определяется по значению поля Scroll текущей панели, которое может принимать следующие значения:
число от 1 до 9999 - указывает количество строк или колонок для перемещения;PAGE - указывает перемещение на страницу (размер страницы соответствует размеру логического экрана);DATA - то же, что и PAGE, но на одну строку меньше.HALF - указывает перемещение на полстраницы;MAX - указывает перемещение к концу, началу, левой или правой границе данных, в зависимости от конкретно используемой команды перемещения;CSR - указывает перемещение, основанное на текущей позиции курсора (строка или колонка, определенные курсором, сдвигаются вниз, вверх, к левой или правой границе экрана, в зависимости от используемой команды перемещения).
Для быстрого перемещения в начало и конец данных, представленных на панели, поддерживаются две специальные команды: TOP (то же, что и команда UP MAX) и BOTTOM (то же, что и команда DOWN MAX).
Следует отметить, что в некоторых панелях, содержимое которых не умещается в пределах одного физического экрана (по вертикали), в правом верхнем углу выдается сообщение More + или More - . Это означает, что для просмотра полного содержимого панели следует воспользоваться командами прокрутки DOWN (F8) и UP (F7) соответственно.
Группа команд управления терминалом предназначена для настройки параметров, определяющих внешний вид и структуру экрана терминала. В частности, команда PFSHOW ON включает режим отображения в нижней части экрана списка используемых в текущей панели программируемых функциональных клавиш. При желании по команде PFSHOW OFF данный режим отменяется.
Особую роль в организации работы пользователя ISPFD/PDF играет режим разделения экрана, позволяющий делить экран терминала по горизонтали на несколько логических экранов. Логические экраны рассматриваются как независимые терминалы, при этом в каждый момент времени лишь один из них является активным, то есть воспринимает ввод с клавиатуры. Любые действия пользователя и системные прерывания рассматриваются, как имеющие место для активного логического экрана.
Чтобы разделить экран на два логических экрана, необходимо установить курсор в строке, которая будет являться линией разделения, и нажать функциональную клавишу, определенную как команда SPLIT (обычно это F2). Строка, на которой находился курсор, становится линией разделения экранов и обозначается рядом точек, как это представлено на рис. 5.38. На практике наиболее удобным является размещение линии разделения в самой верхней или самой нижней строке экрана терминала. В этом случае видимой остается наибольшая часть активного логического экрана.
Рис. 5.38. Режим разделения на логические экраны
Верхний логический экран сохранит часть строк текущей панели, которая была активна в момент разделения.
На нижнем логическом экране появится главное меню TSO/E (точнее, только часть его строк). Пользователь в любой момент может переопределить линию разделения экрана с помощью команды SPLIT или клавиши F2. Существует возможность создания более чем двух (но не более 8) перекрывающихся логических экранов (команда SPLIT NEW).
Для активизации (выбора) логического экрана необходимо использовать клавиши управления курсором или команду SWAP (F9).
Для того чтобы выйти из режима разделения экрана, нужно завершить сеанс ISPF/PDF на одном из логических экранов путем ввода команды END или RETURN в панели главного меню или путем ввода команды "=X" в любой другой панели. Оставшийся логический экран примет стандартный вид, "расширившись" до полного физического экрана.
ISPF/PDF обеспечивает возможность ввода и выполнения команд и процедур TSO/E из любой панели с помощью системной команды TSO, параметром которой является текст стандартной команды TSO/E. Например:
Command===" TSO RENAME OLD.DSET NEW.DSET
Ряд команд TSO, в том числе LOGON, LOGOFF, ISPF, PDF, ISPSTART и TEST, использовать таким образом запрещено.
Следует отметить, что в ISPF реализован специальный режим ввода команд TSO/E (функция 6 главного меню ISPF/PDF). В этой панели команды TSO можно вводить непосредственно (не предваряя их символами TSO) в поле ввода, размещенное в верхней части панели. В нижней части панели представлен список последних десяти команд. Любую из этих команд можно вызвать на повторное исполнение по методу "point-and-shoot", т.е. установив курсор на соответствующую команду и нажав клавишу ВВОД.
Для вызова справки о командах, функциях, панелях ISPF/PDF или уточняющей информации о коротких сообщениях, отображенных в правом верхнем углу экрана, служит команда HELP (F1). Информация, как правило, представляется во всплывающем (popup) окне, закрытие которого производится командой END (F3 ). Состояние активной панели при этом не изменяется. Если панель содержит короткое сообщение, по команде HELP можно получить развернутый комментарий к выданному сообщению.Если этой информации пользователю недостаточно, то он может получить дополнительные данные путем повторного ввода этой же команды.
Следует отметить, что любая функциональная панель ISPF/PDF дает возможность вызова справки с помощь меню действий Help.
Переключение панелей (средства навигации в ISPF)
Множество панелей ISPF образует иерархическую структуру. На вершине иерархии находится панель главного меню ISPF/PDF. Выбор одной из функций меню приводит к переходу к панели нижнего уровня иерархии [25].
Панель нижнего уровня в свою очередь может оказаться панелью выбора и привести пользователя на следующий уровень иерархии и т.д., пока наконец на определенном уровне не будет достигнута требуемая функциональная панель. Завершение работы с выбранной функцией обеспечивает закрытие текущей панели и, как правило, возврат в старшую по иерархии панель. Таким образом, для выполнения некоторой задачи необходимо пройти определенный путь по системе панелей меню. Рассмотрим средства переключения панелей в ISPF, представленные на рис. 5.37.
Рис. 5.37. Средства навигации в ISPF/PDF
Выбор функций ISPF может осуществляться четырьмя способами, которые определяют следующим образом:
последовательный переход;прямой переход вперед;произвольный прямой переход;переход с помощью меню действий (вложенные команды).
Последовательный переход осуществляется из панели выбора любого уровня в "дочернюю" панель, определенную в меню выбора. Для такого перехода пользователь должен ввести номер панели или символьный код в поле Option и нажать клавишу ВВОД. Обратный переход в старшую по иерархии панель осуществляется по команде END или путем нажатия функциональной клавиши F3. Еще одна команда RETURN служит для возврата сразу в главное меню ISPF/PDF из любой активной панели.
Прямой переход вперед - прием, позволяющий с уровня панели главного меню ISPF непосредственно выбирать функцию любого из нижних уровней иерархии путем ввода цепочки значений номеров, разделенных точкой. Например, указав в поле Option панели главного меню
Option . . . 3.1
пользователь перейдет к панели, реализующей функцию 1, определенную в панели выбора 3.
Произвольный прямой переход позволяет переходить из одной активной панели в другую с общим первичным меню, минуя отображение главного меню. Такой прием реализуется следующим образом.
В командной строке любой панели или в любом поле ввода пользователь набирает знак "равно" (=), за которым сразу же указывает номер требуемой функции и затем нажимает клавишу ВВОД. Например, предположим, что пользователь работает с функцией редактирования (2) и желает задействовать утилиту обслуживания библиотек (функция 3.1). Для этого он должен ввести:
Command ===" =3.1
Эти действия вызовут завершение функции редактирования, и на экране появится панель функции обслуживания библиотек. Выполнение идет так, как если бы пользователь последовательно вводил команду END для возврата к главному меню, а затем выбрал команду 3.1.
Произвольный прямой переход удобно использовать также для быстрого завершения работы ISPF/PDF в любой "точке". Для этого достаточно ввести команду "=X", что эквивалентно выбору функции X ("Выход") в главном меню.
Прямой переход с помощью меню действий основан на использовании горизонтального меню панели, с помощью которого реализуется доступ к различным функциям ISPF. В отличие от командного способа переключения панелей, при завершении работы с функцией, выбранной с помощью меню, пользователь вновь попадает в панель, которая была активна в момент выбора. Эта особенность позволяет реализовать прием, получивший название "вложенные команды" (command nesting). Используя меню действий можно, не завершая текущей функции ISPF, перейти к выполнению другой функции, а затем вновь вернуться к текущей.
Перемещение строк (M)
Формат команды:
1) M[n] 2) MM
Строчная команда M (Move) используется для перемещения одной строки или строчного фрагмента в заданную строку (последовательность строк). Строчный фрагмент задается либо с помощью параметра n (количество строк), либо путем ввода команды MM в первой и последней строке фрагмента.
Совместно с командой M используются дополнительные строчные команды A (After) или B (Before) для определения новой (целевой) позиции перемещаемых данных.
Строчная команда A определяет строку, после которой требуется поместить перемещаемые строки, и имеет формат:
A[n]
Параметр n задает коэффициент повторения (дублирования) перемещаемых строк.
Строчная команда B определяет строку, перед которой требуется поместить перемещаемые строки, и имеет формат:
B[n]
Параметр n также задает коэффициент повторения (дублирования) перемещаемых строк.
Таким образом, для перемещения строк необходимо:
определить перемещаемую строку или строчный фрагмент с помощью команды M (или MM);определить целевую позицию для перемещаемых данных с помощью команды A или B, возможно, с указанием количества копий;нажать клавишу ВВОД
Пример перемещения строчного фрагмента (строки 4 и 5) в позицию перед строкой 1:
b00001 Это первая строка 000002 Это вторая строка 000003 Это третья строка m20004 Это четвертая строка 000005 Это пятая строка 000006 Это шестая строка
Результат:
000001 Это четвертая строка 000002 Это пятая строка 000003 Это первая строка 000004 Это вторая строка 000005 Это третья строка 000006 Это шестая строка
Простые средства ввода и редактирования текста
Если для редактирования открывается новый набор данных или раздел библиотечного набора данных, то панель редактора выглядит, как показано на рис. 5.56 ("пустая" панель).
Ввод текста производится в строку, следующую за строкой Top of Data, начиная с 8-й колонки экрана, при этом 7-я колонка, отделяющая область данных от поля нумерации, обязательно должна оставаться пустой. Попытка ввода в 7-ю колонку приводит к блокировке клавиатуры, после чего требуется нажимать клавишу СБРОС. Переход на новую строку производится путем перемещения курсора либо клавишами-стрелками, либо нажатием клавиши ПЕРЕВОД СТРОКИ. При использовании стандартной клавиатуры персональных ЭВМ в качестве такой клавиши используется Enter. Посимвольное редактирование вводимого текста осуществляется стандартными клавишами вставки (Insert) и удаления (Delete).

Рис. 5.56. Начальное состояние панели редактирования
После того, как текст сформирован, следует нажать клавишу ВВОД. Это приведет к автоматическому формированию номеров строк введенного текста, однако не приведет к его сохранению.
Если в конце строк текста остается не заполненное символами пространство, редактор может автоматически заполнить его пробелами или оставить пустым, в зависимости от значения параметра NULLS текущего профиля редактирования. Если NULLS в состоянии ON, это значит, что "хвосты" строк не заполняются и, таким образом, разрешена вставка новых символов в незаполненное пространство. Если NULLS в состоянии OFF, то строки дополняются пробелами и вставка новых символов блокируется, пока не будет удалено некоторое количество дополнительных пробелов. Для изменения текущего значения параметра NULLS можно воспользоваться командой NULLS OFF или NULLS ON, которая вводится в командной строке.
Для сохранения текста без выхода из режима редактирования следует воспользоваться функциональной командой редактора SAVE, не имеющей дополнительных операндов. Команда SAVE записывает данные в тот же набор данных, из которого они были выбраны для редактирования.
Для последовательных наборов данных перезаписывается весь набор данных. Если набор данных библиотечный, то раздел переписывается с тем же именем раздела и статистическая информация библиотеки автоматически обновляется, если установлен режим STATS ON.
При установленных режимах нумерации (NUMBER ON) и автоматической пepeнyмepaции (AUTONUM ONM) данные автоматически перенyмepoвывaютcя перед сохранением.
Если при перезаписи данных происходит ошибка ввoдa-вывoдa или недостаточно памяти для записи данных, в верхнем правом углу панели отображается сообщение с выдачей звукового сигнала. Когда при сохранении получено сообщение о нехватке памяти в наборе данных, пользователь может установить режим разделения экрана (SPLIT, F2) и попытаться решить проблему путем сжатия библиотечного набора данных или удаления и перераспределения последовательного набора данных, а затем повторно сохранить данные по команде SAVE, вернувшись в панель редактирования. Можно также попытаться сохранить данные в другом наборе данных или в другом разделе библиотечного набора данных, пользуясь командами CREATE или REPLACE.
У пользователя есть возможность отменить ошибочно выполненные действия с помощью команды UNDO, не имеющей операндов. Каждый раз при вводе команды UNDO отменяется одна предыдущая операция. Операцией считаются все действия, произведенные пользователем между двумя последовательными нажатиями на клавишу ВВОД или какую-либо функциональную клавишу. Отмена операций может быть продолжена вплоть до последней выполненной команды сохранения данных или до начала сеанса редактирования.
Чтобы использовать команду UNDO, необходимо предварительно настроить параметры профиля редактирования RECOVERY и SETUNDO, которые позволяют определить, где будет производиться временное хранение выполненных изменений в данных, c целью их дальнейшего использования для восстановления.
В частности, команда RECOVERY ON устанавливает режим сохранения изменений в файле, что позволяет автоматически восстанавливать содержимое редактируемого текста даже при возникновении системных сбоев и ошибок, при потере связи и срыве пользовательского сеанса и других неприятностях.
Меню действий панели редактирования является еще одним средством выполнения различных команд и настроек, связанных с работой редактора, а также служит для доступа к стандартным функциям ISPF/PDF.
Пользователь может завершить сеанс редактирования либо с сохранением, либо без сохранения внесенных в текст изменений. В первом случае следует использовать системные команды END (F3) или RETURN (F4), которые автоматически вызывают команду сохранения SAVE и производят запись данных в набор данных печати ISPF/PDF (если установлены режимы автоматической записи AUTOSAVE ON и AUTOLIST ON).
Для завершения сеанса редактирования без сохранения измененных данных используется не имеющая операндов функциональная команда CANCEL или CAN. Эта команда позволяет аннулировать все выполненные изменения. При использовании команды CANCEL автоматическая запись данных в набор данных печати ISPF/PDF не производится даже в том случае, если установлен режим автоматической записи.
Теперь рассмотрим некоторые наиболее важные средства редактирования текста, основанные на применении строчных команд. В общем виде строчные команды состоят, как правило, из не более чем двухсимвольного имени и могут включать один целочисленный параметр. Обобщенный формат строчной команды выглядит так:
имя[число]
Как это принято, квадратные скобки говорят о необязательном присутствии параметра. Имя команды разрешается вводить как строчными, так и прописными буквами. Oднocимвoльныe строчные команды выполняют операции для отдельных строк, в которых они указаны. Например, строчная команда D используется для удаления строки, I - для вставки пустой строки, R - для дублирования (повторения) строки, M - для перемещения строки. Если вслед за строчной командой указано число, то оно задает количество строк, которые должны быть обработаны, начиная с указанной. Двyxcимвoльныe команды оперируют группами строк (строчными фрагментами). Например, двyxcимвoльнaя строчная команда DD указывается в первой и последней строке удаляемого строчного фрагмента.
Ввод строчной команды может производиться начиная с любой позиции поля нумерации, например:
D00005 или 00D005 или 00000D
Пользователь может указать одновременно несколько строчных команд в различных строках. Для перемещения курсора к полю строчных команд следующей строки можно использовать клавишу ПЕРЕВОД СТРОКИ (Enter). Активизация действия всех строчных команд происходит по нажатию клавиши ВВОД.
В связи с тем что строчные команды вводятся поверх номеров строк, в некоторых случаях введенная команда может трактоваться неоднозначно. Так, в следующем примере:
0316000 . . . . . . . . . . . . . . . . R317000 . . . . . . . . . . . . . . . . 0318000 . . . . . . . . . . . . . . . .
неясно, ввел ли пользователь команду R для повторения строки с номером 317000 или, например, команду R3 для повторения данной строки три раза. B таких случаях по умолчанию предполагается, что введена команда без параметра, указывающего количество строк, то есть R.
Если же пользователю в данной ситуации необходимо повторить строку три раза (R3), он должен выполнить одно из следующих действий (на выбор):
переместить курсор в позицию, непосредственно следующую за командой R3:
R31700 указать один или более пробелов, следующих за командой R3:
R3 700
При вводе нескольких строчных команд их обработка производится последовательно от начала и до конца текста. B этом случае могут быть обнаружены синтаксические ошибки, а также противоречия между некоторыми командами, что приводит к появлению соответствующих сообщений. Сначала отображается только сообщение о первой обнаруженной ошибке. После того как пользователь исправит ошибку, обработка может быть продолжена.
Самый простой способ исправления ошибок реализуется вводом команды RESET, которая очищает поле ввода строчных команд, и повторным вводом требуемых команд. Пользователь может вводить некоторые строчные команды в строках, содержащих сообщения Top of Data ("начало данных") и Bottom of Data) ("окончание данных"), замещая звездочки, содержащиеся в первых шести позициях в начале строки.
Для строки " начало данных" такими строчными командами являются: I (вставка строк), A (начальная позиция копирования или перемещения строк) и TE (ввод текста). В строке "окончание данных" может быть использована только команда B (конечная позиция копирования или перемещения строк).
Для создания простых текстовых данных, например заданий JCL, исходных программ на каком-либо языке программирования достаточно использовать лишь небольшую часть возможностей редактора EDIT. В первую очередь речь пойдет о средствах, базирующихся в основном на применении следующих строчных команд [25]:
I - вставить пустую строку;D - удалить строку;R - дублировать строку;C - копировать строку;M - переместить строку;A, B - указатели целевой строки для копирования (перемещения) (A - после указанной строки, B - до указанной строки).
Кроме того, здесь будут представлены средства копирования и перемещения данных между редактируемым текстом и другими наборами данных или разделами, основанные на применении команд редактора CREATE, REPLACE, MOVE и COPY.
Для последовательных наборов данных перезаписывается весь набор данных. Если набор данных библиотечный, то раздел переписывается с тем же именем раздела и статистическая информация библиотеки автоматически обновляется, если установлен режим STATS ON.
При установленных режимах нумерации (NUMBER ON) и автоматической пepeнyмepaции (AUTONUM ONM) данные автоматически перенyмepoвывaютcя перед сохранением.
Если при перезаписи данных происходит ошибка ввoдa-вывoдa или недостаточно памяти для записи данных, в верхнем правом углу панели отображается сообщение с выдачей звукового сигнала. Когда при сохранении получено сообщение о нехватке памяти в наборе данных, пользователь может установить режим разделения экрана (SPLIT, F2) и попытаться решить проблему путем сжатия библиотечного набора данных или удаления и перераспределения последовательного набора данных, а затем повторно сохранить данные по команде SAVE, вернувшись в панель редактирования. Можно также попытаться сохранить данные в другом наборе данных или в другом разделе библиотечного набора данных, пользуясь командами CREATE или REPLACE.
У пользователя есть возможность отменить ошибочно выполненные действия с помощью команды UNDO, не имеющей операндов. Каждый раз при вводе команды UNDO отменяется одна предыдущая операция. Операцией считаются все действия, произведенные пользователем между двумя последовательными нажатиями на клавишу ВВОД или какую-либо функциональную клавишу. Отмена операций может быть продолжена вплоть до последней выполненной команды сохранения данных или до начала сеанса редактирования.
Чтобы использовать команду UNDO, необходимо предварительно настроить параметры профиля редактирования RECOVERY и SETUNDO, которые позволяют определить, где будет производиться временное хранение выполненных изменений в данных, c целью их дальнейшего использования для восстановления.
В частности, команда RECOVERY ON устанавливает режим сохранения изменений в файле, что позволяет автоматически восстанавливать содержимое редактируемого текста даже при возникновении системных сбоев и ошибок, при потере связи и срыве пользовательского сеанса и других неприятностях.
Меню действий панели редактирования является еще одним средством выполнения различных команд и настроек, связанных с работой редактора, а также служит для доступа к стандартным функциям ISPF/PDF.
Пользователь может завершить сеанс редактирования либо с сохранением, либо без сохранения внесенных в текст изменений. В первом случае следует использовать системные команды END (F3) или RETURN (F4), которые автоматически вызывают команду сохранения SAVE и производят запись данных в набор данных печати ISPF/PDF (если установлены режимы автоматической записи AUTOSAVE ON и AUTOLIST ON).
Для завершения сеанса редактирования без сохранения измененных данных используется не имеющая операндов функциональная команда CANCEL или CAN. Эта команда позволяет аннулировать все выполненные изменения. При использовании команды CANCEL автоматическая запись данных в набор данных печати ISPF/PDF не производится даже в том случае, если установлен режим автоматической записи.
Теперь рассмотрим некоторые наиболее важные средства редактирования текста, основанные на применении строчных команд. В общем виде строчные команды состоят, как правило, из не более чем двухсимвольного имени и могут включать один целочисленный параметр. Обобщенный формат строчной команды выглядит так:
имя[число]
Как это принято, квадратные скобки говорят о необязательном присутствии параметра. Имя команды разрешается вводить как строчными, так и прописными буквами. Oднocимвoльныe строчные команды выполняют операции для отдельных строк, в которых они указаны. Например, строчная команда D используется для удаления строки, I - для вставки пустой строки, R - для дублирования (повторения) строки, M - для перемещения строки. Если вслед за строчной командой указано число, то оно задает количество строк, которые должны быть обработаны, начиная с указанной. Двyxcимвoльныe команды оперируют группами строк (строчными фрагментами). Например, двyxcимвoльнaя строчная команда DD указывается в первой и последней строке удаляемого строчного фрагмента.
Ввод строчной команды может производиться начиная с любой позиции поля нумерации, например:
D00005 или 00D005 или 00000D
Пользователь может указать одновременно несколько строчных команд в различных строках. Для перемещения курсора к полю строчных команд следующей строки можно использовать клавишу ПЕРЕВОД СТРОКИ (Enter). Активизация действия всех строчных команд происходит по нажатию клавиши ВВОД.
В связи с тем что строчные команды вводятся поверх номеров строк, в некоторых случаях введенная команда может трактоваться неоднозначно. Так, в следующем примере:
0316000 . . . . . . . . . . . . . . . . R317000 . . . . . . . . . . . . . . . . 0318000 . . . . . . . . . . . . . . . .
неясно, ввел ли пользователь команду R для повторения строки с номером 317000 или, например, команду R3 для повторения данной строки три раза. B таких случаях по умолчанию предполагается, что введена команда без параметра, указывающего количество строк, то есть R.
Если же пользователю в данной ситуации необходимо повторить строку три раза (R3), он должен выполнить одно из следующих действий (на выбор):
переместить курсор в позицию, непосредственно следующую за командой R3:
R31700 указать один или более пробелов, следующих за командой R3:
R3 700
При вводе нескольких строчных команд их обработка производится последовательно от начала и до конца текста. B этом случае могут быть обнаружены синтаксические ошибки, а также противоречия между некоторыми командами, что приводит к появлению соответствующих сообщений. Сначала отображается только сообщение о первой обнаруженной ошибке. После того как пользователь исправит ошибку, обработка может быть продолжена.
Самый простой способ исправления ошибок реализуется вводом команды RESET, которая очищает поле ввода строчных команд, и повторным вводом требуемых команд. Пользователь может вводить некоторые строчные команды в строках, содержащих сообщения Top of Data ("начало данных") и Bottom of Data) ("окончание данных"), замещая звездочки, содержащиеся в первых шести позициях в начале строки.
Для строки " начало данных" такими строчными командами являются: I (вставка строк), A (начальная позиция копирования или перемещения строк) и TE (ввод текста). В строке "окончание данных" может быть использована только команда B (конечная позиция копирования или перемещения строк).
Для создания простых текстовых данных, например заданий JCL, исходных программ на каком-либо языке программирования достаточно использовать лишь небольшую часть возможностей редактора EDIT. В первую очередь речь пойдет о средствах, базирующихся в основном на применении следующих строчных команд [25]:
I - вставить пустую строку;D - удалить строку;R - дублировать строку;C - копировать строку;M - переместить строку;A, B - указатели целевой строки для копирования (перемещения) (A - после указанной строки, B - до указанной строки).
Кроме того, здесь будут представлены средства копирования и перемещения данных между редактируемым текстом и другими наборами данных или разделами, основанные на применении команд редактора CREATE, REPLACE, MOVE и COPY.
Работа с пакетными заданиями в ISPF/PDF
Как отмечалось ранее, для выполнения программы в пакетном режиме необходимо составить задание с использованием языка управления заданиями JCL. Запустив задание в пакетном режиме, пользователь может продолжать использовать терминал, не дожидаясь завершения выполнения программы. Результаты работы программы и системные сообщения помещаются в системный выходной набор данных (SYSOUT), который можно просмотреть в любое время после завершения задания.
Текст задания может размещаться в последовательном наборе данных или разделе библиотеки. При этом наборы данных должны иметь длину логических записей (LRECL) 80 байт, а формат логических записей (RECFM) - блокированный фиксированной длины (FB).
Отметим, что при запуске заданий на выполнение в один набор данных разрешается включать более одного задания. При этом можно опустить оператор JOB для первого задания, но все остальные задания должны начинаться с собственного оператора JOB. Несмотря на то что для передачи на выполнение всех заданий, входящих в один набор данных, используется одна команда SUBMIT, можно управлять каждым заданием отдельно. При передаче на выполнение одной командой SUBMIT более одного задания следует иметь в виду, что, если z/OS обнаружит ошибку при выполнении первого задания, второе задание не будет выполняться.
Подготовив JCL задание в надлежащем виде, пользователь может затем направить его на выполнение одним из трех способов:
из панели редактирования или просмотра набора данных (раздела), содержащего текст задания с помощью функциональной команды SUBMIT или SUB;из панели списка разделов библиотечного набора данных с помощью строчной команды J;с помощью команды TSO SUBMIT, например:
TSO SUBMIT 'USER5.JCL(JOB1)'
Если задание принято к выполнению, на терминале появится сообщение
IKJ56250I JOB job_name (job_id) submitted ***
где job_name - имя задания, введенное пользователем, job_id - уникальный идентификатор задания в формате JOBXXXXX, назначенный подсистемой ввода заданий JES (X - десятичная цифра).
Пользователь должен ответить нажатием клавиши ВВОД, оставаясь в том режиме, из которого производился запуск.
Для просмотра текста отчета о выполненном задании (листинга) можно воспользоваться специальной утилитой ISPF/PDF Outlist (3.8). Утилита Outlist предназначена для просмотра, вывода на печать и удаления листинга выполненного пакетного задания. Внешний вид панели утилиты представлен на рис. 5.58.
Рис. 5.58. Панель утилиты Outlist
С помощью данной утилиты можно отобрать интересующие пользователя задания по их идентификационным признакам и затем выполнить одно из следующих действий:
L - отобразить список выполненных заданий, находящихся в выходной очереди;D - удалить задание из выходной очереди;P - вывести отчет в набор данных печати и удалить из выходной очереди;R - перевести задание в другую выходную очередь (новый выходной класс задается в поле New Output class);пробел - показать отчет о выполненном задании.
Отбор заданий, листинги которых интересуют пользователя, осуществляется по трем параметрам, задаваемым в соответствующих полях панели:
Jobname - имя задания, указанное в операторе JOB;Class - выходной класс задания, определяющий способ обработки листинга;JobID - идентификатор, присваиваемый заданию в момент запуска.
Для просмотра списка выполненных заданий следует ввести команду L. Список выдается в режиме TSO и включает все находящиеся в выходной очереди задания, имя которых совпадает с именем, указанным в поле Jobname, например:
IKJ56192I JOB USER1A(JOB00468) ON OUTPUT QUEUE IKJ56192I JOB USER1A(JOB00469) ON OUTPUT QUEUE IKJ56192I JOB USER1В(JOB00470) ON OUTPUT QUEUE IKJ56192I JOB USER1A(JOB00471) ON OUTPUT QUEUE
Если при выдаче списка на экране появляются звездочки (***), следует нажать клавишу ВВОД для продолжения вывода.
Для просмотра листинга одного из представленных в списке заданий необходимо ввести имя задания или его идентификатор в соответствующие поля панели, причем идентификатор указывать обязательно в случае, если запущено несколько заданий с одинаковыми именами.Затем следует нажать клавишу ВВОД (поле Option должно оставаться пустым). На экране будет представлен отчет о выполнении указанного задания (cм. рис. 5.22) в режиме просмотра BROWSE, где можно воспользоваться всеми доступными для этого режима средствами.
Для просмотра листинга задания рекомендуется воспользоваться режимом разделения экрана, так чтобы панель редактора, откуда обычно производится запуск задания, располагалась на одном логическом экране, а панель утилиты Outlist - на другом. Теперь в любой момент можно переключаться между панелями при помощи клавиши F9 (SWAP). Так, после просмотра отчета можно вернуться к редактированию задания и его повторному запуску, а затем таким же образом переключиться на утилиту просмотра.
Отметим также, что утилита Outlist - не единственный способ просмотра распечаток выполненных заданий. Часто с этой целью используют компонент SDSF z/OS, специально предназначенный для контроля за ходом выполнения заданий и анализа их результатов.
Системные команды ISPF/PDF
Для управления редактированием пользователь может применять четыре типа команд:
системные команды ISPF/PDF;функциональные команды текстового редактора EDIT;строчные команды текстового редактора EDIT;макрокоманды редактирования.
Системные команды ISPF/PDF являются универсальными для всех режимов и панелей и вводятся в поле Command. Наиболее важные из них были рассмотрены выше.
Функциональные команды текстового редактора EDIT являются специфичными именно для этого режима работы и обеспечивают выполнение некоторых функций, связанных с редактируемыми данными. Функциональные команды служат для настройки параметров среды редактора, сохранения данных, поиска и замены текстовых строк, слияния и разбиения разделов наборов данных, запуска заданий JCL, сортировки данных, создания и запуска макросов редактирования и др. Ввод функциональных команд производится в поле Command по тем же правилам, что и системных команд. Большинство команд имеют сокращенные наименования для упрощения ввода. Перечень основных функциональных команд редактора приведен в приложении 5.
Строчные команды служат для управления как отдельными строками, так и строчными фрагментами текста. Эти команды позволяют добавлять или удалять информацию, перемещать, дублировать и копировать отдельные строки или группы строк, изменять отступы строк, временно отключать отображение строк на экране, выводить вспомогательные строки (шкалу колонок) и т.п. Строчные команды вводятся в произвольной позиции поля нумерации поверх номеров строк, для управления которыми эти команды предназначены. Список наиболее важных строчных команд редактора EDIT приведен в приложении 6.
Макрокоманды редактирования представляют собой последовательности функциональных команд редактора, сохраненные в виде раздела библиотечного набора данных. Эти последовательности предназначены для решения часто повторяющихся задач и могут быть активизированы по имени, как и функциональные команды.
Каждому сеансу работы с текстовым редактором EDIT соответствует индивидуальный профиль редактирования, состоящий из множества предустановленных значений параметров настройки среды редактора.
Конкретные значения параметров зависят от типа редактируемых данных, но могут быть изменены по желанию пользователя, как на время сеанса редактирования, так и с возможностью их сохранения и использования в последующих сеансах.
Чтобы просмотреть текущий профиль, необходимо в панели редактирования ввести функциональную команду PROFILE (или сокращенно PROF), имеющую формат:
PROFILE [number]
где number - число от 1 до 9, определяющее количество выводимых на экран строк, содержащих параметры профиля.
На рис. 5.55 показан результат выполнения команды PROF 9. Первые пять строк, помеченных символами "=PROF>", содержат ключевые параметры профиля. Последние четыре строки содержат атрибуты настройки табуляции (=TAB>), шаблон для вставляемых строк (=MASK>), указатель границ текста (=BNDS>) и шкалу колонок (=COLS>).
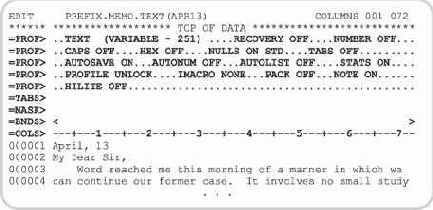
Рис. 5.55. Параметры профиля редактирования
Если команда PROF введена без параметра, по умолчанию выводится пять первых строк. В первой строке отображается имя профиля (в приведенном примере - TEXT) и характеристики логических записей используемого набора данных RECFM=V (VARIABLE) и LRECL=251. Остальные параметры и их описание приведены в таблице 5.8.
| RECOVERY | Режим восстановления текста при возникновении сбоев |
| NUMBER | Режим управления нумерацией строк |
| CAPS | Режим автоматического преобразования строчных символов в прописные |
| HEX | Режим представления данных в шестнадцатеричном формате |
| NULLS | Режим представления незаполненных позиций в конце строк текста |
| TABS | Управление табуляцией и выравниванием данных |
| AUTOSAVE | Режим автосохранения редактируемого набора данных при завершении сеанса редактирования |
| AUTONUM | Режим автоматической перенумерации при сохранении текста |
| AUTOLIST | Режим автоматического вывода текста в набор данных печати |
| STATS | Режим обновления статистических данных о разделах редактируемых библиотечных наборов данных |
| PROFILE | Режим сохранения изменений в профиле редактирования (UNLOCK - включен, LOCK - выключен) |
| IMACRO | Имя макроса редактирования, выполняющегося в начале сеанса (NONE - макрос не используется) |
| PACK | Режим упаковки (сжатия) данных при сохранении |
| NOTE | Режим включения отображения пояснительных записей |
| HILITE | Установка расширенных цветовых атрибутов редактируемого текста |
Большинство из представленных параметров характеризуется двумя значениями: ON и OFF. Значение ON показывает, что соответствующий режим действует (включен), OFF - не действует (выключен). Пользователь может изменять текущие значения параметров профиля, применяя функциональные команды редактора, совпадающие по наименованию с соответствующими параметрами профиля. Например, если необходимо установить режим автоматического преобразования строчных букв в прописные, следует ввести команду:
CAPS ON
Если значение параметра PROFILE установлено в LOCK, любые изменения параметров профиля будут действительны только в рамках текущего сеанса редактирования. Для сохранения внесенных изменений требуется выполнить установку параметра профиля по команде PROFILE UNLOCK
Для того чтобы удалить с экрана строки, отображающие параметры профиля, необходимо ввести команду RESET или RES.
ISPF/PDF поддерживает до 25 различных профилей, каждый из которых имеет предустановленное имя. Обычно имя профиля определяется по значению последнего квалификатора (Type) имени редактируемой библиотеки ISPF. В частности, зарезервированными являются следующие имена типов наборов данных и соответствующих им профилей:
ASM - исходный текст программ на ассемблере;CLIST - команды TSO/E и инструкции CLIST;CNTL - JCL и SYSIN для команды SUBMIT;DATA - текст из прописных букв;EXEC - команды TSO/E и инструкции REXX;TEXT - текст из строчных и прописных букв.
Значения параметров каждого из указанных профилей формируются с учетом специфики и особенностей соответствующих данных. Например, при формировании текста задания JCL необходимо установить режим CAPS ON.
Имя профиля может быть задано явно путем ввода в поле Profile Name входной панели редактора. Если это поле остается пустым и стандартный тип набора данных не задан, ISPF/PDF использует профиль по умолчанию.
Состав и функции ISPF
ISPF (Interactive System Productivity Facility) обеспечивает поддержку интерактивной полноэкранной среды пользователя, ориентированной на выполнение базовых пользовательских функций, в первую очередь связанных с разработкой приложений и управлением данными [23], [24].
Компонент ISPF состоит из четырех основных модулей:
менеджер диалогов (DM);менеджер сопровождения разработки программного обеспечения (SCLM);среда разработки программ (PDF);средства поддержки режима клиент-сервер (C/S).
Менеджер диалогов DM (Dialog Manager) предназначен для поддержки выполнения специальных программ, называемых диалогами (dialogs). С помощью диалогов реализуется интерактивное взаимодействие с конечными пользователями системы на базе полноэкранного диалогового интерфейса. Диалоги создаются на основе поддерживаемых в DM стандартных элементов, таких как панели, всплывающие окна, меню, сообщения, таблицы, переменные, шаблоны файлов и другие, регламентированные международным стандартом CUA/SAA.
Кроме того, ISPF/DM поддерживает специальный язык описания диалогов DTL
(Dialog Tag Language), а также набор доступных для программиста сервисов (стандартных процедур) для построения и управления типовыми элементами диалогов. Эти сервисы могут использоваться для создания диалогов в приложениях на различных языках программирования.
Модуль SCLM (Software Configuration and Library Manager) предназначен для организации эффективного сопровождения крупных проектов по созданию программного обеспечения. SCLM использует понятие "база данных проекта" (project database), в которой логически объединяются наборы данных или, как принято говорить, библиотеки всех участвующих в проекте разработчиков.
SCLM поддерживает диалоговые средства для создания, просмотра, обновления, компиляции, редактирования, учета версий, формирования отчетов для наборов данных, хранящихся в базе данных проекта. Кроме того, SCLM содержит библиотеку доступных программисту сервисов управления базой данных проекта. SCLM является альтернативой более ранней технологии сопровождения разработки программ LM (Library Management), также доступной в среде PDF.
Модуль разработки программ PDF ( Program Development Facility) представляет собой мощную интегрированную среду разработки программ, включающую:
средства создания и управления наборами данных;полноэкранный текстовый редактор;средства запуска и анализа результатов выполненных программ и заданий;средства сопровождения пользовательских библиотек.
Все средства PDF реализованы в форме диалогов. По выполняемым функциям среду ISPF/PDF можно сравнить с популярной файловой оболочкой Norton Commander для MS-DOS или с файловыми менеджерами в других ОС. Модуль PDF является основным элементом ISPF, связывающим воедино все модули и обеспечивающим пользователю единый интерфейс для доступа к данным и приложениям.
На рис. 5.31 представлено так называемое главное (первичное) меню ISPF/PDF, которое видит пользователь в самом начале сеанса работы. Помимо стандартных функций, главное меню может включать также функции, добавленные пользователем по своему усмотрению путем настройки.
Рис. 5.31. Главное меню ISPF/PDF
Стандартный перечень функций включает:
Settings (настройка) - просмотр и редактирование значений параметров среды ISPF, таких как характеристики терминала, формат диалоговых панелей, определение функциональных клавиш и др.View (просмотр) - просмотр содержимого наборов данных и редактирование без возможности сохранения результатов.Edit (редактирование) - использование встроенного текстового редактора для создания и правки исходных программ, документов и т.п.Utilities (утилиты) - выполнение утилит (служебных программ), предназначенных для управления последовательными и библиотечными наборами данных, включая функции создания, переименования, удаления, каталогизации, печати, сравнения и др.Foreground (интерактивный режим) - выполнение компиляции исходных программ с различных языков программирования (Assembler, COBOL, С/С++, FORTRAN, PL/I и др.) и использование редактора связей в интерактивном режиме.Batch (пакетный режим) - выполнение компиляции исходных программ с различных языков программирования и вызов редактора связей в пакетном режиме.Command (команда) - выполнение команд TSO, а также вызов командных процедур (CLIST/ REXX)Dialog Test (отладка диалогов) - тестирование и отладка диалогов ISPF и их отдельных элементов.LM Facility (средства менеджера библиотек) - управление процессом коллективной разработки программного обеспечения, включая контроль версий, прав доступа и др.IBM Products (приложения IBM) - доступ к некоторым вспомогательным программным продуктам IBM (требует предварительной установки этих продуктов).SCLM (менеджер сопровождения разработки программного обеспечения) - управление процессом коллективной разработки программного обеспечения (альтернатива для LM).Workplace (рабочее место пользователя) - встроенная оболочка, реализующая большинство функций PDF с использованием собственного унифицированного формата диалога.
Выполнение каждой функции представлено в едином стиле с помощью диалоговых экранных форм, называемых панелями. Реализация функций просмотра и редактирования данных основана на использовании встроенного текстового редактора, располагающего широкими возможностями, включая поддержку типовых моделей текстовых данных, создание макросов и др.
Большинство функций ISPF ориентировано на работу только с размещенными на дисковых томах последовательными и библиотечными наборами данных. Кроме того, в ISPF установлен ряд существенных ограничений на применение некоторых типов наборов данных. В частности, не поддерживаются наборы данных:
VSAM (кроме функций создания и удаления);прямого доступа и индексно-последовательные;размещенные на ленточных накопителях;с записями формата VBS (сегментированный формат);распределенные с параметром BUFNO.
Существуют также ограничения на использование многотомных наборов данных и некоторые другие.
В составе ISPF представлен еще один модуль - модуль клиент/сервер C/S
(Client/Server), обеспечивающий возможность реализации диалогов ISPF в режиме клиент-сервер на рабочей станции, работающей под управлением одной из популярных операционных систем, таких как Windows, OS/2, UNIX и др. В частности, в среде Windows элементы диалогов ISPF представляются с использованием стандартных элементов графического пользовательского интерфейса Windows, таких как окна, кнопки, меню и др.
Средства диалогового взаимодействия с пользователем
Список наиболее важных строчных команд утилиты Dslist приведен в таблице 5.7.
| E | Edit | Переход в режим редактирования |
| V | View | Переход в режим просмотра View |
| B | Browse | Переход в режим просмотра Browse |
| M | Member List | Выдать список разделов библиотеки |
| D | Delete | Удалить набор данных |
| R | Rename | Переименовать набор данных |
| I | Info | Выдать полную информацию о наборе данных |
| S | Short Info | Выдать краткую информацию о наборе данных |
| P | Вывести в набор данных печати | |
| C | Catalog | Каталогизировать указанный набор данных |
| U | Uncatalog | Исключить из каталога указанный набор данных |
| Z | Compress | Сжать библиотечный набор данных |
| F | Free | Освободить распределенное для набора данных, но неиспользуемое пространство внешней памяти |
| PX | Print Index | Вывести основную информацию о библиотеке и список ее разделов в набор данных печати |
| RES | Reset | Корректировка статистики разделов библиотеки |
| MO | Move | Перемещение набора данных |
| CO | Copy | Копирование набора данных |
| X | Exclude | Исключить набор данных из списка |
| NX | Unexclude | Восстановить ранее исключенные из списка наборы данных команды |
Для библиотечных наборов данных команды E, V, B и M приводят к отображению панели списка разделов, где пользователь может указать, какие разделы должны быть обработаны с помощью соответствующих строчных команд. Многие команды, такие как D, R, RES, CO, и MO инициируют вывод специальных панелей или окон для ввода дополнительных параметров.
Для пользователей, которые не помнят мнемонику строчных команд, существует альтернативная возможность выбора требуемого действия. В этом случае следует ввести символ "/" в поле строчных команд или просто подвести курсор к имени набора данных и нажать клавишу ВВОД. На экране появится всплывающее окно со списком выбора допустимых действий, соответствующих представленным в таблице. Для выбора действия пользователь должен в поле ввода указать номер соответствующей функции и вновь нажать клавишу ВВОД.
Рассмотрим особенности выполнения некоторых наиболее важных строчных команд (получение информации о наборе данных, переименование и удаление).
Для удаления набора данных пользователь должен ввести строчную команду D. Если в панели утилиты Dslist был установлен переключатель Confirm Data Set Delete, на экран будет выведено всплывающее окно, запрашивающее подтверждение на удаление (рис. 5.52). Для подтверждения удаления необходимо нажать клавишу ВВОД, для отмены - ввести команду END (F3).

Рис. 5.51. Переименование набора данных
Рис. 5.52. Панель подтверждения удаления набора данных
Функциональные команды утилиты Dslist служат для управления представлением списка наборов данных и вводятся в поле Command. Рассмотрим некоторые из них.
Команда REFRESH не имеет параметров и предназначена для обновления отображаемого списка наборов данных после того, как были выполнены действия, изменившие его содержимое (например, после удаления наборов данных).
Команда RESET позволяет очистить панель от ранее сформированных сообщений и введенных строчных команд.
С помощью команды SORT можно переупорядочить список наборов данных по заданному полю. Формат команды
SORT [field1 [field2]]
где field1 - имя поля (колонки) списка, по которому будет производиться основная сортировка, field2 - имя поля, по которому будет производиться дополнительная сортировка при совпадении значений элементов поля field1.
Имена полей указаны в верхней части списка наборов данных. Например, для сортировки по имени тома и размеру блока (дополнительно) следует ввести команду:
SORT VOLUME BLKSZ
Если параметры команды SORT не указаны, список будет отсортирован по имени наборов данных, как это установлено по умолчанию. Порядок сортировки (по убыванию или возрастанию) зависит от выбранного поля.
Команда LOCATE (сокращенно L) предназначена для прокрутки экрана так, чтобы в верхней строке оказался элемент списка, задаваемый в качестве параметра:
LOCATE string
Значение string должно совпадать с первыми символами одного из значений поля, по которому список отсортирован в данный момент. По умолчанию таким полем является поле имени наборов данных.
Например, если список отсортирован по именам томов, можно ввести:
LOCATE WORK01
В результате прокрутки списка в верхней части экрана будет отображен первый набор данных, размещенный на томе WORK01.
Если указанное значение не найдено, то список будет позиционирован на ближайшее подходящее значение, предшествующее указанному.
Средства редактирования данных в PDF
В процессе работы пользователь сталкивается с необходимостью создавать и использовать различную текстовую информацию, хранящуюся в наборах данных или разделах библиотек, например:
исходные программы, написанные на различных языках программирования (ассемблер, COBOL, PL/1, C/C++, CLIST и др.);задания для z/OS на языке управления заданиями JCL;текстовые документы в виде записок, отчетов, справок, писем и т.п.числовые и текстовые данные, представляющие исходную структурированную информацию для обработки выполняющимися программами.
ISPF/PDF располагает встроенными средствами для редактирования и просмотра текстовых данных, которые представлены текстовым редактором EDIT, а также функциями просмотра данных VIEW и BROWSE [26]. Средства редактирования и просмотра реализованы в едином стиле на основе специальной панели ISPF.
Текстовый редактор EDIT позволяет создавать и корректировать тексты любого типа, размещенные в последовательных наборах данных или в разделах библиотечных наборов данных. При этом логические записи редактируемых наборов данных могут иметь любой формат (RECFM), кроме U, и длину (LRECL) не более 32760 байт.
EDIT предоставляет большой набор встроенных команд для редактирования программ и документов. Как и в большинстве других редакторов, пользователь имеет возможность добавлять, удалять, копировать и перемещать фрагменты текста как внутри одного документа, так и по отношению к различным наборам данных. Поддерживаются средства контекстного поиска и замены. Для каждого сеанса работы может быть установлен индивидуальный профиль редактирования, состоящий из множества параметров настройки среды редактора. Для повышения надежности поддерживаются средства отмены результатов неверно выбранной команды, а также технология автоматического восстановления прерванного редактирования, если пользователь не сумел сохранить данные из-за сбоя электропитания или по другим причинам.
Вызвать текстовый редактор можно из главного меню ISPF/PDF, а также из некоторых утилит ISPF, обслуживающих наборы данных.
Функция редактирования доступна для работы только с заранее распределенными наборами данных. Поэтому для первичного заполнения документа надо предварительно создать соответствующий набор данных.
Основными элементами текстового редактора ISPF/PDF являются:
входная панель редактора;панель редактирования;функциональные команды;строчные команды;профиль редактирования.
Вход в режим редактирования набора данных (раздела библиотеки) может осуществляться несколькими способами:
из главного меню ISPF/PDF (функция 2 - Edit);из утилиты обслуживания библиотек Library (3.1) с помощью опции E;из утилиты списка наборов данных Dslist (3.4) с помощью строчной команды E;из списка разделов библиотечного набора данных с помощью строчной команды E, независимо от того, при выполнении какой функции получен такой список.
В первом случае на экране появится входная панель редактора (Edit Entry Panel) (рис. 5.53). Во входной панели пользователь должен обязательно указать имя набора данных, который он будет редактировать одним из возможных способов.
Рис. 5.53. Входная панель редактора EDIT
Напомним, что если для библиотечного набора данных указать несуществующий раздел, то он будет автоматически создан. Если же имя раздела не указано, то на экран будет выведен список разделов, из которого пользователь может выбрать нужный раздел с помощью строчной команды S.
Кроме того, во входной панели редактора могут быть сформированы следующие параметры:
Initial Macro - имя макроса, который необходимо выполнить перед началом редактирования (обычно с целью настройки параметров профиля редактора). Если данное поле оставить пустым, то будет выполнен макрос, определенный в профиле редактирования. Для того чтобы блокировать вызов макроса из профиля, следует ввести NONE.
Profile Name - имя стандартного профиля редактирования, который следует использовать вместо профиля, подключаемого по умолчанию.
Confirm Cancel/Move/Replace - вывод предупреждающих сообщений, требующих подтверждения пользователя при выполнении команд CANCEL (могут быть потеряны изменения данных), а также MOVE и REPLACE (замещаемый набор данных существует).
Поля Format Name и Mixed Mode используются для специальных форматов представления данных, которые здесь не рассматриваются. Обычно их следует оставлять пустыми.
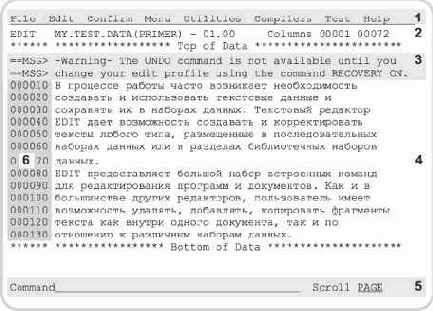
Рис. 5.54. Структура панели редактирования
Нажатие клавиши ВВОД во входной панели либо выбор редактируемого раздела из списка приводят к появлению на экране панели редактирования, общий вид которой приведен на рис. 5.54. Панель редактирования включает шесть областей [25]:
меню действий (1);заголовок (2);область вывода сообщений (3);область данных (4);строка команд (5);поле нумерации и строчных команд (6).
Меню действий (1) служит для вызова стандартных функций ISPF/PDF, а также для выполнения различных команд и настроек, связанных с работой редактора EDIT.
Строка команд (5) содержит поле ввода (Command) системных команд ISPF/PDF и функциональных команд управления редактированием. В этой же строке устанавливается параметр режима прокрутки редактируемого текста (поле Scroll). Напомним, что по желанию пользователя строка команд может позиционироваться в верхней части экрана с помощью функции Settings.
Строка заголовка (2) содержит имя редактируемого набора данных, включая имя раздела, номер версии и номер модификации, а также видимый на экране диапазон колонок текста (Columns).
Область сообщений (3) может включать несколько строк и предназначена для вывода предупреждающих, диагностических и справочных сообщений редактора EDIT, значений параметров профиля редактирования и других специальных данных, не входящих в редактируемый текст. Эта область является динамической, т.е. может появляться и исчезать по инициативе системы или пользователя. Строки, содержащие сообщение, относятся к разряду вспомогательных помеченных строк, так как слева помечаются символами "==MSG>". В процессе работы пользователь может увидеть и другие помеченные строки, например строку вывода маркера колонок, помеченную символами "==COL>" и др. Основную часть экрана занимает область данных (4), в которой формируется и отображается редактируемый текст, точнее, та его часть, которая позиционирована на экране в результате прокрутки.
Присутствие на экране начального фрагмента текста сопровождается выводом вспомогательной строки Top of Data ("начало данных"), а заключительного фрагмента - Bottom of Data ("окончание данных"). Следует отметить, что ввод текста возможен начиная с 8-й колонки (позиции) экрана. Таким образом, на экране стандартного терминала, использующего 80 колонок в строке, в поле данных отображается 72 символа. Для того чтобы увидеть остальные символы строки, следует воспользоваться командами горизонтальной прокрутки.
Поле нумерации (6) занимает первые шесть колонок экрана слева от области данных и содержит порядковые номера строк отображаемого текста. У пустого набора данных это поле заполнено специальными символами - апострофами, которые замещаются номерами строк после ввода текста и нажатия на клавишу ВВОД:
''''''
Таким же образом помечаются пустые строки, добавляемые в текст в результате выполнения операции вставки. В поле нумерации пользователь может вводить строчные команды, служащие для управления как отдельными строками, так и строчными фрагментами текста. Особенности ввода строчных команд будут рассмотрены ниже. Номера строк могут дублироваться в правой части области данных при соответствующей настройке профиля редактирования.
Ввод функциональных команд производится в поле Command по тем же правилам, что и системных команд. Большинство команд имеют сокращенные наименования для упрощения ввода. Перечень основных функциональных команд редактора приведен в приложении 5.
Строчные команды служат для управления как отдельными строками, так и строчными фрагментами текста. Эти команды позволяют добавлять или удалять информацию, перемещать, дублировать и копировать отдельные строки или группы строк, изменять отступы строк, временно отключать отображение строк на экране, выводить вспомогательные строки (шкалу колонок) и т.п. Строчные команды вводятся в произвольной позиции поля нумерации поверх номеров строк, для управления которыми эти команды предназначены. Список наиболее важных строчных команд редактора EDIT приведен в приложении 6.
Макрокоманды редактирования представляют собой последовательности функциональных команд редактора, сохраненные в виде раздела библиотечного набора данных. Эти последовательности предназначены для решения часто повторяющихся задач и могут быть активизированы по имени, как и функциональные команды.
Каждому сеансу работы с текстовым редактором EDIT соответствует индивидуальный профиль редактирования, состоящий из множества предустановленных значений параметров настройки среды редактора. Конкретные значения параметров зависят от типа редактируемых данных, но могут быть изменены по желанию пользователя, как на время сеанса редактирования, так и с возможностью их сохранения и использования в последующих сеансах.
Чтобы просмотреть текущий профиль, необходимо в панели редактирования ввести функциональную команду PROFILE (или сокращенно PROF), имеющую формат:
PROFILE [number]
где number - число от 1 до 9, определяющее количество выводимых на экран строк, содержащих параметры профиля.
На рис. 5.55 показан результат выполнения команды PROF 9. Первые пять строк, помеченных символами "=PROF>", содержат ключевые параметры профиля. Последние четыре строки содержат атрибуты настройки табуляции (=TAB>), шаблон для вставляемых строк (=MASK>), указатель границ текста (=BNDS>) и шкалу колонок (=COLS>).
Рис. 5.55. Параметры профиля редактирования
Если команда PROF введена без параметра, по умолчанию выводится пять первых строк. В первой строке отображается имя профиля (в приведенном примере - TEXT) и характеристики логических записей используемого набора данных RECFM=V (VARIABLE) и LRECL=251. Остальные параметры и их описание приведены в таблице 5.8.
| RECOVERY | Режим восстановления текста при возникновении сбоев |
| NUMBER | Режим управления нумерацией строк |
| CAPS | Режим автоматического преобразования строчных символов в прописные |
| HEX | Режим представления данных в шестнадцатеричном формате |
| NULLS | Режим представления незаполненных позиций в конце строк текста |
| TABS | Управление табуляцией и выравниванием данных |
| AUTOSAVE | Режим автосохранения редактируемого набора данных при завершении сеанса редактирования |
| AUTONUM | Режим автоматической перенумерации при сохранении текста |
| AUTOLIST | Режим автоматического вывода текста в набор данных печати |
| STATS | Режим обновления статистических данных о разделах редактируемых библиотечных наборов данных |
| PROFILE | Режим сохранения изменений в профиле редактирования (UNLOCK - включен, LOCK - выключен) |
| IMACRO | Имя макроса редактирования, выполняющегося в начале сеанса (NONE - макрос не используется) |
| PACK | Режим упаковки (сжатия) данных при сохранении |
| NOTE | Режим включения отображения пояснительных записей |
| HILITE | Установка расширенных цветовых атрибутов редактируемого текста |
CAPS ON
Если значение параметра PROFILE установлено в LOCK, любые изменения параметров профиля будут действительны только в рамках текущего сеанса редактирования.
Для сохранения внесенных изменений требуется выполнить установку параметра профиля по команде PROFILE UNLOCK
Для того чтобы удалить с экрана строки, отображающие параметры профиля, необходимо ввести команду RESET или RES.
ISPF/PDF поддерживает до 25 различных профилей, каждый из которых имеет предустановленное имя. Обычно имя профиля определяется по значению последнего квалификатора (Type) имени редактируемой библиотеки ISPF. В частности, зарезервированными являются следующие имена типов наборов данных и соответствующих им профилей:
ASM - исходный текст программ на ассемблере;CLIST - команды TSO/E и инструкции CLIST;CNTL - JCL и SYSIN для команды SUBMIT;DATA - текст из прописных букв;EXEC - команды TSO/E и инструкции REXX;TEXT - текст из строчных и прописных букв.
Значения параметров каждого из указанных профилей формируются с учетом специфики и особенностей соответствующих данных. Например, при формировании текста задания JCL необходимо установить режим CAPS ON.
Имя профиля может быть задано явно путем ввода в поле Profile Name входной панели редактора. Если это поле остается пустым и стандартный тип набора данных не задан, ISPF/PDF использует профиль по умолчанию.
Средства управления в ISPF/PDF
К средствам управления в ISPF/PDF относятся команды и горизонтальное меню действий.
Команды вводятся пользователем в командной строке панели. Существует три типа команд:
системные (в том числе команды TSO/E);функциональные;пользовательские.
Системные команды служат для выполнения наиболее общих и универсальных действий (таких, как прокрутка экрана, вызов подсказки, печать и др.) и могут использоваться во всех панелях ISPF. Перечень наиболее важных системных команд приведен в приложении 4. Функциональные команды
доступны только в определенных режимах работы и могут применяться лишь в панелях, реализующих соответствующую функцию (например, команды текстового редактора). Пользовательские команды не входят в стандартный набор команд, а добавляются в ISPF по инициативе пользователя.
Системные и пользовательские команды описываются в так называемых таблицах команд (command tables), поддерживаемых и обрабатываемых модулем ISPF/DM, в то время как функциональные команды выполняются в диалогах, реализующих соответствующую функцию.
Для эффективной работы пользователь должен освоить ряд основных системных команд, которые предоставляют следующие возможности:
выбор функций и переключение панелей ISPF;управление курсором и скроллинг (прокрутка) изображения;управление терминалом (настройка экрана и клавиатуры);настройка параметров среды ISPF;вызов справки и обучающих программ;управление печатью данных;выполнение команд TSO/E и процедур CLIST, REXX.
Для удобства работы ISPF поддерживает так называемый стек вызова команд (command retrieval stack), в который копируются все вводимые пользователем команды. В любой момент пользователь может обратиться к стеку, просмотреть "предысторию" применения команд и вызвать на выполнение любую из них, не затрачивая усилий на повторный ввод.
Действия некоторых наиболее часто используемых команд могут быть произведены с помощью горизонтального меню и программируемых функциональных клавиш (ПФК). Стандартные назначения для ПФК могут быть изменены по желанию пользователя.
В некоторых режимах работы ISPF/PDF (редактирование, работа со списком разделов или наборов данных) могут использоваться так называемые строчные команды, действие которых распространяется только на отмеченные этими командами элементы панелей. Для ввода строчных команд используются специальные поля панели и никогда - командная строка.
Меню действий (action bar) располагается в верхней строке каждой панели и служит для доступа к различным функциям, как связанным с данной панелью, так и общесистемным. Выбор и активизация пункта меню осуществляется путем позиционирования курсора на его наименовании и нажатия клавиши ВВОД. При этом обычно отображается "выпадающее меню" (pulldown), содержащее нумерованный список выбора (рис. 5.36).
Рис. 5.36. Использование меню действий
Выбор элемента списка производится путем ввода номера выбранного элемента в специальном поле ввода и нажатия клавиши ВВОД. Если наименование элемента pulldown меню содержало символы многоточия (...), то на экране появляется "всплывающее" диалоговое окно (popup window) поверх изображения активной панели. Диалоговое окно содержит стандартные элементы ввода данных, характерные для обычных панелей.
Содержимое меню изменяется в зависимости от типа панели и включает как специфические для данной панели действия, так и стандартные элементы, служащие для вызова наиболее важных функций ISPF и системных команд. К наиболее часто повторяющимся стандартным элементам меню действий относятся:
Menu - доступ к основным функциям, представленным в главном меню ISPF;Utilities - доступ ко всем функциям, представленным в меню утилит ISPF;Compilers - доступ к средствам компиляции программ;Reflist ,Refmode - средства управления списком ссылок на наборы данных;Workstation - параметры настройки режима клиент-сервер;Help - вызов справочной информации.
Особую роль меню действий играет при вызове функций и утилит ISPF, о чем пойдет речь ниже.
Удаление строк (D)
Формат команды:
1) D[n] 2) DD
Строчная команда D (Delete) служит для удаления заданного (n) числа строк, начиная со строки, содержащей эту команду. Для удаления одной строки значение n не указывается. При указании D99999 удаляются все строки до конца набора данных, начиная с текущей строки.
Второй формат команды служит для удаления группы строк. В этом случае команда DD вводится в первой и последней строке удаляемого строчного фрагмента. Первая и последняя строки фрагмента не обязательно должны быть на одной странице экрана.
Пример удаления двух строчных фрагментов (строки 1-4 и 6-7):
dd0001 Это первая строка 000002 Это вторая строка 000003 Это третья строка dd0004 Это четвертая строка 000005 Это пятая строка d20006 Это шестая строка 000007 Это седьмая строка 000008 Это последняя строка
Результат:
000001 Это пятая строка 000002 Это последняя строка
Утилита обслуживания наборов данных (Data Set)
Утилита обслуживания наборов данных (3.2, Data Set) ориентирована на обработку как последовательных, так и библиотечных наборов данных и доступна из меню утилит. С ее помощью выполняются операции переименования, удаления, каталогизации и исключения из каталога наборов данных, просмотр служебной информации о наборе данных и т.д. Только эта утилита позволяет создавать (распределять) новые наборы данных.
В панели утилиты DataSet (рис. 5.46) пользователь должен определить имя обрабатываемого набора данных одним из ранее рассмотренных способов, а затем выбрать операцию обработки, введя ее код в поле Option и нажав клавишу ВВОД.
Рис. 5.46. Панель утилиты обслуживания наборов данных
Функции утилиты представлены в верхней части панели и включают:
A - создать (распределить) новый набор данных;R - переименовать набор данных;D - удалить набор данных;blank (пробел) - отобразить полную информацию о наборе данных;C - каталогизировать набор данных;U - исключить набор данных из каталога;S - отобразить краткую информацию о наборе данных;M - создать (распределить) новый набор данных с использованием SMS-технологии (требует специально сконфигурированного тома);V - работа с наборами данных типа VSAM.
Ниже будет рассмотрена только одна, но очень важная функция - распределение нового набора данных. Почти все остальные функции (кроме M и V) могут быть выполнены с помощью утилиты Dslist.
Для распределения нового набора данных пользователю необходимо задать его имя, затем ввести команду А в поле Option и нажать клавишу ВВОД. После этого на экране появится панель Allocate New Data Set, с помощью которой можно установить все необходимые параметры создаваемого набора (рис. 5.47).
При создании стандартного последовательного или библиотечного набора данных (без использования SMS технологии) обязательными для ввода являются следующие параметры:
Space units - единицы измерения предоставляемой памяти;
Primary Quantity - объем первично выделяемого пространства памяти в заданных единицах;
Secondary Quantity - объем дополнительно выделяемого пространства памяти в заданных единицах (используется в случае нехватки первично выделенной памяти);
Directory blocks - количество блоков (по 256 КB каждый), резервируемых под оглавление (только для библиотечных наборов данных);
Record format - формат логических записей;
Record length - длина логической записи;
Block size - размер блока.
Представленные на рис. 5.47 значения соответствуют созданию библиотечного набора данных с параметрами, определяемыми следующим оператором DD:
//ХХХХ DD SPACE=(6160,(96,12,10)),RECFM=FB, // BLKSIZE=6160,LRECL=80
Рис. 5.47. Панель распределения нового набора данных
Следует отметить, что количество блоков оглавления библиотечного набора данных выбирается с учетом следующей информации:
наборы данных, использующие статистику разделов, позволяют создавать по шесть разделов на каждый блок;наборы данных, не использующие статистику разделов, позволяют создавать по 21 разделу на каждый блок;библиотеки загрузочных модулей, позволяют создавать от четырех до семи разделов на каждый блок в зависимости от атрибутов.
Для создания библиотечного набора данных типа PDSE необходимо дополнительно ввести значение Library в поле Data set name type. Для создания последовательного набора данных поле Directory blocks необходимо оставить пустым.
После ввода всех необходимых параметров следует нажать клавишу ВВОД. На экране вновь появляется основная панель утилиты DataSet. При успешном выполнении функции будет сформировано короткое сообщение "Data set allocated", означающее, что набор данных создан. В противном случае будет выдано сообщение об ошибке, и пользователь должен проверить правильность введенных параметров, повторив все указанные действия.
Утилита работы со списком наборов данных (Dslist)
Утилита Dslist (3.4) объединяет в себе практически все возможности утилит PDF, кроме распределения нового набора данных. Эти возможности реализуются через отображаемый на экране список наборов данных. Работа со списком дает существенную экономию времени и усилий, так как можно напрямую указать набор данных с помощью курсора и задать требуемое действие через строчные команды. С помощью специального фильтра пользователь может устанавливать, какие именно наборы данных должны быть включены в список.
Внешний вид панели утилиты Dslist изображен на рис. 5.48. В верхней части панели представлен перечень допустимых функций утилиты, включающий:
blank (пробел) - сформировать и отобразить список наборов данных в соответствии с установленным фильтром (критерием отбора);P - вывести сформированный список в набор данных печати;V - отобразить информацию об оглавлении указанного тома;PV - вывести информацию об оглавлении указанного тома в набор данных печати.
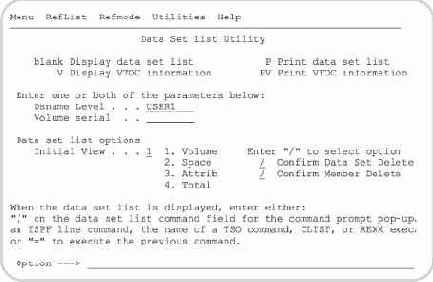
Рис. 5.48. Панель утилиты работы со списком наборов данных DSLIST
Рассмотрим функцию отображения списка наборов данных, для чего необходимо сформировать фильтр для отбора элементов списка, указав хотя бы один из следующих параметров:
шаблон имени наборов данных в поле Dsname Levelимя тома в поле Volume serial
Шаблон имени наборов данных строится с использованием специальных символов: *, ** и %. Одиночный символ * означает, что в данной позиции должен размещаться как минимум один квалификатор имени. В то же время символ * внутри квалификатора означает произвольное количество любых допустимых символов, в том числе ни одного. Двойная звездочка ** означает, что в данной позиции может размещаться либо ни одного, либо несколько квалификаторов. Символ % заменяет ровно один произвольный символ внутри квалификатора. Апострофы при задании шаблона не используются.
Рассмотрим несколько примеров записи шаблонов.
SYS1.* - все наборы данных с первым квалификатором SYS1 и еще хотя бы с одним квалификатором (например, SYS1.PROCLIB, SYS1.IBM.PARM, но не SYS1);
SYS1.** - все наборы данных с первым квалификатором SYS1 (например, SYS1.PROCLIB, SYS1.IBM.PARM, SYS1);
SYS1 - то же, что и SYS1.**
**.CLIST - все наборы данных, включающие квалификатор CLIST в любой позиции (например, CLIST, USER1.CLIST, D.CLIST.JOHN);
A*.*%B.C%%% - все наборы данных, у которых первый квалификатор начинается с символа A (остальные символы - произвольные), второй квалификатор заканчивается символом B, которому предшествует как минимум еще один символ, третий квалификатор начинается с символа С и содержит еще ровно три произвольных символа (например, A8.BOB.C777, A.A111111B.CCZZ);
При задании только шаблона (поле Volume serial остается пустым) пользователь получает список всех каталогизированных наборов данных, имя которых соответствует шаблону, независимо от того, на каком томе они расположены.
Отметим, что в случае, когда в качестве первого квалификатора указывается * или **, ISPF выводит предупреждающее сообщение о том, что для поиска наборов данных, удовлетворяющих шаблону, может потребоваться много времени. Пользователь должен либо подтвердить свое решение, нажав клавишу ВВОД, либо отказаться, введя команду CANCEL.
Вторым элементом фильтра является имя тома, указав которое пользователь может ввести дополнительное условие отбора наборов данных, ограничив их множество заданным томом. Допускается одновременное использование и шаблона, и имени тома.
В поле Initial view можно установить требуемый формат представления списка наборов данных из четырех возможных вариантов, введя соответствующий номер:
Volume - вывод имени тома;Space - вывод характеристик распределения наборов данных;Attrib - вывод параметров логических записей наборов данных;Total - вывод всех перечисленных параметров в две строки для каждого набора данных.
Панель Dslist содержит также два переключателя, регулирующих необходимость вывода подтверждающих сообщений при удалении наборов данных и разделов библиотек (Confirm Data Set Delete и Confirm Member Delete)
После установки фильтра и выбора формата можно получить панель списка наборов данных, нажав клавишу ВВОД (поле Option должно оставаться пустым).
На рис. 5. 49 представлена панель списка наборов данных (формат 1), имена которых начинаются с квалификатора USER1 независимо от занимаемого ими тома.
В правом верхнем углу панели указано, сколько элементов содержится в отображаемом списке (Row 1 of 8). Если все элементы не умещаются на экране, можно воспользоваться соответствующими командами прокрутки или функциональными клавишами F7 и F8. Величина смещения при прокрутке устанавливается в поле Scroll. С помощью функциональных клавиш F10 и F11 можно циклически переключать формат представления списка между четырьмя ранее рассмотренными вариантами.
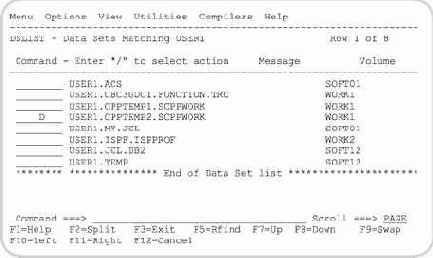
Рис. 5.49. Панель списка наборов данных
Управление наборами данных и представлением списка производится с помощью строчных и функциональных команд утилиты Dslist, представленных ниже.
Для выполнения операций над наборами данных служат строчные команды. С помощью этих команд можно просматривать, редактировать, переименовывать, удалять, копировать, перемещать, каталогизировать наборы данных и выполнять многие другие действия.
Строчные команды для работы со списками состоят, как правило, из одного или двух символов и не имеют дополнительных параметров. Команды разрешается вводить как строчными, так и прописными буквами, начиная с любой позиции поля ввода, расположенного слева от имени набора данных в списке.
Строчные команды выполняют операции для тех элементов списка, рядом с которыми они указаны. Пользователь может указать одновременно несколько строчных команд в различных строках. Для перемещения курсора к полю строчных команд следующей строки можно использовать клавиши Tab или Enter. Активизация действия всех строчных команд происходит по нажатию клавиши ВВОД.
SYS1.** - все наборы данных с первым квалификатором SYS1 (например, SYS1.PROCLIB, SYS1.IBM.PARM, SYS1);
SYS1 - то же, что и SYS1.**
**.CLIST - все наборы данных, включающие квалификатор CLIST в любой позиции (например, CLIST, USER1.CLIST, D.CLIST.JOHN);
A*.*%B.C%%% - все наборы данных, у которых первый квалификатор начинается с символа A (остальные символы - произвольные), второй квалификатор заканчивается символом B, которому предшествует как минимум еще один символ, третий квалификатор начинается с символа С и содержит еще ровно три произвольных символа (например, A8.BOB.C777, A.A111111B.CCZZ);
При задании только шаблона (поле Volume serial остается пустым) пользователь получает список всех каталогизированных наборов данных, имя которых соответствует шаблону, независимо от того, на каком томе они расположены.
Отметим, что в случае, когда в качестве первого квалификатора указывается * или **, ISPF выводит предупреждающее сообщение о том, что для поиска наборов данных, удовлетворяющих шаблону, может потребоваться много времени. Пользователь должен либо подтвердить свое решение, нажав клавишу ВВОД, либо отказаться, введя команду CANCEL.
Вторым элементом фильтра является имя тома, указав которое пользователь может ввести дополнительное условие отбора наборов данных, ограничив их множество заданным томом. Допускается одновременное использование и шаблона, и имени тома.
В поле Initial view можно установить требуемый формат представления списка наборов данных из четырех возможных вариантов, введя соответствующий номер:
Volume - вывод имени тома;Space - вывод характеристик распределения наборов данных;Attrib - вывод параметров логических записей наборов данных;Total - вывод всех перечисленных параметров в две строки для каждого набора данных.
Панель Dslist содержит также два переключателя, регулирующих необходимость вывода подтверждающих сообщений при удалении наборов данных и разделов библиотек (Confirm Data Set Delete и Confirm Member Delete)
После установки фильтра и выбора формата можно получить панель списка наборов данных, нажав клавишу ВВОД (поле Option должно оставаться пустым).
На рис. 5. 49 представлена панель списка наборов данных (формат 1), имена которых начинаются с квалификатора USER1 независимо от занимаемого ими тома.
В правом верхнем углу панели указано, сколько элементов содержится в отображаемом списке (Row 1 of 8). Если все элементы не умещаются на экране, можно воспользоваться соответствующими командами прокрутки или функциональными клавишами F7 и F8. Величина смещения при прокрутке устанавливается в поле Scroll. С помощью функциональных клавиш F10 и F11 можно циклически переключать формат представления списка между четырьмя ранее рассмотренными вариантами.
Рис. 5.49. Панель списка наборов данных
Управление наборами данных и представлением списка производится с помощью строчных и функциональных команд утилиты Dslist, представленных ниже.
Для выполнения операций над наборами данных служат строчные команды. С помощью этих команд можно просматривать, редактировать, переименовывать, удалять, копировать, перемещать, каталогизировать наборы данных и выполнять многие другие действия.
Строчные команды для работы со списками состоят, как правило, из одного или двух символов и не имеют дополнительных параметров. Команды разрешается вводить как строчными, так и прописными буквами, начиная с любой позиции поля ввода, расположенного слева от имени набора данных в списке.
Строчные команды выполняют операции для тех элементов списка, рядом с которыми они указаны. Пользователь может указать одновременно несколько строчных команд в различных строках. Для перемещения курсора к полю строчных команд следующей строки можно использовать клавиши Tab или Enter. Активизация действия всех строчных команд происходит по нажатию клавиши ВВОД.
Список наиболее важных строчных команд утилиты Dslist приведен в таблице 5.7.
| E | Edit | Переход в режим редактирования |
| V | View | Переход в режим просмотра View |
| B | Browse | Переход в режим просмотра Browse |
| M | Member List | Выдать список разделов библиотеки |
| D | Delete | Удалить набор данных |
| R | Rename | Переименовать набор данных |
| I | Info | Выдать полную информацию о наборе данных |
| S | Short Info | Выдать краткую информацию о наборе данных |
| P | Вывести в набор данных печати | |
| C | Catalog | Каталогизировать указанный набор данных |
| U | Uncatalog | Исключить из каталога указанный набор данных |
| Z | Compress | Сжать библиотечный набор данных |
| F | Free | Освободить распределенное для набора данных, но неиспользуемое пространство внешней памяти |
| PX | Print Index | Вывести основную информацию о библиотеке и список ее разделов в набор данных печати |
| RES | Reset | Корректировка статистики разделов библиотеки |
| MO | Move | Перемещение набора данных |
| CO | Copy | Копирование набора данных |
| X | Exclude | Исключить набор данных из списка |
| NX | Unexclude | Восстановить ранее исключенные из списка наборы данных команды |
Для библиотечных наборов данных команды E, V, B и M приводят к отображению панели списка разделов, где пользователь может указать, какие разделы должны быть обработаны с помощью соответствующих строчных команд. Многие команды, такие как D, R, RES, CO, и MO инициируют вывод специальных панелей или окон для ввода дополнительных параметров.
Для пользователей, которые не помнят мнемонику строчных команд, существует альтернативная возможность выбора требуемого действия. В этом случае следует ввести символ "/" в поле строчных команд или просто подвести курсор к имени набора данных и нажать клавишу ВВОД. На экране появится всплывающее окно со списком выбора допустимых действий, соответствующих представленным в таблице. Для выбора действия пользователь должен в поле ввода указать номер соответствующей функции и вновь нажать клавишу ВВОД.
Рассмотрим особенности выполнения некоторых наиболее важных строчных команд (получение информации о наборе данных, переименование и удаление).
Операция получения информации о наборе данных доступна пользователю в одном из двух форматов - полном или кратком, в зависимости от используемой строчной команды I или S соответственно. Способ представления и совокупность параметров, характеризующих набор данных, зависит от типа набора, устройства и других факторов. В частности, сведения о SMS наборах данных имеют особый формат. На рис. 5.50
приведен пример представления полной информации об однотомном дисковом наборе данных, включающий:
сведения о размещении, параметрах организации набора данных и общая информация (General Data): серийный номер тома (Volume serial), тип устройства (Device type), тип организации (Organization), формат записи (Record format), длина записи (Record length), размер блока (Block size); количество блоков в первом экстенте (1st extent blocks), количество добавляемых к набору данных блоков (Secondary blocks)характеристики выделенного пространства дисковой памяти (Current Allocation): общее количество блоков (Allocated blocks), количество экстентов (Allocated extents), количество блоков оглавления (Maximum dir.
blocks); характеристики используемого пространства дисковой памяти (Current Utilization): занято блоков (Used blocks), занято экстентов (Used extents), занято блоков оглавления (Used dir. blocks), количество разделов (Number of Members);даты создания (Creation date), последнего использования (Referenced date) и срок хранения (Expiration date).
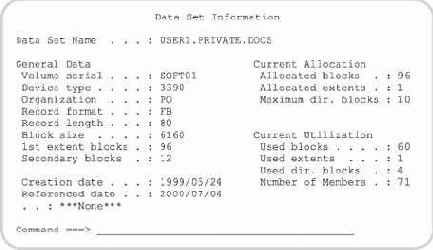
Рис. 5.50. Информация о наборе данных
Возврат в панель списка наборов данных производится по нажатию F3.
Для переименования набора данных служит строчная команда R, которая использует дополнительное всплывающее окно для ввода нового имени набора данных (рис. 5.51). Имя вводится либо в стиле библиотеки ISPF либо произвольным образом, как в данном примере, где переименовывается набор данных MY.TEST.DATASET в YOUR.TEST.DATASET.
Для подтверждения операции пользователь должен нажать на клавишу ВВОД , для отмены переименования - ввести команду END (F3).
Для удаления набора данных пользователь должен ввести строчную команду D. Если в панели утилиты Dslist был установлен переключатель Confirm Data Set Delete, на экран будет выведено всплывающее окно, запрашивающее подтверждение на удаление (рис. 5.52). Для подтверждения удаления необходимо нажать клавишу ВВОД, для отмены - ввести команду END (F3).
Рис. 5.51. Переименование набора данных
Рис. 5.52. Панель подтверждения удаления набора данных
Функциональные команды утилиты Dslist служат для управления представлением списка наборов данных и вводятся в поле Command. Рассмотрим некоторые из них.
Команда REFRESH не имеет параметров и предназначена для обновления отображаемого списка наборов данных после того, как были выполнены действия, изменившие его содержимое (например, после удаления наборов данных).
Команда RESET позволяет очистить панель от ранее сформированных сообщений и введенных строчных команд.
С помощью команды SORT можно переупорядочить список наборов данных по заданному полю. Формат команды
SORT [field1 [field2]]
где field1 - имя поля (колонки) списка, по которому будет производиться основная сортировка, field2 - имя поля, по которому будет производиться дополнительная сортировка при совпадении значений элементов поля field1.
Имена полей указаны в верхней части списка наборов данных. Например, для сортировки по имени тома и размеру блока (дополнительно) следует ввести команду:
SORT VOLUME BLKSZ
Если параметры команды SORT не указаны, список будет отсортирован по имени наборов данных, как это установлено по умолчанию. Порядок сортировки (по убыванию или возрастанию) зависит от выбранного поля.
Команда LOCATE (сокращенно L) предназначена для прокрутки экрана так, чтобы в верхней строке оказался элемент списка, задаваемый в качестве параметра:
LOCATE string
Значение string должно совпадать с первыми символами одного из значений поля, по которому список отсортирован в данный момент. По умолчанию таким полем является поле имени наборов данных.
Например, если список отсортирован по именам томов, можно ввести:
LOCATE WORK01
В результате прокрутки списка в верхней части экрана будет отображен первый набор данных, размещенный на томе WORK01.
Если указанное значение не найдено, то список будет позиционирован на ближайшее подходящее значение, предшествующее указанному.
Вставка пустых строк (I)
Формат команды:
I[n]
Строчная команда I (Insert) служит для вставки заданного количества (n) пустых строк после строки, содержащей эту команду. Если необходимо вставить одну строку, значение n не указывается.
Например, для вставки пяти пустых строк следует ввести команду i5:
i50004 Текст Текст Текст Текст Текст Текст. 000005 Текст Текст Текст Текст Текст Текст.
После нажатия на клавишу ВВОД получим:
000004 Текст Текст Текст Текст Текст Текст. '''''' '''''' '''''' '''''' '''''' 000005 Текст Текст Текст Текст Текст Текст.
Если пользователь введет какую-либо информацию во вставленную строку (даже пробел), при нажатии клавиши ВВОД строка становится частью исходных данных и ей присваивается номер. Если же такая строка останется пустой, то при нажатии клавиши ВВОД она будет автоматически удалена. Если пользователь введет информацию в последнюю (или единственную) вставленную строку и курсор будет оставаться среди данных этой строки, то при нажатии клавиши ВВОД за этой строкой автоматически вставляется новая пустая строка. Это позволяет вводить информацию строка за строкой в режиме "непрерывной" вставки.
в режиме удаленного доступа через
Работа пользователей операционной системы z/OS, как правило, осуществляется в режиме удаленного доступа через специальные терминалы или рабочие станции, подключенные к мэйнфрейму при помощи сетевых коммуникаций. Сегодня в качестве рабочих станций чаще всего используются персональные компьютеры (ПК), работающие под управлением операционных систем Windows или UNIX (Linux). В этом случае для взаимодействия с мэйнфреймом используются специальные программы эмуляции терминала, которые устанавливают связь с одним из приложений, выполняющимся на мэйнфрейме, воспроизводят на экране ПК исходящие от него сообщения и передают ему управляющие воздействия пользователя, вводимые с клавиатуры.
В z/OS поддерживается два основных интерфейса диалогового взаимодействия с пользователем: TSO/E и ISPF (рис. 5.29).
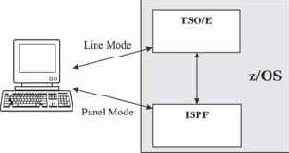
Рис. 5.29. Средства поддержки пользователей в z/OS
Подсистема разделения времени TSO/E (Time Sharing Option/Extension) реализует одновременную поддержку множества независимых параллельных пользовательских сеансов [21]. Пользовательский интерфейс TSO/E реализован по типу "командной строки" (Line Mode). Каждый пользователь TSO/E при помощи специальных команд получает возможность выполнять операции над наборами данных, запускать задания и контролировать ход их выполнения, использовать устройства, связываться с другими пользователями и т.п. В TSO/E поддерживаются языки создания командных процедур CLIST и REXX.
ISPF (Interactive System Productivity Facility) - программный продукт, выполняющийся под управлением TSO/E и обеспечивающий поддержку диалоговой среды пользователя (Panel Mode). ISPF использует традиционные для полноэкранного режима работы средства пользовательского интерфейса, такие как: окна (панели), меню, всплывающие окна, списки, поля ввода и другие элементы управления, регламентированные международным стандартом CUA/SAA. Использование ISPF делает работу пользователя за терминалом значительно более комфортной, при этом возможность пользоваться стандартными командами TSO/E сохраняется.
Среда ISPF используется:
администраторами системы для управления наборами данных, томами, системными библиотеками и т.п.программистами для разработки и выполнения интерактивных и пакетных программ;пользователями для взаимодействия с прикладными программами и работы с наборами данных.
Стандартная реализация ISPF ориентирована на текстовый режим работы терминала, однако существует режим поддержки графического пользовательского интерфейса в стиле Windows. ISPF включает не только средства реализации, но и средства разработки диалогового интерфейса с различными приложениями z/OS.
Следует отметить, что пользователи сред TSO и ISPF имеют возможность получить доступ к системному сервису z/OS UNIX на основе классического пользовательского интерфейса UNIX shell, а также через специальные панели ISPF.
Базовые средства создания программ
На рис. 5.59 представлены классическая последовательность этапов и базовые средства разработки программного обеспечения в операционной системе z/OS [27].
Исходный модуль, содержащий текст программы на одном из поддерживаемых языков программирования, может быть создан средствами TSO/ISPF/UNIX shell или подготовлен, а затем импортирован с рабочей станции. Для размещения исходного модуля может быть использован последовательный или библиотечный (PDS, PDSE) набор данных или файл z/OS UNIX. Компиляция исходного текста программы осуществляется встроенным языковым компилятором или ассемблером. z/OS включает как новые 64-разрядные компиляторы для таких языков, как, например, С/С++ и Cobol, так и множество старых версий. Компиляторы, которые могут запускаться как в пакетном, так и в интерактивном режиме, формируют объектный модуль, содержащий откомпилированный код и необходимые вспомогательные таблицы. Объектные модули обычно размещаются в наборе данных (библиотеке объектных модулей) или файле UNIX для последующего связывания с другими объектными модулями, размещенными в системных или пользовательских библиотеках. Компиляторы языков С/С++ и Cobol, а также HL Assembler дают возможность получить объектные модули расширенных форматов XOBJ или GOFF (Generalized Object File Format), допускающих использование длинных внешних имен (до 32767 байт).
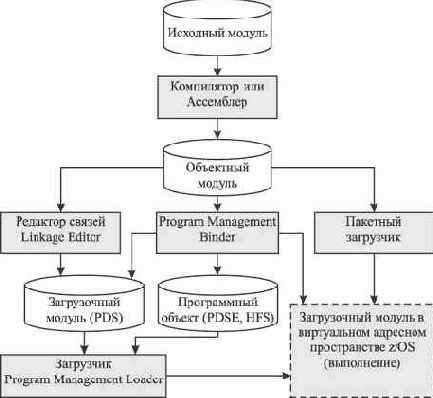
Рис. 5.59. Базовые средства разработки приложений в z/OS
Процедура редактирования связей (link edit) объединяет все необходимые объектные модули в единый загрузочный модуль, готовый к выполнению. Для хранения загрузочных модулей создаются специальные PDS- или PDSE-библиотеки, использующие формат записей RECFM=U. Ранее отмечалось, что в конфигурации z/OS обычно предусматривается несколько системных библиотек загрузочных модулей (SYS1.LINKLIB и др.), описываемых в разделе LNKLST реестра SYS1.PARMLIB.
z/OS включает два редактора связей: стандартный Linkage Editor и усовершенствованный Program Management Binder (или просто Binder1)).
Стандартный редактор связей служит для построения загрузочных модулей "старого" формата, ориентированных на размещение в PDS-библиотеках и поддерживающих только 24- и 31-разрядные режимы адресации с ограничением общего объема кода в 16 MB. Binder обеспечивает возможность связывания объектных и загрузочных модулей в загрузочные модули нового формата - программные объекты (program object). Программные объекты включают все возможности стандартных загрузочных модулей и, кроме того, поддерживают режим 64-разрядной адресации и объектные модули расширенного формата, а также допускают увеличение объема кода до 1 GB. Программные объекты могут размещаться только в библиотечных наборах данных типа PDSE или в файлах HFS UNIX. Отметим, что Binder позволяет также создавать стандартные загрузочные модули, размещаемые в PDS, а с помощью утилиты IEBCOPY можно производить преобразование загрузочных модулей в программные объекты и обратно.
На этапе редактирования связей программный объект можно настроить определенным образом с помощью специальных параметров (опций), среди которых следует выделить следующие:
AMODE - устанавливает используемый режим адресации (24, 31 или 64 бит);RMODE - устанавливает область размещения в адресном пространстве (ниже границы 16 MB или произвольно);REUS - устанавливает режим повторного использования (реентерабельный, используемый последовательно, обновляемый).
Редактор связей и Binder позволяют создавать динамические загрузочные модули (программные объекты), которые во время выполнения могут обращаться к внешним модулям с помощью макровызовов LOAD, LINK, XCTL, ATTACH.
Готовая к выполнению программа (загрузочный модуль или программный объект) запускается на выполнение универсальной программой загрузчиком
(Program Management Loader). Загрузчик производит размещение программы в виртуальном адресном пространстве и подготавливает ее к выполнению, осуществляя настройку адресных констант. Обычно сразу же после загрузки программа получает управление, то есть начинает выполняться под управлением ОС.
Как видно из рис. 5.59, существует возможность выполнять загрузку программ, минуя стадию сохранения загрузочного модуля (программного объекта) в библиотеке. Для этой цели может использоваться Binder или же специальный пакетный загрузчик (Batch Loader), который на основе объектного модуля строит загрузочный модуль "старого" формата и размещает его в виртуальной памяти.
Средства разработки пакетного режима
Традиционный способ разработки программ, применяемый программистами в течение десятилетий, основан на использовании средств пакетного режима, реализуемых в сеансе TSO/E или ISPF/PDF. Ключевым элементом данного способа является использование стандартных процедур JCL, хранящихся в системной библиотеке SYS1.PROCLIB и предназначенных для компиляции, редактирования связей и исполнения различных HLL-программ. В таблице 5.9 представлен список некоторых таких процедур.
| HL Assembler | ASMAC | ASMACL | ASMACLG |
| C++ | CBCC | CBCСB, CBCCL | CBCCBG, CBCCLG |
| C | EDCC | EDCСB, EDCСL | EDCCBG, EDCСLG |
| COBOL | IGYWC | IGYWCL | IGYWCLG |
| Pl/1 | IEL1C | IEL1CL, IBMZCB | IEL1CLG, IBMZCBG |
Процедуры, предназначенные только для компиляции (имя процедуры заканчивается символом "C"- Compile), служат для создания и сохранения объектного модуля программы. Процедуры компиляции и редактирования служат для создания загрузочного модуля и сохранения его в библиотеке. Символы "CL" или "CB" в имени процедуры указывают на применение соответственно стандартного редактора связей Linkage Editor или редактора Binder. Последняя группа процедур (имена заканчиваются на "CLG" или "CBG") предназначена для выполнения программы, представленной в исходном коде, причем объектный и загрузочный модули могут не сохраняться в постоянных наборах данных.
В качестве примера использования каталогизированной процедуры рассмотрим процедуру ASMACLG, предназначенную для компиляции, редактирования связей и выполнения ассемблерной программы, представленной в виде исходного модуля [29]. Текст процедуры приведен на рис. 5.61.
Процедура ASMACLG состоит из трех шагов. На первом шаге (C) вызывается компилятор ассемблера ASMA90, на втором шаге (L) - редактор связей IEWL, а на третьем (G) - запускается созданный загрузочный модуль. Процедура не содержит символических параметров, поскольку необходимые средства настройки доступны через модификацию DD и EXEC операторов.
С помощью модификации операторов DD можно определить собственные наборы данных для размещения исходного текста программы (C.SYSIN), объектного (C.SYSLIN) и загрузочного (L.SYSLMOD) модулей, исходных данных программы (G.SYSIN). Для задания требуемого набора опций компилятора и редактора связей следует модифицировать параметр PARM соответствующего оператора EXEC (PARM.C и PARM.L).
Рис. 5.61. Каталогизированная процедура ASMACLG
Рассмотрим некоторые варианты применения процедуры ASMACLG при разработке ассемблерных программ:
исходный модуль и исходные данные разрабатываемой программы представлены во входном потоке:
//TEST JOB ... // EXEC ASMACLG,PARM.C=LIST,PARM.L=NOMAP //C.SYSIN DD * строки исходной программы ... /* //G.SYSIN DD * исходные данные ... исходный модуль и исходные данные представлены в заранее подготовленных каталогизированных наборах данных USER.ASM и USER.DATA:
//TEST JOB ... // EXEC ASMACLG,PARM.C=LIST,PARM.L=NOMAP //C.SYSIN DD DSN=USER.ASM(PRG3),DISP=OLD //G.SYSIN DD DSN=USER.DATA(TABL1),DISP=OLD
При работе в среде ISPF/PDF текст задания формируется с помощью текстового редактора EDIT. Запуск задания можно производить прямо из редактора с помощью команды SUBMIT. Отчет о выполнении задания можно получить и просмотреть либо с помощью утилиты Outlist, либо средствами компонента SDSF.
Средства разработки программ в ISPF/PDF
Наряду с традиционным способом создания приложений на основе пакетных заданий, ISPF/PDF поддерживает два специальных режима разработки, доступных через главное меню: интерактивный (Foreground) и пакетный (Batch). Эти режимы предназначены для компиляции исходных программ и получения объектных модулей для множества поддерживаемых в z/OS языков программирования (ассемблер, Fortran, COBOL, С/С++, PL/I, REXX, DTL и др.). Помимо средств компиляции, здесь доступны также интерактивные отладчики для языков COBOL и Fortran, редакторы связей (Binder и Linkage editor), а также утилита для определения связей между модулями программы (Member Parts List).
Рассмотрим более подробно функцию 4 ISPF/PDF "Интерактивный режим" (Foreground), которая обеспечивает поддержку средств разработки программ в интерактивном режиме [19]. Главная панель функции представлена на рис. 5.62. Пользователь может выбрать интересующую его программу, введя соответствующий номер в командную строку и нажав клавишу ВВОД. Если исходный набор данных упакован и выбранная функция поддерживает работу с упакованными данными (не отмечена звездочкой), предварительно следует установить переключатель Source Data Packed.
Рис. 5.62. Главная панель функции интерактивного режима (Foreground)
Рассмотрим особенности использования компиляторов в интерактивном режиме на примере HL Assembler. В этом случае на главной панели следует ввести 1, нажать ВВОД и перейти к панели настройки параметров компиляции, представленной на рис. 5.63. Исходный текст программы для выбранного компилятора может быть представлен двумя способами: в виде раздела библиотеки ISPF или как произвольный набор данных (например, как последовательный набор данных).

Рис. 5.63. Панель настройки параметров ассемблера
Если исходный модуль представлен в виде раздела библиотечного набора данных, существует возможность определить дополнительные исходные библиотеки, в которых могут находиться включаемые фрагменты текста (например, описываемые с помощью директивы INCLUDE).
Имена дополнительных исходных библиотек вводятся в поле Additional input libraries с использованием апострофов:
===" 'ABC.MACROS'
Если имя раздела для библиотечного набора данных не указано, появится панель списка разделов, где следует сделать выбор с помощью строчной команды S. Если исходный набор данных защищен паролем, в поле Password нужно ввести пароль.
Отчет (листинг), сформированный компилятором, будет размещен в наборе данных, имя которого выбирается автоматически в соответствии с шаблоном:
[prefix.]userid.listid.LIST
где prefix - префикс для наборов данных, установленный в пользовательском профиле TSO, userid - идентификатор пользователя, с которым он открыл сеанс работы, listid - имя, заданное пользователем в одноименном поле панели. Если префикс TSO совпадает с идентификатором пользователя, то квалификатор prefix не используется.
Если исходный набор данных является последовательным, то поле List ID обязательно должно быть заполнено. Для раздела библиотечного набора данных значение listid по умолчанию совпадает с именем исходного раздела.
Одно из полей панели предназначено для ввода параметров настройки (опций) используемого компилятора (Assembler Options). Следует обратить внимание, что для любого компилятора две опции считаются установленными по умолчанию:
опция OBJECT - требует сохранить объектный код в наборе данных;опция LIST - требует сохранить выходной отчет в наборе данных.
Остальные опции устанавливаются в соответствии с допустимым перечнем, описанным в руководстве по соответствующему компилятору.
После определения всех необходимых параметров следует нажать клавишу ВВОД. Через некоторое время в нижней части экрана появится сообщение:
HIGH LEVEL ASSEMBLER STARTED ***
Требуется вновь нажать клавишу ВВОД.
При выполнении компиляции и ассемблирования автоматически создается сохраняемый объектный модуль. Если исходный модуль определен в виде раздела библиотеки ISPF c именем вида PROJECT.GROUP.TYPE(MEMBER), то объектный код будет записан в раздел MEMBER библиотечного набора данных с именем PROJECT.GROUP.OBJ.
Если исходный модуль задан как произвольный набор данных, объектный модуль будет сформирован в наборе данных такого же типа и с таким же именем, только последний квалификатор имени примет значение OBJ.
Если процедура компиляции завершится нормально, на экране автоматически будет отображен выходной отчет в режиме просмотра BROWSE. После выхода из режима просмотра пользователь может произвести обработку отчета с помощью утилиты печати (Foreground Print Options). Если же процедура компиляции завершится некорректно, будет выдано короткое сообщение о причине, и перехода в режим просмотра и печати отчета не произойдет.
Особый интерес представляет использование в интерактивном режиме процедуры редактирования связей. Функция редактирования связей предназначена для получения загрузочного модуля на основе созданного на этапе компиляции объектного модуля и других объектных модулей, содержащихся в системных и пользовательских библиотеках. Панель настройки параметров редактирования связей представлена на рис. 5.64.
Рис. 5.64. Панель настройки параметров редактора связей
Объектный код программы может быть задан двумя способами: в виде раздела библиотеки ISPF или как произвольный набор данных (например, последовательный набор данных). Дополнительные библиотеки объектных и загрузочных модулей, необходимые для работы редактора, задаются путем ввода их имен в поля, помеченные как SYSLIB и SYSLIN.
В поле Linkage editor/binder options можно указать опции выбранного редактора связей. При этом следует иметь в виду, что ISPF всегда автоматически устанавливает следующие опции:
LOAD - требует сохранить загрузочный модуль в библиотечном наборе данных;LIB - определяет последовательность обработки входных наборов данных;PRINT - требует сохранить выходной отчет в наборе данных.
Тип используемого редактора связей (Binder или Linkage editor) задается с помощью списка выбора Processor. Значение поля List ID служит для формирования имени набора данных, содержащего листинг редактора связей.
Имя формируется по шаблону [prefix.]userid.listid.LINKLIST в соответствии с правилами, изложенными выше.
Создаваемый в результате загрузочный модуль будет размещен в наборе данных с именем, заканчивающимся квалификатором LOAD (по аналогии с образованием имен объектных модулей).
Практически все описанные выше средства интерактивного режима доступны и при использовании функции 5 ISPF/PDF "Пакетный режим" (Batch), которая обеспечивает поддержку средств разработки программ в пакетном режиме (рис. 5.65). Основное отличие от интерактивного режима заключается в том, что терминал освобождается для выполнения другой работы сразу же после запуска пакетного задания.
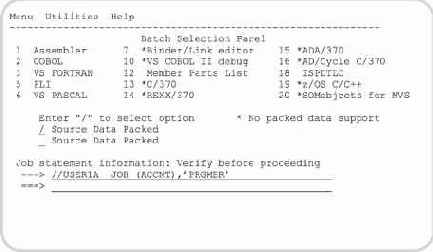
Рис. 5.65. Панель настройки параметров ассемблера
При вызове компилятора или редактора связей в пакетном режиме ISPF автоматически генерирует текст задания, включая в него все необходимые инструкции в соответствии с параметрами, определенными пользователем. Пользователь может непосредственно описать несколько инструкций, в том числе инструкцию JOB, работая с полями панели Job Statement Information.
Отчет о выполнении задания может быть помещен в указанный набор данных или направлен на печать путем настройки в выбранной панели компилятора или ассемблера. Первая возможность связана с установкой параметра List ID и описана выше. Вторая возможность реализуется при вводе выходного класса задания в поле SYSOUT class. В этом случае просмотр отчета можно произвести с помощью утилиты Outlist или SDSF, как было описано выше.
Выход из функции Batch с использованием команд END, RETURN или прямого перехода (=) приведет к автоматическому запуску сформированного задания (SUBMIT).
Универсальная языковая среда Language Environment
Базовый компонент z/OS Language Environment (LE) поддерживает единую универсальную среду выполнения (run-time environment) для приложений, созданных на языках программирования высокого уровня (HLL) C/C++, COBOL, PL/1 и Fortran [28]. Языковая среда LE включает наиболее существенные и часто используемые сервисы времени выполнения, такие как формирование сообщений, обработка событий, управление памятью, поддержка функций даты и времени и т.п. Эти сервисы доступны всем приложениям, независимо от используемого языка программирования. Кроме того, LE упрощает взаимодействие между приложениями, написанными на разных языках или для разных операционных сред, за счет специальных интерфейсных средств.
Языковая среда z/OS V1R4 поддерживает приложения, полученные с помощью следующих версий компиляторов:
z/OS C/C++, C/C++ Compiler for MVS/ESA, AD/Cycle C/370 Compiler;Enterprise COBOL for z/OS and OS/390, COBOL for OS/390 & VM, COBOL for MVS & VM;Enterprise PL/I for z/OS and OS/390, PL/I for MVS & VM, VisualAge PL/I for OS/390;VS Fortran, Fortran IV;VisualAge for Java, Enterprise Edition for OS/390.
Приложения, написанные на HL Assembler, также могут использовать средства LE через соответствующие макровызовы.
Языковая среда LE состоит из следующих элементов (рис. 5.60):
базовые программы (basic routines), обеспечивающие универсальную обработку сообщений, запуск и завершение программ, динамическое распределение памяти, обработку событий (в том числе ошибок) времени выполнения, взаимодействие между программами, написанными на разных языках;общие библиотеки (common library service), содержащие набор модулей для поддержки математических функций и функций даты и времени, реализуемых на основе стандартного интерфейса вызовов функций LE (callable services);специфические библиотеки (language specific RTL), содержащие модули, применяемые только для одного из поддерживаемых языков HLL.
Рис. 5.60. Универсальная среда выполнения программ Language Environment
Создаваемые с использованием универсальных модулей LE-приложения могут выполняться в различных операционных средах, включая как внутрисистемные (TSO, пакетный режим, UNIX shell), так и среды промежуточного слоя (DB2, CICS, IMS). Следует отметить, что программы, входящие в состав библиотек LE, делятся на две группы: резидентные и динамические. Резидентные программы при редактировании связей включаются в загрузочный модуль приложения. Они представлены в библиотечных наборах данных SCEELKED и SCEEBIND. К ним относятся, например, программы запуска и завершения. Динамические программы, размещаемые в библиотеках SCEERUN и SCEERUN2, не включаются в загрузочный код, а загружаются при вызове во время выполнения.
Объединяя средства, доступные в программах, написанных на разных языках, Language Environment устанавливает единую универсальную модель среды выполнения приложений, основанную на целом ряде понятий и терминов, которые следует освоить программисту:
Enclave - программа (главная программа вместе с подпрограммами);Routine - подпрограмма, функция;Process - программный код, данные и ресурсы, связанные с выполняющейся программой;Thread - поток, независимо диспетчеризуемая часть процесса;Local data - локальные данные подпрограммы;External data - данные, доступные для любых элементов анклава.
