Распределение памяти фиксированными разделами
Самым простым способом управления оперативной памятью является разделение ее на несколько разделов фиксированной величины. Это может быть выполнено вручную оператором во время старта системы или во время ее генерации. Очередная задача, поступившая на выполнение, помещается либо в общую очередь (рисунок 2.9,а), либо в очередь к некоторому разделу (рисунок 2.9,б).
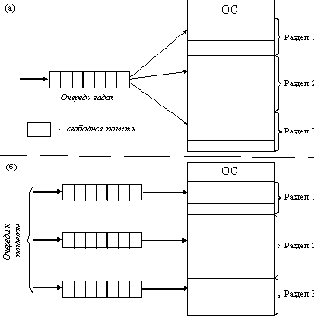
Рис. 2.9. Распределение памяти фиксированными разделами:
а - с общей очередью; б - с отдельными очередями
Подсистема управления памятью в этом случае выполняет следующие задачи:
сравнивая размер программы, поступившей на выполнение, и свободных разделов, выбирает подходящий раздел,
осуществляет загрузку программы и настройку адресов.
При очевидном преимуществе - простоте реализации - данный метод имеет существенный недостаток - жесткость. Так как в каждом разделе может выполняться только одна программа, то уровень мультипрограммирования заранее ограничен числом разделов не зависимо от того, какой размер имеют программы. Даже если программа имеет небольшой объем, она будет занимать весь раздел, что приводит к неэффективному использованию памяти. С другой стороны, даже если объем оперативной памяти машины позволяет выполнить некоторую программу, разбиение памяти на разделы не позволяет сделать этого.
Распределение памяти разделами переменной величины
В этом случае память машины не делится заранее на разделы. Сначала вся память свободна. Каждой вновь поступающей задаче выделяется необходимая ей память. Если достаточный объем памяти отсутствует, то задача не принимается на выполнение и стоит в очереди. После завершения задачи память освобождается, и на это место может быть загружена другая задача. Таким образом, в произвольный момент времени оперативная память представляет собой случайную последовательность занятых и свободных участков (разделов) произвольного размера. На рисунке 2.10 показано состояние памяти в различные моменты времени при использовании динамического распределения. Так в момент t0 в памяти находится только ОС, а к моменту t1 память разделена между 5 задачами, причем задача П4, завершаясь, покидает память. На освободившееся после задачи П4 место загружается задача П6, поступившая в момент t3.

Рис. 2.10. Распределение памяти динамическими разделами
Задачами операционной системы при реализации данного метода управления памятью является:
ведение таблиц свободных и занятых областей, в которых указываются начальные адреса и размеры участков памяти,
при поступлении новой задачи - анализ запроса, просмотр таблицы свободных областей и выбор раздела, размер которого достаточен для размещения поступившей задачи,
загрузка задачи в выделенный ей раздел и корректировка таблиц свободных и занятых областей,
после завершения задачи корректировка таблиц свободных и занятых областей.
Программный код не перемещается во время выполнения, то есть может быть проведена единовременная настройка адресов посредством использования перемещающего загрузчика.
Выбор раздела для вновь поступившей задачи может осуществляться по разным правилам, таким, например, как "первый попавшийся раздел достаточного размера", или "раздел, имеющий наименьший достаточный размер", или "раздел, имеющий наибольший достаточный размер". Все эти правила имеют свои преимущества и недостатки.
По сравнению с методом распределения памяти фиксированными разделами данный метод обладает гораздо большей гибкостью, но ему присущ очень серьезный недостаток - фрагментация памяти. Фрагментация - это наличие большого числа несмежных участков свободной памяти очень маленького размера (фрагментов). Настолько маленького, что ни одна из вновь поступающих программ не может поместиться ни в одном из участков, хотя суммарный объем фрагментов может составить значительную величину, намного превышающую требуемый объем памяти.
Распределенная файловая система DFS OSF
Распределенная файловая система DFS OSF предназначена для обеспечения прозрачного доступа к любому файлу, расположенному в любом узле сети. Главная концепция такой распределенной файловой системы - это простота ее использования.
Распределенная файловая система должна иметь единое пространство имен. Файл должен иметь одинаковое имя независимо от того, где он расположен. Другими желательными свойствами являются интегрированная безопасность, согласованность и доступность данных, надежность и восстанавливаемость, производительность и масштабируемость до очень больших конфигураций без уменьшения производительности и независимое от места расположения управление и администрирование.
Распределенная файловая система DFS OSF базируется на известной файловой системе AFS (The Andrew File System).
Распределенная разделяемая память в Mach
Концепция внешних менеджеров памяти в Mach хорошо подходит для реализации распределенной страничной разделяемой памяти. В этом разделе будут кратко описаны некоторые из работ, выполненные в этой области. Основная идея состоит в том, чтобы получить единое, линейное виртуальное адресное пространство, которое разделяется между процессами, работающими на компьютерах, которые не имеют какой-либо физической разделяемой памяти. Когда нить ссылается на страницу, которой у нее нет, то происходит страничное прерывание. Требуемая страница отыскивается на одном из дисков сети, доставляется на ту машину, где произошел страничный сбой, и помещается в физическую память, так что нить может продолжать работать.
Так как Mach уже имеет менеджеры памяти для различных классов объектов, то естественно ввести новый объект памяти - разделяемую страницу. Разделяемые страницы управляются одним или более специальными менеджерами памяти. Одной из возможностей является существование единого менеджера памяти, который управляет всеми разделяемыми страницами. Другой вариант состоит в том, что для каждой разделяемой страницы или набора разделяемых страниц используется свой менеджер памяти, чтобы распределить нагрузку.
Еще одна возможность состоит в использовании различных менеджеров памяти для страниц с различной семантикой. Например, один менеджер памяти мог бы гарантировать полную согласованность памяти, означающую, что любое чтение, следующее за записью, всегда будет видеть самые свежие данные. Другой менеджер памяти мог бы предоставлять более слабую семантику, например, что чтение никогда не возвращает данные, которые устарели более, чем на 30 секунд.
Рассмотрим наиболее общий случай: одна разделяемая страница, централизованное управление и полная согласованность памяти. Все остальные страницы локальны для каждой отдельной машины. Для реализации этой модели нам понадобится один менеджер памяти, который обслуживает все машины системы. Назовем его сервером распределенной разделяемой памяти (Distributed Shared Memory, DSM).
DSM- сервер обрабатывает ссылки на разделяемую страницу. Обычные менеджеры памяти управляют остальными страницами. До сих пор мы молчаливо подразумевали, что менеджер или менеджеры памяти, которые обслуживают данную машину, должны быть локальными для этой машины. Фактически, из-за того, что коммуникации прозрачны в Mach, менеджер памяти не обязательно располагается на той машине, чьей памятью он управляет.
Разделяемая страница всегда доступна для чтения или записи. Если она доступна для чтения, то она может копироваться (реплицироваться) на различные машины. Если же она доступна для записи, то должна быть только одна ее копия. DSM-сервер всегда знает состояние разделяемой страницы, а также на какой машине или машинах она в настоящий момент находится. Если страница доступна для чтения, то DSM-сервер сам имеет ее действительную копию.
Предположим, что страница является доступной для чтения, и нить, работающая на какой-то машине, пытается ее прочитать. DSM-сервер просто посылает этой машине копию страницы, обновляет свои таблицы, чтобы зафиксировать еще одного читателя, и завершает на этом данную работу. Страница будет отображена в новой машине и помечена "для чтения".
Теперь предположим, что один из читателей пытается осуществить запись в эту страницу. DSM-сервер посылает сообщение ядру или ядрам, которые имеют эту страницу, с просьбой вернуть ее. Сама страница не должна передаваться, так как DSM-сервер имеет ее действительную копию. Все, что требуется, это подтверждение, что страница больше не используется. После того, как все ядра освободят страницу, писатель получает ее копию вместе с разрешением использовать ее для записи.
Если теперь кто-либо еще хочет использовать эту страницу (которая теперь доступна для записи), DSM-сервер говорит текущему ее владельцу, что ее нужно прекратить использовать и вернуть. Когда страница возвращается, она может быть передана одному или нескольким читателям или одному писателю. Возможны многие вариации этого централизованного алгоритма, например, не запрашивать возвращение страницы до тех пор, пока машина, владеющая ею, не попользуется в течение некоторого минимального времени.Возможно также и распределенное решение.
Распределенная служба безопасности
Имеется две больших группы функций службы безопасности: идентификация и авторизация. Идентификация проверяет идентичность объекта (например, пользователя или сервиса). Авторизация (или управление доступом) назначает привилегии объекту, такие как доступ к файлу.
Авторизация - это только часть решения. В распределенной сетевой среде обязательно должна работать глобальная служба идентификации, так как рабочей станции нельзя доверить функции идентификации себя или своего пользователя. Служба идентификации представляет собой механизм передачи третьей стороне функций проверки идентичности пользователя.
Служба безопасности OSF DCE базируется на системе идентификации Kerberos, разработанной в 80-е годы и расширенной за счет добавления элементов безопасности. Kerberos использует шифрование, основанное на личных ключах, для обеспечения трех уровней защиты. Самый нижний уровень требует, чтобы пользователь идентифицировался только при установлении начального соединения, предполагая, что дальнейшая последовательность сетевых сообщений исходит от идентифицированного пользователя. Следующий уровень требует идентификацию для каждого сетевого сообщения. На последнем уровне все сообщения не только идентифицируются, но и шифруются.
Система безопасности не должна сильно усложнять жизнь конечного пользователя в сети, то есть он не должен запоминать десятки паролей и кодов.
Весьма полезным сетевым средством для целей безопасности является служба прав доступа или, другими словами, авторизация. Служба авторизации OSF базируется на POSIX-совместимых списках прав доступа - ACL.
В то время как система Kerberos основана на личных ключах, в настоящее время широкое распространение получили методы, основанные на публичных ключах (например, метод RSA). OSF собирается сделать DCE-приложения переносимыми из Kerberos в RSA.
Распределенная служба каталогов
Задачей службы каталогов в распределенной сети является поиск сетевых объектов, то есть пользователей, ресурсов, данных или приложений. Служба каталогов (или иначе, имен ) должна отобразить большое количество системных объектов (пользователей, организаций, групп, компьютеров, принтеров, файлов, процессов, сервисов) на множество понятных пользователю имен. Эта проблема сложна даже для гомогенных сетей, так как персонал и оборудование перемещается, изменяет свои имена, местонахождение и т.д. В гетерогенных глобальных сетях служба каталогов становится намного более сложной, из-за необходимости синхронизации различных баз данных каталогов. Более того, при появлении в сети распределенных приложений служба каталогов должна начать отслеживание всех таких объектов и всех их компонентов.
Хорошая служба каталогов делает использование распределенного окружения прозрачным для пользователя. Пользователям не нужно знать расположение удаленного принтера, файла или приложения.
OSF определяет двухярусную архитектуру для службы каталогов для целей адресации межячеечного и глобального взаимодействия. Ячейка (cell) - это фундаментальная организационная единица для систем в DCE OSF. Ячейки могут иметь социальные, политические или организационные границы. Ячейки состоят из компьютеров, которые должны часто взаимодействовать друг с другом - это могут быть, например, рабочие группы, отделы, или отделения компаний. В общем случае компьютеры в ячейке географически близки. Размер ячеек изменяется от 2 до 1000 компьютеров, хотя OSF считает наиболее приемлемым диапазон от десятков до сотен компьютеров.
Некоторые производители и пользователи агитируют за реализацию X.500 как общей службы каталогов на всех уровнях. Но OSF полагает, что использование X.500 на уровне рабочей группы (то есть ячейки) было бы слишком громоздким из-за требований к программному обеспечению по производительности - особенно, когда более гибкие средства службы каталогов уровня ячейки уже существуют на рынке.
Распределенная служба времени
В распределенных сетевых системах необходимо иметь службу согласования времени. Многие распределенные службы, такие как распределенная файловая система и служба идентификации, используют сравнение дат, сгенерированных на различных компьютерах. Чтобы сравнение имело смысл, пакет DCE должен обеспечивать согласованные временные отметки.
Сервер времени OSF DCE - это система, которая поставляет время другим системам в целях синхронизации. Любая система, не содержащая сервера времени, называется клерком (clerk). Распределенная служба времени использует три типа серверов для координации сетевого времени. Локальный сервер синхронизируется с другими локальными серверами той же локальной сети. Глобальный сервер доступен через расширенную локальную или глобальную сети. Курьер (courier) - это специальный локальный сервер, который периодически сверяет время с глобальными серверами. Через периодические интервалы времени серверы синхронизируются друг с другом с помощью протокола DTS OSF. Этот протокол может взаимодействовать с протоколом синхронизации времени NTP сетей Internet.
Многие фирмы-потребители программного обеспечения уже используют или собираются использовать средства DCE, поэтому ведущие фирмы-производители программного обеспечения, такие как IBM, DEC и Hewlett-Packard, заняты сейчас реализацией и поставкой различных элементов и расширений этой технологии.
Одной из главных особенностей и достоинств пакета DCE OSF является тесная взаимосвязь всех его компонентов. Это свойство пакета иногда становится его недостатком. Так, очень трудно работать в комбинированном окружении, когда одни приложения используют базис DCE, а другие - нет. В версии 1.1 совместимость служб пакета с аналогичными средствами других производителей улучшена. Например, служба Kerberos DCE в текущей версии несовместима с реализацией Kerberos MIT из-за того, что Kerberos DCE работает на базе средств RPC DCE, а Kerberos MIT - нет. OSF обещает полную совместимость с Kerberos MIT в версии 1.1. Имеются и положительные примеры совместимости пакета DCE со средствами других производителей, например со средствами Windows NT.
Хотя Windows NT и не является платформой DCE, но их совместимость может быть достигнута за счет полной совместимости средств RPC. Поэтому, после достаточно тщательной работы на уровне исходных кодов, разработчики могут создать DCE-сервер, который сможет обслуживать Windows NT-клиентов, и Windows NT-сервер, который работает с DCE-клиентами.
Для того, чтобы стать действительно распространенным базисом для создания гетерогенных распределенных вычислительных сред, пакет DCE должен обеспечить поддержку двух ключевых технологий - обработку транзакций и объектно-ориентированный подход. Поддержка транзакций совершенно необходима для многих деловых приложений, когда недопустима любая потеря данных или их несогласованность. Две фирмы - IBM и Transarc - предлагают дополнительные средства, работающие над DCE и обеспечивающие обработку транзакций. Что же касается объектно-ориентированных свойств DCE, то OSF собирается снабдить этот пакет средствами, совместимыми с объектно-ориентированной архитектурой CORBA, и работающими над инфраструктурой DCE. После достаточно тщательной работы на уровне исходных кодов, разработчики могут создать DCE-сервер, который сможет обслуживать Windows NT-клиентов, и Windows NT-сервер, который работает с DCE-клиентами.
Для того, чтобы стать действительно распространенным базисом для создания гетерогенных распределенных вычислительных сред, пакет DCE должен обеспечить поддержку двух ключевых технологий - обработку транзакций и объектно-ориентированный подход. Поддержка транзакций совершенно необходима для многих деловых приложений, когда недопустима любая потеря данных или их несогласованность. Две фирмы - IBM и Transarc - предлагают дополнительные средства, работающие над DCE и обеспечивающие обработку транзакций. Что же касается объектно-ориентированных свойств DCE, то OSF собирается снабдить этот пакет средствами, совместимыми с объектно-ориентированной архитектурой CORBA и работающими над инфраструктурой DCE.
Распределенные файловые системы
Ключевым компонентом любой распределенной системы является файловая система. Как и в централизованных системах, в распределенной системе функцией файловой системы является хранение программ и данных и предоставление доступа к ним по мере необходимости. Файловая система поддерживается одной или более машинами, называемыми файл-серверами. Файл-серверы перехватывают запросы на чтение или запись файлов, поступающие от других машин (не серверов). Эти другие машины называются клиентами. Каждый посланный запрос проверяется и выполняется, а ответ отсылается обратно. Файл-серверы обычно содержат иерархические файловые системы, каждая из которых имеет корневой каталог и каталоги более низких уровней. Рабочая станция может подсоединять и монтировать эти файловые системы к своим локальным файловым системам. При этом монтируемые файловые системы остаются на серверах.
Важно понимать различие между файловым сервисом и файловым сервером. Файловый сервис - это описание функций, которые файловая система предлагает своим пользователям. Это описание включает имеющиеся примитивы, их параметры и функции, которые они выполняют. С точки зрения пользователей файловый сервис определяет то, с чем пользователи могут работать, но ничего не говорит о том, как все это реализовано. В сущности, файловый сервис определяет интерфейс файловой системы с клиентами.
Файловый сервер - это процесс, который выполняется на отдельной машине и помогает реализовывать файловый сервис. В системе может быть один файловый сервер или несколько, но в хорошо организованной распределенной системе пользователи не знают, как реализована файловая система. В частности, они не знают количество файловых серверов, их месторасположение и функции. Они только знают, что если процедура определена в файловом сервисе, то требуемая работа каким-то образом выполняется, и им возвращаются требуемые результаты. Более того, пользователи даже не должны знать, что файловый сервис является распределенным. В идеале он должен выглядеть также, как и в централизованной файловой системе.
Так как обычно файловый сервер - это просто пользовательский процесс (или иногда процесс ядра), выполняющийся на некоторой машине, в системе может быть несколько файловых серверов, каждый из которых предлагает различный файловый сервис. Например, в распределенной системе может быть два сервера, которые обеспечивают файловые сервисы систем UNIX и MS-DOS соответственно, и любой пользовательский процесс пользуется подходящим сервисом.
Файловый сервис в распределенных файловых системах (впрочем как и в централизованных) имеет две функционально различные части: собственно файловый сервис и сервис каталогов. Первый имеет дело с операциями над отдельными файлами, такими, как чтение, запись или добавление, а второй - с созданием каталогов и управлением ими, добавлением и удалением файлов из каталогов и т.п.
Распределенный алгоритм
Когда процесс хочет войти в критическую секцию, он формирует сообщение, содержащее имя нужной ему критической секции, номер процесса и текущее значение времени. Затем он посылает это сообщение всем другим процессам. Предполагается, что передача сообщения надежна, то есть получение каждого сообщения сопровождается подтверждением. Когда процесс получает сообщение такого рода, его действия зависят от того, в каком состоянии по отношению к указанной в сообщении критической секции он находится. Имеют место три ситуации:
Если получатель не находится и не собирается входить в критическую секцию в данный момент, то он отсылает назад процессу-отправителю сообщение с разрешением.
Если получатель уже находится в критической секции, то он не отправляет никакого ответа, а ставит запрос в очередь.
Если получатель хочет войти в критическую секцию, но еще не сделал этого, то он сравнивает временную отметку поступившего сообщения со значением времени, которое содержится в его собственном сообщении, разосланном всем другим процессам. Если время в поступившем к нему сообщении меньше, то есть его собственный запрос возник позже, то он посылает сообщение-разрешение, в обратном случае он не посылает ничего и ставит поступившее сообщение-запрос в очередь.
Процесс может войти в критическую секцию только в том случае, если он получил ответные сообщения-разрешения от всех остальных процессов. Когда процесс покидает критическую секцию, он посылает разрешение всем процессам из своей очереди и исключает их из очереди.
Расширяемость
В то время, как аппаратная часть компьютера устаревает за несколько лет, полезная жизнь операционных систем может измеряться десятилетиями. Примером может служить ОС UNIX. Поэтому операционные системы всегда эволюционно изменяются со временем, и эти изменения более значимы, чем изменения аппаратных средств. Изменения ОС обычно представляют собой приобретение ею новых свойств. Например, поддержка новых устройств, таких как CD-ROM, возможность связи с сетями нового типа, поддержка многообещающих технологий, таких как графический интерфейс пользователя или объектно-ориентированное программное окружение, использование более чем одного процессора. Сохранение целостности кода, какие бы изменения не вносились в операционную систему, является главной целью разработки.
Расширяемость может достигаться за счет модульной структуры ОС, при которой программы строятся из набора отдельных модулей, взаимодействующих только через функциональный интерфейс. Новые компоненты могут быть добавлены в операционную систему модульным путем, они выполняют свою работу, используя интерфейсы, поддерживаемые существующими компонентами.
Использование объектов для представления системных ресурсов также улучшает расширяемость системы. Объекты - это абстрактные типы данных, над которыми можно производить только те действия, которые предусмотрены специальным набором объектных функций. Объекты позволяют единообразно управлять системными ресурсами. Добавление новых объектов не разрушает существующие объекты и не требует изменений существующего кода.
Прекрасные возможности для расширения предоставляет подход к структурированию ОС по типу клиент-сервер с использованием микроядерной технологии. В соответствии с этим подходом ОС строится как совокупность привилегированной управляющей программы и набора непривилегированных услуг-серверов. Основная часть ОС может оставаться неизменной в то время, как могут быть добавлены новые серверы или улучшены старые.
Средства вызова удаленных процедур (RPC) также дают возможность расширить функциональные возможности ОС. Новые программные процедуры могут быть добавлены в любую машину сети и немедленно поступить в распоряжение прикладных программ на других машинах сети.
Некоторые ОС для улучшения расширяемости поддерживают загружаемые драйверы, которые могут быть добавлены в систему во время ее работы. Новые файловые системы, устройства и сети могут поддерживаться путем написания драйвера устройства, драйвера файловой системы или транспортного драйвера и загрузки его в систему.
Разделение памяти
Разделение играет важную роль в Mach. Для разделения объектов нитями одного процесса никаких специальных механизмов не требуется: все они автоматически видят одно и то же адресное пространство. Если одна из них имеет доступ к части данных, то и все его имеют. Более интересной является возможность разделять двумя или более процессами одни и те же объекты памяти, или же просто разделять страницы памяти для этой цели. Иногда разделение полезно в системах с одним процессором. Например, в классической задаче производитель-потребитель может быть желательным реализовать производителя и потребителя разными процессами, но иметь общий буфер, в который производитель мог бы писать, а потребитель - брать из него данные.
В многопроцессорных системах разделение объектов между процессами часто более важно, чем в однопроцессорных. Во многих случаях задача решается за счет работы взаимодействующих процессов, работающих параллельно на разных процессорах (в отличие от разделения во времени одного процессора). Этим процессам может понадобиться непрерывный доступ к буферам, таблицам или другим структурам данных, для того, чтобы выполнить свою работу. Существенно, чтобы ОС позволяла такой вид разделения. Ранние версии UNIX'а не предоставляли такой возможности, хотя потом она была добавлена.
Рассмотрим, например, систему, которая анализирует оцифрованные спутниковые изображения Земли в реальном масштабе времени, в том темпе, в каком они передаются со спутника. Такой анализ требует больших затрат времени, и одно и то же изображение может проверяться на возможность его использования в предсказании погоды, урожая или отслеживании загрязнения среды. Каждое полученное изображение сохраняется как файл.
Для проведения такого анализа можно использовать мультипроцессор. Так как метеорологические, сельскохозяйственные и экологические программы очень отличаются друг от друга и разрабатываются различными специалистами, то нет причин делать их нитями одного процесса. Вместо этого каждая программа является отдельным процессом, который отображает текущий снимок в свое адресное пространство, как показано на рисунке 6.6.
Заметим, что файл, содержащий снимок, может быть отображен в различные виртуальные адреса в каждом процессе. Хотя каждая страница только один раз присутствует в памяти, она может оказаться в картах страниц различных процессов в различных местах. С помощью такого способа все три процесса могут работать над одним и тем же файлом в одно и то же время.
Другой важной областью разделяемости является создание процессов. Как и в UNIX'е, в Mach основным способом создания нового процесса является копирование существующего процесса. В UNIX'е копия всегда является двойником процесса, выполнившего системный вызов FORK в то время как в Mach потомок может быть двойником другого процесса (прототипа).
Одним из способов создания процесса-потомка состоит в копировании всех необходимых страниц и отображения копий в адресное пространство потомка. Хотя этот способ и работает, но он необоснованно дорог. Коды программы обычно используются в режиме только-для-чтения, так что их нельзя изменять, часть данных также может использоваться в этом режиме. Страницы с режимом только-для-чтения нет необходимости копировать, так как отображение их в адресные пространства обоих процессов выполнит необходимую работу. Страницы, в которые можно писать, не всегда могут разделяться, так как семантика создания процесса (по крайней мере в UNIX) говорит, что хотя в момент создания родительский процесс и процесс-потомок идентичны, последовательные изменения в любом из них невидимы в другом адресном пространстве.
Кроме этого, некоторые области (например, определенные отображенные файлы) могут не понадобиться процессу-потомку. Зачем связываться с массой забот, связанных с отображением, если эти области просто не нужны?

Рис. 6.6. Три процесса, разделяющие отображенный файл
Для обеспечения гибкости Mach позволяет процессу назначить атрибут наследования
Различные способы организации вычислительного процесса с использованием нитей
Один из возможных способов организации вычислительного процесса показан на рисунке 3.10,а. Здесь нить-диспетчер читает приходящие запросы на работу из почтового ящика системы. После проверки запроса диспетчер выбирает простаивающую (то есть блокированную) рабочую нить, передает ей запрос и активизирует ее, устанавливая, например, семафор, который она ожидает.
Когда рабочая нить активизируется, она проверяет, может ли быть выполнен запрос с данными разделяемого блока кэша, к которому имеют отношение все нити. Если нет, она посылает сообщение к диску, чтобы получить нужный блок (предположим, это READ), и переходит в состояние блокировки, ожидая завершения дисковой операции. В этот момент происходит обращение к планировщику, в результате работы которого активизируется другая нить, возможно, нить-диспетчер или некоторая рабочая нить, готовая к выполнению.
Структура с диспетчером не единственный путь организации многонитевой обработки. В модели "команда" все нити эквивалентны, каждая получает и обрабатывает свои собственные запросы. Иногда работы приходят, а нужная нить занята, особенно, если каждая нить специализируется на выполнении особого вида работ. В этом случае может создаваться очередь незавершенных работ. При такой организации нити должны вначале просматривать очередь работ, а затем почтовый ящик.
Нити могут быть также организованы в виде конвейера. В этом случае первая нить порождает некоторые данные и передает их для обработки следующей нити и т.д. Хотя эта организация и не подходит для файл-сервера, для других задач, например, задач типа "производитель-потребитель", это хорошее решение.
Нити часто полезны и для клиентов. Например, если клиент хочет растиражировать файл на много серверов, он может создать по одной нити для копирования на каждом сервере. Другое использование нитей клиентами - это управление сигналами, такими как прерывание с клавиатуры (del или break). Вместо обработки сигнала прерывания одна нить назначается для постоянного ожидания поступления сигналов.
Таким образом, использование нитей может сократить необходимое количество прерываний пользовательского уровня.

Рис. 3.10. Три способа организации нитей в процессе:
а - модель диспетчер/рабочие нити; б - модель "команда"; в - модель конвейера
Другой аргумент в пользу нитей не имеет отношения ни к удаленным вызовам, ни к коммуникациям. Некоторые прикладные задачи легче программировать, используя параллелизм, например задачи типа "производитель-потребитель". Не столь важно параллельное выполнение, сколь важна ясность программы. А поскольку они разделяют общий буфер, не стоит их делать отдельными процессами.
Наконец, в многопроцессорных системах нити из одного адресного пространства могут выполняться параллельно на разных процессорах. С другой стороны, правильно сконструированные программы, которые используют нити, должны работать одинаково хорошо на однопроцессорной машине в режиме разделения времени между нитями и на настоящем мультипроцессоре.
Реализация файловой системы VFS
UNIX System V Release 4 имеет массив структур vfssw [ ], каждая из которых описывает файловую систему конкретного типа, которая может быть установлена в системе. Структура vfssw состоит из четырех полей:
символьного имени файловой системы;
указателя на функцию инициализации файловой системы;
указателя на структуру, описывающую функции, реализующие абстрактные операции VFS в данной конкретной файловой системе;
флаги, которые не используются в описываемой версии UNIX.
Пример инициализированного массива структур vfssw:
struct vfssw vfssw[] = {
{0, 0 , 0 ,0 }, - нулевой элемент не используется
{"spec", specint, &spec_vfsops, 0}, - SPEC
{"vxfs", vx_init, &vx_vfsops, 0}, - Veritas
{"cdfs", cdfsinit, &cdfs_vfsops, 0}, - CD ROM
{"ufs", ufsinit, &ufs_vfsops, 0}, - UFS
{"s5", vx_init, &vx_vfsops, 0}, - S5
{"fifo", fifoinit, &fifovfsops, 0}, - FIFO
{"dos", dosinit, &dos_vfsops, 0}, - MS-DOS
Функции инициализации файловых систем вызываются во время инициализации операционной системы. Эти функции ответственны за создание внутренней среды файловой системы каждого типа.
Структура vfsops, описывающая операции, которые выполняются над файловой системой, состоит из 7 полей, так как в UNIX System V Release 4 предусмотрено 7 абстрактных операций над файловой системой:
| VFS_MOUNT | монтирование файловой системы, | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VFS_UNMOUNT | размонтирование файловой системы, | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VFS_ROOT | получение vnode для корня файловой системы, | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VFS_STATVFS | получение статистики файловой системы, | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VFS_SYNC | выталкивание буферов файловой системы на диск, | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VFS_VGET | получение vnode по номеру дескриптора файла, | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VFS_MOUNTROOT | монтирование корневой файловой системы. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
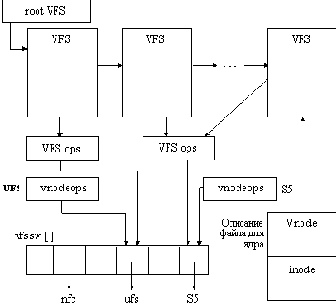
Рис. 5.6. Монтирование файловых систем в VFS
Операция VFS_MOUNT выполняет традиционное для UNIX монтирование файловой системы на указанный каталог уже смонтированной файловой системы для образования общего дерева, а операция VFS_UNMOUNT отменяет монтирование.
Операция VFS_ROOT используется при разборе полного имени файла, когда встречается дескриптор vnode, который связан со смонтированной на него файловой системой. Операция VFS_ROOT помогает найти vnode, который является корнем смонтированной файловой системы. Операция VFS_STATVFS позволяет получить независимую от типа файловой системы информацию о размере блока файловой системы, о количестве блоков и количестве свободных блоков в единицах этого размера, о максимальной длине имени файла и т.п. Операция VFS_SYNC выталкивает содержимое буферов диска из оперативной памяти на диск. Операция VFS_MOUNTROOT позволяет смонтировать корневую файловую систему, то есть систему, содержащую корневой каталог / общего дерева. Для указания того, какая файловая система будет монтироваться как корневая, в UNIX System V Release 4 используется переменная rootfstype, содержащая символьное имя корневой файловой системы, например "ufs".
Таким образом, в UNIX System V Release 4 одновременно в единое дерево могут быть смонтированы несколько файловых систем различных типов, поддерживающих операцию монтирования (рисунок 5.6).
| VOP_OPEN | - открыть файл | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VOP_CLOSE | - закрыть файл | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VOP_READ | - читать из файла | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VOP_WRITE | - записать в файл | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VOP_IOCTL | - управление в/в | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VOP_SETFL | - установить флаги статуса | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VOP_GETATTR | - получить атрибуты файла | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VOP_SETATTR | - установить атрибуты файла | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VOP_LOOKUP | - найти vnode по имени файла | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VOP_CREATE | - создать файл | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VOP_REMOVE | - удалить файл | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VOP_LINK | - связать файл | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| VOP_MAP | - отобразить файл в память | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Рис. 5.7. Абстрактные операции над файлами
Кроме операций над файловой системой в целом, для каждого типа файловой системы (s5, ufs и т.д.), установленной в ОС, необходимо описать способ реализации абстрактных операций над файлами, которые допускаются в VFS. Этот способ описывается для каждого типа файловой системы в структуре vnodeops, состав которой приведен на рисунке 5.7. Как видно из состава списка абстрактных операций, они образованы объединением операций, характерных для наиболее популярных файловых систем UNIX.
Для того, чтобы обращение к специфическим функциям не зависело от типа файловой системы, для каждой операции в vnodeops определен макрос с общим для всех типов файловых систем именем, например, VOP_OPEN, VOP_CLOSE, VOP_READ и т.п. Эти макросы определены в файле <sys/vnode.h> и соответствуют системным вызовам. Таким образом, в структуре vnodeops скрыты зависящие от типа файловой системы реализации стандартного набора операций над файлами. Даже если файловая система какого-либо конкретного типа не поддерживает определенную операцию над своими файлами, она должна создать соответствующую функцию, которая выполняет некоторый минимум действий: или сразу возвращает успешный код завершения, или возвращает код ошибки. Для анализа и обработки полного имени файла в VFS используется операция VOP_LOOKUP, позволяющая по имени файла найти ссылку на его структуру vnode.
Работа ядра с файлами во многом основана на использовании структуры vnode, поля которой представлены на рисунке 5.8. Структура vnode используется ядром для связи файла с определенным типом файловой системы через поле v_vfsp и конкретными реализациями файловых операций через поле v_op. Поле v_pages используется для указания на таблицу физических страниц памяти в случае, когда файл отображается в физическую память (этот механизм описан в разделе, описывающем организацию виртуальной памяти). В vnode также содержится тип файла и указатель на зависимую от типа файловой системы часть описания характеристик файла - структуру inode, обычно содержащую адресную информацию о расположении файла на носителе и о правах доступа к файлу. Кроме этого, vnode используется ядром для хранения информации о блокировках (locks), примененных процессами к отдельным областям файла.
Ядро в своих операциях с файлами оперирует для описания области файла парой vnode, offset, которая однозначно определяет файл и смещение в байтах внутри файла.

Рис. 5.8. Описатель файла - vnode
При каждом открытии процессом файла ядро создает в системной области памяти новую структуру типа file, которая, как и в случае традиционной файловой системы s5, описывает как открытый файл, так и операции, которые процесс собирается производить с файлом (например, чтение).
Структура file содержит такие поля, как:
flag - определение режима открытия (только для чтения, для чтения и записи и т.п.);
struct vnode * f_vnode - указатель на структуру vnode (заменивший по сравнению с s5 указатель на inode);
offset - смещение в файле при операциях чтения/записи;
struct cred * f_cred - указатель на структуру, содержащую права процесса, открывшего файл (структура находится в дескрипторе процесса);
а также указатели на предыдущую и последующую структуру типа file, связывающие все такие структуры в список.
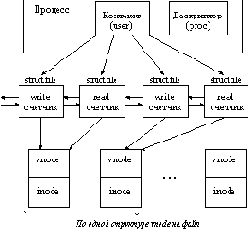
Рис. 5.9. Связь процесса с его файлами
Связь структур процесса с системным списком структур file показан на рисунке 5.9.
В отличие от структур типа file структуры типа vnode заводятся операционной системой для каждого активного (открытого) файла в единственном экземпляре, поэтому структуры file могут ссылаться на одну и ту же структуру vnode.
Структуры vnode не связаны в какой-либо список. Они появляются по требованию в системном пуле памяти и присоединяются к структуре данных, которая инициировала появление этого vnode, с помощью соответствующего указателя. Например, в случае структуры file в ней используется указатель f_vnode на соответствующую структуру vnode, описывающую нужный файл. Аналогично, если файл связан с образом процесса (то есть это файл, содержащий выполняемый модуль), то отображение сегмента памяти, содержащего части этого файла, осуществляется посредством указателя vp (в структуре segvn_data) на vnode этого файла.
Все операции с файлами в UNIX System V Release 4 производятся с помощью связанной с файлом структуры vnode. Когда процесс запрашивает операцию с файлом (например, операцию open), то независимая от типа файловой системы часть ОС передает управление зависимой от типа файловой системы части ОС для выполнения операции. Если зависимая часть обнаруживает, что структуры vnode, описывающей нужный файл, нет в оперативной памяти, то зависимая часть заводит для него новую структуру vnode.
Для ускорения доступа к файлам в UNIX System V Release 4 используется механизм быстрой трансляции имен файлов в соответствующие им ссылки на структуры vnode.Этот механизм основан на наличии кэша, хранящего максимально 800 записей о именах файлов и указателях vnode.
Реализация С-нитей в Mach
В Mach существует несколько реализаций С-нитей. Оригинальная реализация выполняет все нити в пользовательском пространстве внутри одного процесса. Этот подход основан на разделении во времени всеми С-нитями одной нити ядра, как это показано на рисунке 6.3, а. Этот подход может также использоваться в UNIX'е или любой другой системе, в которой нет поддержки нитей ядром. Такие нити работают как разные подпрограммы одной программы, что означает, что они планируются невытесняющим образом. Например, в случае типовой задачи "производитель-покупатель" производитель должен заполнить буфер, а затем заблокироваться, чтобы дать шанс покупателю на выполнение.

Рис. 6.3. Варианты реализаций С-нитей
(а) - Все C-нити используют одну нить ядра;
(б) - Каждая C-нить имеет свою собственную нить ядра;
(в) - Каждая C-нить имеет свой собственный однонитевый процесс
Данная реализация имеет недостаток, присущий всем нитевым пакетам, работающим в пользовательском пространстве без поддержки ядра. Если одна нить выполняет блокирующий системный вызов, например, чтение с терминала, то блокируется весь процесс. Чтобы избежать этой ситуации, программист должен избегать использовать блокирующие системные вызовы. В BSD UNIX имеется системный вызов SELECT, который может быть использован для того, чтобы узнать, имеется ли символ в буфере терминала. Но в целом операция остается запутанной.
Вторая реализация использует одну Mach-нить для одной С-нити, как показано на рисунке 6.3, б. Эти нити планируются с вытеснением. В многопроцессорных системах нити могут действительно работать параллельно на различных процессорах. Фактически возможно мультиплексирование m пользовательских нитей с n нитями ядра, хотя наиболее общим случаям является n=m.
В третьей реализации для каждого процесса выделяется одна нить ядра, как показано на рисунке 6.3, в. Процессы реализуются так, что их адресные пространства отображаются в одну и ту же физическую память, позволяя разделять ее тем же способом, что и в предыдущих реализациях. Данный способ поддержки нитей используется только тогда, когда требуется специализированное использование виртуальной памяти. Недостатком этого метода является то, что порты, UNIX-файлы и другие ресурсы процесса не могут разделяться.
Основное практическое значение первого подхода состоит в том, что в условиях отсутствия истинного параллелизма последовательное выполнение нити позволяет воспроизводить промежуточные результаты, облегчая процесс отладки.
Репликация
Распределенные системы часто обеспечивают репликацию (тиражирование) файлов в качестве одной из услуг, предоставляемых клиентам. Репликация - это асинхронный перенос изменений данных исходной файловой системы в файловые системы, принадлежащие различным узлам распределенной файловой системы. Другими словами, система оперирует несколькими копиями файлов, причем каждая копия находится на отдельном файловом сервере. Имеется несколько причин для предоставления этого сервиса, главными из которых являются:
1. Увеличение надежности за счет наличия независимых копий каждого файла на разных файл-серверах.
2. Распределение нагрузки между несколькими серверами.
Как обычно, ключевым вопросом, связанным с репликацией является прозрачность. До какой степени пользователи должны быть в курсе того, что некоторые файлы реплицируются? Должны ли они играть какую-либо роль в процессе репликации или репликация должна выполняться полностью автоматически? В одних системах пользователи полностью вовлечены в этот процесс, в других система все делает без их ведома. В последнем случае говорят, что система репликационно прозрачна.
На рисунке 3.12 показаны три возможных способа репликации. При использовании первого способа (а) программист сам управляет всем процессом репликации. Когда процесс создает файл, он делает это на одном определенном сервере. Затем, если пожелает, он может сделать дополнительные копии на других серверах. Если сервер каталогов разрешает сделать несколько копий файла, то сетевые адреса всех копий могут быть ассоциированы с именем файла, как показано на рисунке снизу, и когда имя найдено, это означает, что найдены все копии. Чтобы сделать концепцию репликации более понятной, рассмотрим, как может быть реализована репликация в системах, основанных на удаленном монтировании, типа UNIX. Предположим, что рабочий каталог программиста имеет имя /machine1/usr/ast. После создания файла, например, /machine1/usr/ast/xyz, программист, процесс или библиотека могут использовать команду копирования для того, чтобы сделать копии /machine2/usr/ast/xyz и machine3/usr/ast/xyz.
Возможно программа использует в качестве аргумента строку /usr/ast/xyz и последовательно попытается открывать копии, пока не достигнет успеха. Эта схема хотя и работает, но имеет много недостатков, и по этим причинам ее не стоит использовать в распределенных системах.
На рисунке 3.12,б показан альтернативный подход - ленивая репликация. Здесь создается только одна копия каждого файла на некотором сервере. Позже сервер сам автоматически выполнит репликации на другие серверы без участия программиста. Эта система должна быть достаточно быстрой для того, чтобы обновлять все эти копии, если потребуется.
Последним рассмотрим метод, использующий групповые связи (рисунок 3.12,в). В этом методе все системные вызовы ЗАПИСАТЬ передаются одновременно на все серверы, таким образом копии создаются одновременно с созданием оригинала. Имеется два принципиальных различия в использовании групповых связей и ленивой репликации. Во-первых, при ленивой репликации адресуется один сервер, а не группа. Во-вторых, ленивая репликация происходит в фоновом режиме, когда сервер имеет промежуток свободного времени, а при групповой репликации все копии создаются в одно и то же время.

Рис. 3.12. а) Точная репликация файла; б) Ленивая репликация файла;
в) Репликация файла, использующая группу
Рассмотрим, как могут быть изменены существующие реплицированные файлы. Существует два хорошо известных алгоритма решения этой проблемы.
Первый алгоритм, называемый "репликация первой копии", требует, чтобы один сервер был выделен как первичный. Остальные серверы являются вторичными. Когда реплицированный файл модифицируется, изменение посылается на первичный сервер, который выполняет изменения локально, а затем посылает изменения на вторичные серверы.
Чтобы предотвратить ситуацию, когда из-за отказа первичный сервер не успевает оповестить об изменениях все вторичные серверы, изменения должны быть сохранены в постоянном запоминающем устройстве еще до изменения первичной копии. В этом случае после перезагрузки сервера есть возможность сделать проверку, не проводились ли какие-нибудь обновления в момент краха.
Недостаток этого алгоритма типичен для централизованных систем - пониженная надежность. Чтобы избежать его, используется метод, предложенный Гиффордом и известный как "голосование". Пусть имеется n копий, тогда изменения должны быть внесены в любые W копий. При этом серверы, на которых хранятся копии, должны отслеживать порядковые номера их версий. В случае, когда какой-либо сервер выполняет операцию чтения, он обращается с запросом к любым R серверам. Если R+W > n, то, хотя бы один сервер содержит последнюю версию, которую можно определить по максимальному номеру.
Интересной модификацией этого алгоритма является алгоритм "голосования с приведениями". В большинстве приложений операции чтения встречаются гораздо чаще, чем операции записи, поэтому R обычно делают небольшим, а W - близким к N. При этом выход из строя нескольких серверов приводит к отсутствию кворума для записи. Голосование с приведениями решает эту проблему путем создания фиктивного сервера без дисков для каждого отказавшего или отключенного сервера. Фиктивный сервер не участвует в кворуме чтения (прежде всего, у него нет файлов), но он может присоединиться к кворуму записи, причем он просто записывает в никуда передаваемый ему файл. Запись только тогда успешна, когда хотя бы один сервер настоящий.
Когда отказавший сервер перезапускается, то он должен получить кворум чтения для обнаружения последней версии, которую он копирует к себе перед тем, как начать обычные операции. В остальном этот алгоритм подобен основному.
RPC
Хорошо известный механизм для реализации распределенных вычислений, RPC, расширяет традиционную модель программирования - вызов процедуры - для использования в сети. RPC может составлять основу распределенных вычислений. Теоретически программист не должен становиться экспертом по коммуникационным средствам для того, чтобы написать распределенное сетевое приложение. При использовании RPC программист будет применять специальный язык для описания операций. Данное описание обрабатывается компилятором, который создает код как для клиента, так и для сервера. Для обеспечения такого типа функций средства RPC должны быть простыми, прозрачными, надежными и высокопроизводительными.
Средства RPC пакета DCE OSF обладают простотой. Они приближаются к модели вызова локальных процедур насколько это возможно. Они почти не требуют изменения концептуального мышления программиста, и поэтому уменьшают время его переподготовки. Это особенно важно для коллективов программистов, работающих в фирмах, которые не являются производителями коммерческих программных продуктов.
Неизменность протокола - это другая особенность RPC DCE OSF. Этот протокол четко определен и не может изменяться пользователем (в данном случае разработчиком сетевых приложений). Такая неизменность, гарантируемая ядром, является важным свойством в гетерогенных средах, требующих согласованной работы. В отличие от OSF, некоторые другие разработчики средств RPC полагают, что гибкость и возможность приспосабливать эти средства к потребностям пользователей являются более важными.
Средства RPC DCE OSF поддерживают ряд транспортных протоколов и позволяют добавлять новые транспортные протоколы, сохраняя при этом свои функциональные свойства.
DCE RPC эффективно используется в других службах DCE: в службах безопасности, каталогов и времени, в распределенной файловой системе. DCE RPC интегрируется с системой идентификации для обеспечения защиты доступа и с нитями клиента и сервера для того, чтобы, сохраняя синхронный характер выполнения вызова, обеспечить параллелизм. Способность RPC посылать и получать потоки типизированных данных неопределенной длины используется в распределенной файловой системе.
Варианты ОС UNIX, производимые компанией
Варианты ОС UNIX, производимые компанией SCO и предназначенные исключительно для использования на Intel-платформах, до сих пор базируются на лицензированных исходных текстах System V 3.2. Однако SCO довела свои продукты до уровня полной совместимости со всеми основными стандартами (в тех позициях, для которых существуют стандарты). Консерватизм компании объясняется прежде всего тем, что ее реализация ОС UNIX включает наибольшее количество драйверов внешних устройств и поэтому может быть установлена практически на любой Intel-платформе. Естественно, при переходе на другой вариант опорных исходных текстов ядра системы могла бы потребоваться массовая переделка драйверов. Тем не менее SCO имеет соглашение с французской компанией Chorus Systems о разработки новой версии SCO UNIX, базирующейся на микроядре Chorus и предназначенной для использования в системах реального времени.
В настоящее время компания SCO приобрела у Novell ОС UnixWare и работает над версией UNIX, совмещающей особенности SCO UNIX и UnixWare в рамках одной системы.
Сегментно-страничный механизм
При включенной системе управления страницами работает как описанный выше сегментный механизм, так и механизм управления страницами, однако при этом смысл работы сегментного механизма меняется. В этом случае виртуальное адресное пространство задачи имеет размер в 4 Гбайта, в котором размещаются все сегменты (рисунок 2.22). По прежнему селектор задачи определяет номер виртуального сегмента, а смещение в команде задачи - смещение внутри этого сегмента. Так как теперь все сегменты разделяют одно адресное пространство, то возможно их наложение, но процессор не контролирует такие ситуации, оставляя эту проблему операционной системе. Первый этап преобразования виртуального адреса, связанный с преобразованием смещения и селектора с использованием таблиц GDT и LDT, содержащих дескрипторы сегментов, в точности совпадает с этапом преобразования этих данных при отключенном механизме управления страницами. Все структуры данных этих таблиц такие же. Однако, если раньше дескриптор сегмента содержал его базовый адрес в физическом адресном пространстве, и при сложении его со смещением из команды программы получался линейный искомый адрес в физической памяти, то теперь дескриптор содержит базовый адрес сегмента в виртуальном адресном пространстве. Поэтому в результате его сложения со смещением получается линейный виртуальный адрес, который на втором этапе (страничном) преобразуется в номер физической страницы. Для реализации механизма управления страницами как физическое, так и виртуальное адресное пространства разбиты на страницы размером 4 К. Всего в этих адресных пространствах насчитывается 1 М страниц. Несмотря на наличие нескольких виртуальных сегментов, все виртуальное адресное пространство задачи имеет общее разбиение на страницы, так что нумерация виртуальных страниц сквозная.
Линейный виртуальный адрес содержит в своих старших 20 разрядах номер виртуальной страницы, а в младших 12 разрядах смещение внутри страницы. Для отображения виртуальной страницы в физическую достаточно построить таблицу страниц, каждый элемент которой - дескриптор виртуальной страницы - содержал бы номер соответствующей ей физической страницы и ее атрибуты. В процессоре i386 так и сделано, и структура дескриптора страницы показана на рисунке 2.23. 20-ти разрядов номера страницы достаточно для определения физического адреса начала страницы, так как при ее фиксированном размере 4 К младшие 12 разрядов этого адреса всегда равны нулю. Дескриптор страницы также содержит следующие поля, близкие по смыслу соответствующим полям дескриптора сегмента:
Сегментное распределение
При страничной организации виртуальное адресное пространство процесса делится механически на равные части. Это не позволяет дифференцировать способы доступа к разным частям программы (сегментам), а это свойство часто бывает очень полезным. Например, можно запретить обращаться с операциями записи и чтения в кодовый сегмент программы, а для сегмента данных разрешить только чтение. Кроме того, разбиение программы на "осмысленные" части делает принципиально возможным разделение одного сегмента несколькими процессами. Например, если два процесса используют одну и ту же математическую подпрограмму, то в оперативную память может быть загружена только одна копия этой подпрограммы.
Рассмотрим, каким образом сегментное распределение памяти реализует эти возможности (рисунок 2.14). Виртуальное адресное пространство процесса делится на сегменты, размер которых определяется программистом с учетом смыслового значения содержащейся в них информации. Отдельный сегмент может представлять собой подпрограмму, массив данных и т.п. Иногда сегментация программы выполняется по умолчанию компилятором.
При загрузке процесса часть сегментов помещается в оперативную память (при этом для каждого из этих сегментов операционная система подыскивает подходящий участок свободной памяти), а часть сегментов размещается в дисковой памяти. Сегменты одной программы могут занимать в оперативной памяти несмежные участки. Во время загрузки система создает таблицу сегментов процесса (аналогичную таблице страниц), в которой для каждого сегмента указывается начальный физический адрес сегмента в оперативной памяти, размер сегмента, правила доступа, признак модификации, признак обращения к данному сегменту за последний интервал времени и некоторая другая информация. Если виртуальные адресные пространства нескольких процессов включают один и тот же сегмент, то в таблицах сегментов этих процессов делаются ссылки на один и тот же участок оперативной памяти, в который данный сегмент загружается в единственном экземпляре.

Рис. 2.14. Распределение памяти сегментами
Система с сегментной организацией функционирует аналогично системе со страничной организацией: время от времени происходят прерывания, связанные с отсутствием нужных сегментов в памяти, при необходимости освобождения памяти некоторые сегменты выгружаются, при каждом обращении к оперативной памяти выполняется преобразование виртуального адреса в физический. Кроме того, при обращении к памяти проверяется, разрешен ли доступ требуемого типа к данному сегменту.
Виртуальный адрес при сегментной организации памяти может быть представлен парой (g, s), где g - номер сегмента, а s - смещение в сегменте. Физический адрес получается путем сложения начального физического адреса сегмента, найденного в таблице сегментов по номеру g, и смещения s.
Недостатком данного метода распределения памяти является фрагментация на уровне сегментов и более медленное по сравнению со страничной организацией преобразование адреса.
Селектор TSS возврата
Рис. 2.28. Структура сегмента TSS
Кроме этого, сегмент TSS может включать дополнительную информацию, необходимую для работы задачи и зависящую от конкретной операционной системы (например, указатели открытых файлов или указатели на именованные конвейеры сетевого обмена). Включенная в этот сегмент информация автоматически заменяется процессором при выполнении команды CALL, селектор которой указывает на дескриптор сегмента TSS в таблице GDT (дескрипторы этого типа могут быть расположены только в этой таблице). Формат дескриптора сегмента TSS аналогичен формату дескриптора сегмента данных.
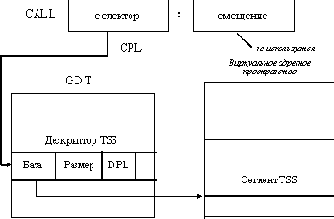
Рис. 2.29. Непосредственный вызов задачи
Как и в случае вызова подпрограмм, имеется две возможности вызова задачи - непосредственный вызов через указание селектора сегмента TSS нужной задачи в поле команды CALL и косвенный вызов через шлюз вызова задачи. Как и при вызове подпрограмм, непосредственный вызов возможен только в случае, если вызывающий код обладает уровнем привилегий, не меньшим, чем вызываемая задача. При вызове через шлюз (который может располагаться и в таблице LDT) достаточно иметь права доступа к шлюзу. Непосредственный вызов задачи показан на рисунке 2.29. При переключении задач процессор выполняет следующие действия:
1) Выполняется команда CALL, селектор которой указывает на дескриптор сегмента типа TSS.
2) В TSS текущей задачи сохраняются значения регистров процессора. На текущий сегмент TSS указывает регистр процессора TR, содержащий селектор сегмента.
3) В TR загружается селектор сегмента TSS задачи, на которую переключается процессор.
4) Из нового TSS в регистр LDTR переносится значение селектора таблицы LDT в таблице GDT задачи.
5) Восстанавливаются значения регистров процессора (из соответствующих полей нового сегмента TSS).
6) В поле селектора возврата заносится селектор сегмента TSS снимаемой с выполнения задачи для организации возврата к прерванной задаче в будущем.
Вызов задачи через шлюз происходит аналогично, добавляется только этап поиска дескриптора сегмента TSS по значению селектора дескриптора шлюза вызова.
Использование всех возможностей, предоставляемых процессорами Intel 80386, 80486 и Pentium, позволяет организовать операционной системе высоконадежную многозадачную среду.
Семантика разделения файлов
Когда два или более пользователей разделяют один файл, необходимо точно определить семантику чтения и записи, чтобы избежать проблем. В централизованных системах, разрешающих разделение файлов, таких как UNIX, обычно определяется, что, когда операция ЧТЕНИЕ следует за операцией ЗАПИСЬ, то читается только что обновленный файл. Аналогично, когда операция чтения следует за двумя операциями записи, то читается файл, измененный последней операцией записи. Тем самым система придерживается абсолютного временного упорядочивания всех операций, и всегда возвращает самое последнее значение. Будем называть эту модель семантикой UNIX'а. В централизованной системе (и даже на мультипроцессоре с разделяемой памятью) ее легко и понять, и реализовать.
Семантика UNIX может быть обеспечена и в распределенных системах, но только, если в ней имеется лишь один файловый сервер, и клиенты не кэшируют файлы. Для этого все операции чтения и записи направляются на файловый сервер, который обрабатывает их строго последовательно. На практике, однако, производительность распределенной системы, в которой все запросы к файлам идут на один сервер, часто становится неудовлетворительной. Эта проблема иногда решается путем разрешения клиентам обрабатывать локальные копии часто используемых файлов в своих личных кэшах. Если клиент сделает локальную копию файла в своем локальном кэше и начнет ее модифицировать, а вскоре после этого другой клиент прочитает этот файл с сервера, то он получит неверную копию файла. Одним из способов устранения этого недостатка является немедленный возврат всех изменений в кэшированном файле на сервер. Такой подход хотя и концептуально прост, но не эффективен.
Другим решением является введение так называемой сессионной семантики, в соответствии с которой изменения в открытом файле сначала виды только процессу, который модифицирует файл, и только после закрытия файла эти изменения могут видеть другие процессы. При использовании сессионной семантики возникает проблема одновременного использования одного и того же файла двумя или более клиентами.
Одним из решений этой проблемы является принятие правила, в соответствии с которым окончательным является тот вариант, который был закрыт последним. Менее эффективным, но гораздо более простым в реализации, является вариант, при котором окончательным результирующим файлом на сервере может оказаться любой из этих файлов.
Следующий подход к разделению файлов заключается в том, чтобы сделать все файлы неизменяемыми. Тогда файл нельзя открыть для записи, а можно выполнять только операции СОЗДАТЬ и ЧИТАТЬ. Тогда для изменения файла остается только возможность создать полностью новый файл и поместить его в каталог под именем старого файла. Следовательно, хотя файл и нельзя модифицировать, его можно заменить (автоматически) новым файлом. Другими словами, хотя файлы и нельзя обновлять, но каталоги обновлять можно. Таким образом, проблема, связанная с одновременным использованием файла, просто исчезнет.
Четвертый способ работы с разделяемыми файлами в распределенных системах - это использование механизма неделимых транзакций, достаточно подробно описанного в разделе 3.3.3.
Итак, было рассмотрено четыре различных подхода к работе с разделяемыми файлами в распределенных системах.
Семантика RPC в случае отказов
В идеале RPC должен функционировать правильно и в случае отказов. Рассмотрим следующие классы отказов:
Клиент не может определить местонахождения сервера, например, в случае отказа нужного сервера, или из-за того, что программа клиента была скомпилирована давно и использовала старую версию интерфейса сервера. В этом случае в ответ на запрос клиента поступает сообщение, содержащее код ошибки.
Потерян запрос от клиента к серверу. Самое простое решение - через определенное время повторить запрос.
Потеряно ответное сообщение от сервера клиенту. Этот вариант сложнее предыдущего, так как некоторые процедуры не являются идемпотентными. Идемпотентной называется процедура, запрос на выполнение которой можно повторить несколько раз, и результат при этом не изменится. Примером такой процедуры может служить чтение файла. Но вот процедура снятия некоторой суммы с банковского счета не является идемпотентной, и в случае потери ответа повторный запрос может существенно изменить состояние счета клиента. Одним из возможных решений является приведение всех процедур к идемпотентному виду. Однако на практике это не всегда удается, поэтому может быть использован другой метод - последовательная нумерация всех запросов клиентским ядром. Ядро сервера запоминает номер самого последнего запроса от каждого из клиентов, и при получении каждого запроса выполняет анализ - является ли этот запрос первичным или повторным.
Сервер потерпел аварию после получения запроса. Здесь также важно свойство идемпотентности, но к сожалению не может быть применен подход с нумерацией запросов. В данном случае имеет значение, когда произошел отказ - до или после выполнения операции. Но клиентское ядро не может распознать эти ситуации, для него известно только то, что время ответа истекло. Существует три подхода к этой проблеме:
Ждать до тех пор, пока сервер не перезагрузится и пытаться выполнить операцию снова. Этот подход гарантирует, что RPC был выполнен до конца по крайней мере один раз, а возможно и более.
Сразу сообщить приложению об ошибке. Этот подход гарантирует, что RPC был выполнен не более одного раза.
Третий подход не гарантирует ничего. Когда сервер отказывает, клиенту не оказывается никакой поддержки. RPC может быть или не выполнен вообще, или выполнен много раз. Во всяком случае этот способ очень легко реализовать.
Ни один из этих подходов не является очень привлекательным. А идеальный вариант, который бы гарантировал ровно одно выполнение RPC, в общем случае не может быть реализован по принципиальным соображениям. Пусть, например, удаленной операцией является печать некоторого текста, которая включает загрузку буфера принтера и установку одного бита в некотором управляющем регистре принтера, в результате которой принтер стартует. Авария сервера может произойти как за микросекунду до, так и за микросекунду после установки управляющего бита. Момент сбоя целиком определяет процедуру восстановления, но клиент о моменте сбоя узнать не может.
Короче говоря, возможность аварии сервера радикально меняет природу RPC и ясно отражает разницу между централизованной и распределенной системой. В первом случае крах сервера ведет к краху клиента, и восстановление невозможно. Во втором случае действия по восстановлению системы выполнить и возможно, и необходимо.
Клиент потерпел аварию после отсылки запроса. В этом случае выполняются вычисления результатов, которых никто не ожидает. Такие вычисления называют "сиротами". Наличие сирот может вызвать различные проблемы: непроизводительные затраты процессорного времени, блокирование ресурсов, подмена ответа на текущий запрос ответом на запрос, который был выдан клиентской машиной еще до перезапуска системы.
Как поступать с сиротами? Рассмотрим 4 возможных решения.
Уничтожение. До того, как клиентский стаб посылает RPC-сообщение, он делает отметку в журнале, оповещая о том, что он будет сейчас делать. Журнал хранится на диске или в другой памяти, устойчивой к сбоям. После аварии система перезагружается, журнал анализируется и сироты ликвидируются.
К недостаткам такого подхода относятся, во-первых, повышенные затраты, связанные с записью о каждом RPC на диск, а, во-вторых, возможная неэффективность из-за появления сирот второго поколения, порожденных RPC-вызовами, выданными сиротами первого поколения.
Перевоплощение. В этом случае все проблемы решаются без использования записи на диск. Метод состоит в делении времени на последовательно пронумерованные периоды. Когда клиент перезагружается, он передает широковещательное сообщение всем машинам о начале нового периода. После приема этого сообщения все удаленные вычисления ликвидируются. Конечно, если сеть сегментированная, то некоторые сироты могут и уцелеть.
Мягкое перевоплощение аналогично предыдущему случаю, за исключением того, что отыскиваются и уничтожаются не все удаленные вычисления, а только вычисления перезагружающегося клиента.
Истечение срока. Каждому запросу отводится стандартный отрезок времени Т, в течение которого он должен быть выполнен. Если запрос не выполняется за отведенное время, то выделяется дополнительный квант. Хотя это и требует дополнительной работы, но если после аварии клиента сервер ждет в течение интервала Т до перезагрузки клиента, то все сироты обязательно уничтожаются.
На практике ни один из этих подходов не желателен, более того, уничтожение сирот может усугубить ситуацию. Например, пусть сирота заблокировал один или более файлов базы данных. Если сирота будет вдруг уничтожен, то эти блокировки останутся, кроме того уничтоженные сироты могут остаться стоять в различных системных очередях, в будущем они могут вызвать выполнение новых процессов и т.п.
Семантика UNIX
. Каждая операция над файлом немедленно становится видимой для всех процессов.
Семейство CORBA
Hewlett-Packard, Sun Microsystems и DEC экспериментируют с объектами уже много лет. Теперь эти компании и много других объединились вместе, основав промышленную коалицию под названием OMG (Object Management Group), разрабатывающую стандарты для обмена объектами. OMG CORBA (Common Object Request Broker Architecture - Общая архитектура посредника обработки объектных запросов) закладывает фундамент распределенных вычислений с переносимыми объектами. CORBA задает способ поиска объектами других объектов и вызова их методов. SOM согласуется с CORBA. Если вы пользуетесь DSOM под OS/2, вы сможете вызывать CORBA-совместимые объекты, работающие на HP, Sun и других архитектурах. Означает ли это возможность редактировать объект OpenDoc, сделанный на Macintosh, в документе-контейнере на RISC-рабочей станции? Вероятно, нет. CORBA может гарантировать только механизм нижнего уровня, посредством которого одни объекты вызывают другие. Для успешного взаимодействия требуется также понимание сообщений друг друга.
Сервер баз данных SQL Server
Этот сервер представляет собой систему управления реляционными базами данных высшего класса, построенную в архитектуре клиент-сервер.
Интегрируемость и открытость
SQL Server достаточно легко интегрируется со всеми существующими на сей день клиентами - настольными компьютерами и системами на базе хостов. В перечень поддерживаемых клиентов входят: Windows 3.1, Windows for Workgroups 3.11, Windows NT Workstation, MS-DOS, OS/2 и Apple Macintosh. Для поддержки клиентов, работающих на UNIX и VMS, можно воспользоваться программным обеспечением Open Client Software компании Sybase. Сетевая поддержка включает Microsoft Windows NT Server, Microsoft LAN Manager, Novell NetWare, сети с протоколами стека TCP/IP, IBM LAN Server, Banyan VINES, DEC PATHWORKS и Apple AppleTalk. Все сети поддерживаются с помощью их родных протоколов.
Конечные пользователи могут получить доступ к данным, хранящимся на сервере, и оперативно составлять отчеты и проводить анализ данных с помощью таких средств, как Microsoft Access и Microsoft Excel.
Для перехода от баз данных других форматов к SQL Server компания Microsoft разработала ряд полезных утилит миграции: Access Upsizing Tool для перехода от архитектуры приложений модели файл-сервер, Transfer Manager для переноса данных из баз данных Sybase или SQL Server, работающих в среде UNIX или OS/2, на платформу Windows NT.
Компания Microsoft предусмотрела также ряд средств для того, чтобы предлагаемое ей решение было открытым. Среди них технология ODBC, интерфейс DB-Library, шлюз ODS и язык ANSI SQL.
Технология ODBC (Open Database Connectivity) - это открытый и независимый от производителя прикладной программный интерфейс (API) между клиентами и сервером. Технологию ODBC поддерживают свыше 130 независимых производителей приложений, драйверов и сервисов баз данных, среди которых IBM, Lotus Development Corporation, Novell и Word Perfect.
DB-Library - это родной интерфейс для Microsoft SQL Server, который поддерживается большим количеством коммерческих утилит и приложений.
SQL Server также поддерживает и интерфейс Open Client компании Sybase.
ODS (Open Data Services) - это API для разработки шлюзов, работающих на базе сервера Windows NT, для предоставления клиентам доступа к любым источникам информации.
Transact-SQL - язык, который разработан специально для Microsoft SQL Server. Эта реализация SQL полностью совместима со стандартом SQL 1989 и дополнена возможностями для создания таких компонент базы данных, как триггеры, правила, хранимые процедуры, и некоторых других.
Разработка приложений
Для быстрой разработки пользовательских приложений можно воспользоваться одним из настольных приложений компании Microsoft : настольной СУБД Microsoft Access, электронной таблицей Microsoft Excel, настольной СУБД Microsoft FoxPro, обладающей более высоким быстродействием по сравнению с Microsoft Access, системой программирования Microsoft Visual Basic, которая сочетает простоту, графические средства проектирования приложений и доступ к данным с помощью встроенных средств ODBC, или системой программирования Microsoft Visual C++ с графической средой программирования.
Кроме этого, для реализации логики работы приложения можно воспользоваться средствами, которые работают в серверной части приложения, то есть средствами системы SQL Server: проекциями (views), хранимыми процедурами и триггерами.
Надежность системы SQL Server определяется надежностью операционной системы Windows NT, а также собственными средствами - механизмом транзакций, системой автоматического восстановления после сбоев и отказов, компонентами целостности данных (правилами, хранимыми процедурами и триггерами).
Производительность и масштабируемость обеспечиваются за счет полного использования широких возможностей в этих аспектах сервера Windows NT Server. SQL Server использует средства создания и диспетчирования нитей, управления их приоритетами, средства безопасности, управления событиями и их мониторинга Windows NT, исключая тем самым ненужное дублирование кода в операционной системе и СУБД.
SQL Server не создает для каждого пользователя отдельного процесса, а работает как единый процесс, создающий для каждого пользовательского соединения отдельную нить. На SMP платформах каждая нить назначается на свободный или малозагруженный центральный процессор, обеспечивая динамическую балансировку загрузки.
Масштабируемость достигается за счет того, что сама операционная система Windows NT изначально разрабатывалась как переносимая система, способная работать на широком ряде аппаратных платформ - от простых однопроцессорных Intel-серверов до мощных многопроцессорных серверов на RISC-процессорах Alpha или MIPS.
Администрирование SQL Server обеспечивается за счет поставляемых утилит с графическим интерфейсом, предназначенных для работы под управлением Windows 3.1, Windows for Workgroups 3.11 или Windows NT. Эти утилиты поставляются в 32-х битном и 16-ти битном вариантах. С помощью утилит администрирования можно управлять несколькими SQL серверами в сети. SQL Server поддерживает опцию интегрированной безопасности, которая обеспечивает один логический вход как в сеть, так и в сервер баз данных. При этом доступ к SQL серверу управляется привилегиями, которые устанавливаются для пользователей и групп пользователей в Windows NT. Специальная компонента, называемая SQL Monitor, позволяет составить и отработать расписание автоматического копирования данных из базы на устройства резервного копирования, такие как стриммеры.
Перспективы развития компания Microsoft связывает с версией SQL Server 6.0. Эта версия предназначена для крупных распределенных корпоративных систем и отличается следующими особенностями:
Распределенные данные и приложения будут поддерживаться за счет встроенной системы репликации с удобными графическими средствами управления.
Трехуровневая архитектура администрирования, основанная на технологии OLE, будет обеспечивать централизованное администрирование распределенными серверами.
Объектная ориентация на основе технологии OLE предназначена для превращения SQL сервера из пассивного внешнего источника данных в активного участника пользовательских приложений.SQL Server 6.0 будет поддерживать богатый интерфейс OLE Automation для связей с настольными приложениями с помощью языка Visual Basic for Applications и интерфейса MAPI. Например, используя OLE, он может отослать пользователям результаты запроса по почте как встроенные объекты электронной таблицы Microsoft Excel.
Повышение производительности до 20 Гбайт в час за счет новой методики параллельного архивирования и технологии компрессирования данных.
Сервер Mach BSD UNIX
Как уже было сказано выше, разработчики системы Mach модифицировали Berkeley UNIX для работы в пользовательском пространстве в форме прикладной программы. Такая структура имеет несколько преимуществ по сравнению с монолитным ядром. Во-первых, система упрощается за счет разделения на часть, которая выполняет управление ресурсами (ядро), и часть, которая обрабатывает системные вызовы (UNIX-сервер), и ею становится легче управлять. Такое разделение напоминает разделение труда в операционной системе VM/370 мейнфреймов IBM, где ядро эмулирует набор "голых" 370-х машин, на каждой из которых реализована однопользовательская операционная система.
Во-вторых, за счет помещения UNIX'а в пользовательское пространство его можно сделать в высокой степени машинно-независимым. Все машинно-зависимые части могут быть удалены из UNIX'а и скрыты внутри ядра Mach.
В-третьих, как уже было упомянуто выше, несколько ОС могут работать одновременно. Например, на процессоре Intel 386 Mach может выполнять программу UNIX и программу MS-DOS одновременно. Аналогично возможно одновременное тестирование новой экспериментальной ОС и работа с основной ОС.
В-четвертых, в систему могут быть введены операции реального времени, потому что все традиционные препятствия для работы в реальном времени, такие как, например, запрет прерываний на время обновления критических таблиц, могут быть либо исключены, либо перенесены в пользовательское пространство. Ядро может быть тщательно структурировано, для того чтобы не препятствовать работе приложений реального времени. Наконец, такое построение системы может быть использовано для обеспечения лучшей защиты между процессами, если она нужна. Если каждый процесс работает со своей версией UNIX'а, то для одного процесса очень трудно что-либо разузнать о файлах другого процесса.
Сервер сетевых сообщений
Все коммуникационные механизмы Mach, которые до сих пор были рассмотрены, относились к случаю отдельной машины. Коммуникациями по сети управляют серверы пользовательского режима, называемые серверами сетевых сообщений, аналогами которых являются внешние менеджеры памяти, которые уже были рассмотрены. Каждая машина в распределенной системе Mach имеет сервер сетевых сообщений. Эти серверы работают вместе, обрабатывая межмашинные сообщения.
Сервер сетевых сообщений (Network Message Server) - это многонитевый процесс, который реализует многие функции. Они включают взаимодействие с локальными нитями, передачу сообщений через сеть, трансляцию типов данных из представления одной машины в представление другой машины, управление права доступа защищенным образом, удаленное уведомление, поддержку простого сервиса поиска сетевых имен, аутентификацию других сетевых серверов. Серверы сетевых сообщений должны поддерживать различные сетевые протоколы, в зависимости от сетей, к которым они присоединены.
Основной метод, с помощью которого сообщения пересылаются через сеть, иллюстрируется рисунком 6.14. На нем изображена машина-клиент А и машина-сервер В. Прежде, чем клиент сможет взаимодействовать с сервером, на машине А должен быть создан порт, чтобы работать как передаточное звено для сервера. Сервер сетевых сообщений имеет право ПОЛУЧИТЬ для этого порта. Нить сервера всегда прослушивает этот порт (и другие удаленные порты, которые вместе образуют набор портов). Этот порт показан как небольшой квадрат внутри ядра машины А.
Передача сообщения от клиента серверу требует пяти шагов, пронумерованных на рисунке 6.14 от 1 до 5. Во-первых, клиент посылает сообщение порту-посреднику сервера сетевых сообщений своей машины. Во-вторых, сервер сетевых сообщений получает это сообщение. Так как это сообщение сугубо локальное, то с помощью него могут быть посланы внешние данные или данные режима копирование-при-записи. В-третьих, сервер сетевых сообщений ищет локальный порт, в нашем примере 4, в таблице, которая отображает порты-посредники на сетевые порты.
Когда сетевой порт становится известен, сервер сетевых сообщений начинает искать его в других таблицах. Затем он конструирует сетевое сообщение, содержащее локальное сообщение плюс любые внешние данные, и посылает его по локальной сети серверу сетевых сообщений на машине-сервере. В некоторых случаях трафик между серверами сетевых сообщений должен быть зашифрован для защиты информации. Ответственность за разбивку сообщения на пакеты и инкапсуляцию их в формат соответствующего протокола несет транспортный модуль.

Рис. 6.14. Межмашинное взаимодействие в Mach выполняется за пять шагов
Когда сервер сообщений удаленной сети получает сообщение, он берет из него номер сетевого порта и отображает его на номер локального порта. На шаге 4 сервер записывает сообщение в этот локальный порт. Наконец, локальный сервер машины В читает сообщение из локального порта и выполняет запрос клиента машины А. Ответ проходит по этому же пути в обратном направлении.
Сложное сообщение требует небольшой дополнительной работы. Для обычных полей данных сервер сетевых сообщений на машине-сервере выполняет преобразование форматов данных, если это необходимо (например, изменяет порядок байт в слове). Обработка прав доступа при пересылке через сети также усложняется. Когда мандат пересылается через сеть, должен быть назначен номер сетевого порта, и оба сервера сетевых сообщений, отправитель и получатель, должны сделать соответствующие записи в своих таблицах отображения. Если эти машины не доверяют друг другу, необходимы тщательно разработанные процедуры аутентификации, чтобы каждая из машин убедилась в идентичности другой.
Хотя механизм передачи сообщений от одной машины к другой через сервер пользовательского режима обладает гибкостью, за это платится высокая цена, выражающаяся в снижении производительности по сравнению с реализацией межмашинного взаимодействия полностью внутри ядра, как это делается в большинстве других распределенных систем.
Сессионная семантика
. Изменения не видны до тех пор, пока файл не закрывается.
Сетевая файловая система NFS
Одной из самых известных сетевых файловых систем является Network File System (NFS) фирмы Sun Microsystems. NFS была первоначально создана для UNIX-компьютеров. Сейчас она поддерживает как UNIX, так и другие ОС, включая MS DOS. NFS поддерживает неоднородные системы, например, MS-DOS-клиенты и UNIX-серверы.
Основная идея NFS - позволить произвольному набору пользователей разделять общую файловую систему. Чаще всего все пользователи принадлежат одной локальной сети, но не обязательно. Можно выполнять NFS и на глобальной сети. Каждый NFS-сервер предоставляет один или более своих каталогов для доступа удаленным клиентам. Каталог объявляется доступным со всеми своими подкаталогами. Список каталогов, которые сервер передает, содержится в файле /etc/exports, так что эти каталоги экспортируются сразу автоматически при загрузке сервера. Клиенты получают доступ к экспортируемым каталогам путем монтирования. Многие рабочие станции Sun - бездисковые, но и в этом случае можно монтировать удаленную файловую систему на корневой каталог, при этом вся файловая система целиком располагается на сервере. При выполнении программ почти нет различий, расположен ли файл локально или на удаленном диске. Если два или более клиента одновременно смонтировали один и тот же каталог, то они могут связываться путем разделения файла.
Так как одной из целей NFS является поддержка неоднородных систем с клиентами и серверами, выполняющими различные ОС на различной аппаратуре, то особенно важно, чтобы был хорошо определен интерфейс между клиентами и серверами. Только в этом случае станет возможным написание программного обеспечения клиентской части для новых операционных систем рабочих станций, которое будет правильно работать с существующими серверами. Это цель достигается двумя протоколами.
Первый NFS-протокол управляет монтированием. Клиент может послать полное имя каталога серверу и запросить разрешение на монтирование этого каталога на какое-либо место собственного дерева каталогов. При этом серверу не указывается, в какое место будет монтироваться каталог сервера, так как ему это безразлично.
Получив имя, сервер проверяет законность этого запроса и возвращает клиенту описатель файла, содержащий тип файловой системы, диск, номер дескриптора (inode) каталога, информацию безопасности. Операции чтения и записи файлов из монтируемых файловых систем используют этот описатель файла. Монтирование может выполняться автоматически с помощью командных файлов при загрузке. Существует другой вариант автоматического монтирования: при загрузке ОС на рабочей станции удаленная файловая система не монтируется, но при первом открытии удаленного файла ОС посылает запросы каждому серверу, и, после обнаружения этого файла, монтирует каталог того сервера, на котором этот файл расположен.
Второй NFS-протокол используется для доступа к удаленным файлам и каталогам. Клиенты могут послать запрос серверу для выполнения какого-либо действия над каталогом или операции чтения или записи файла. Кроме того, они могут запросить атрибуты файла, такие как тип, размер, время создания и модификации. Большая часть системных вызовов UNIX поддерживается NFS, за исключением open и close. Исключение open и close не случайно. Вместо операции открытия удаленного файла клиент посылает серверу сообщение, содержащее имя файла, с запросом отыскать его (lookup) и вернуть описатель файла. В отличие от вызова open, вызов lookup не копирует никакую информацию во внутренние системные таблицы сервера. Вызов read содержит описатель того файла, который нужно читать, смещение в уже читаемом файле и количество байтов, которые нужно прочитать. Преимуществом такой схемы является то, что сервер не должен запоминать ничего об открытых файлах. Таким образом, если сервер откажет, а затем будет восстановлен, информация об открытых файлах не потеряется, потому что ее нет. Серверы, подобные этому, не хранящие постоянную информацию об открытых файлах, называются stateless.
В противоположность этому в UNIX System V в удаленной файловой системе RFS требуется, чтобы файл был открыт, прежде чем его можно будет прочитать или записать.
После этого сервер создает таблицу, сохраняющую информацию о том, что файл открыт, и о текущем читателе. Недостаток этого подхода состоит в том, что когда сервер отказывает, после его перезапуска все его открытые связи теряются, и программы пользователей портятся. В NFS такого недостатка нет.
К сожалению метод NFS затрудняет блокировку файлов. В UNIX файл может быть открыт и заблокирован так, что другие процессы не имеют к нему доступа. Когда файл закрывается, блокировка снимается. В stateless-системах, подобных NFS, блокирование не может быть связано с открытием файла, так как сервер не знает, какой файл открыт. Следовательно, NFS требует специальных дополнительных средств управления блокированием.
Реализация кодов клиента и сервера в NFS имеет многоуровневую структуру (рисунок 5.10).
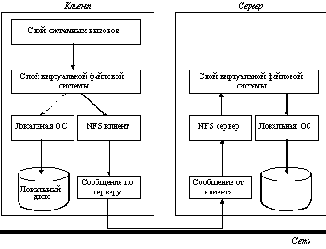
Рис. 5.10. Многоуровневая структура NFS
Верхний уровень клиента - уровень системных вызовов, таких как OPEN, READ, CLOSE. После грамматического разбора вызова и проверки параметров, этот уровень обращается ко второму уровню - уровню виртуальной файловой системы (VFS). В структуре vnode имеется информация о том, является ли файл удаленным или локальным. Чтобы понять, как используются vnode, рассмотрим последовательность выполнения системных вызовов MOUNT, READ, OPEN. Чтобы смонтировать удаленную файловую систему, системный администратор вызывает программу монтирования, указывая удаленный каталог, локальный каталог, на который должен монтироваться удаленный каталог, и другую информацию. Программа монтирования выполняет грамматический разбор имени удаленного каталога и определяет имя машины, где находится удаленный каталог. Если каталог существует и является доступным для удаленного монтирования, то сервер возвращает описатель каталога программе монтирования, которая путем выполнения системного вызова MOUNT передает этот описатель в ядро.
Затем ядро создает vnode для удаленного каталога и обращается с запросом к клиент-программе для создания rnode (удаленного inode) в ее внутренних таблицах.Каждый vnode указывает либо на какой-нибудь rnode в NFS клиент-коде, либо на inode в локальной ОС.
Сетевой пакет DCE фирмы OSF
Распределенные вычисления имеют дело с понятиями более высокого уровня, чем физические носители, каналы связи и методы передачи по ним сообщений. Распределенная среда должна дать пользователям и приложениям прозрачный доступ к данным, вычислениям и другим ресурсам в гетерогенных системах, представляющих собой набор средств различных производителей. Стратегические архитектуры каждого крупного системного производителя базируются сейчас на той или иной форме распределенной вычислительной среды (DCE). Ключом к пониманию выгоды такой архитектуры является прозрачность. Пользователи не должны тратить свое время на попытки выяснить, где находится тот или иной ресурс, а разработчики не должны писать коды для своих приложений, использующие местоположение в сети. Никто не заинтересован в том, чтобы заставлять разработчиков приложений становиться гуру коммуникаций, или же в том, чтобы заставлять пользователей заботиться о монтировании удаленных томов. Кроме того, сеть должна быть управляемой. Окончательной картиной является виртуальная сеть: набор сетей рабочих групп, отделов, предприятий, объединенных сетей предприятий, которые кажутся конечному пользователю или приложению единой сетью с простым доступом.
Одной из технологий, которая будет играть большое значение для будущего распределенных вычислений является технология DCE (Distributed Computing Environment) некоммерческой организации Open Software foundation (OSF). DCE OSF - это интегрированный набор функций, независимых от операционной системы и сетевых средств, которые обеспечивают разработку, использование и управление распределенными приложениями. Из-за их способности обеспечивать управляемую, прозрачную и взаимосвязанную работу систем различных производителей и различных платформ, DCE является одной из самых важных технологий десятилетия.
Большинство из ведущих фирм-производителей ОС договорились о поставках DCE в будущих версиях своих системных и сетевых продуктов. Например, IBM, которая предлагает несколько DCE-продуктов, базирующихся на AIX, распространила их и на сектор сетей персональных компьютеров.
В сентябре 1993 года IBM начала поставлять инструментальные средства для разработки DCE-приложений - DCE SDK для OS/2 и Windows, и в это же время выпустила на рынок свой первый DCE-продукт для пользователей персональных компьютеров - DCE Client for OS/2. Компания IBM достаточно далеко продвинулась в реализации спецификации DCE в своих продуктах, обогнав Microsoft, Novell и Banyan. Сейчас она продает как отдельный продукт клиентскую часть служб DCE для операционных сред MVS, OS/400, OS/2, AIX и Windows. IBM собирается реализовать отсутствующую в LAN Server единую справочную службу и новую службу безопасности в соответствии со спецификацией DCE и выпустить интегрированный вариант DCE/LAN Server в конце этого года.

Рис. 4.4. Архитектура средств OSF DCE
Некоторые крупные фирмы-потребители программных продуктов обращаются непосредственно в OSF за лицензиями на первые версии DCE OSF.
В настоящее время DCE состоит из 7 средств и функций, которые делятся на базовые распределенные функции и средства разделения данных. Базовые распределенные функции включают:
нити,
RPC,
службу каталогов,
службу времени,
службу безопасности.
Функции разделения данных строятся над базовыми функциями и включают:
распределенную файловую систему (DFS),
поддержку бездисковых машин.
На рисунке 4.4 показана архитектура DCE OSF. Эта архитектура представляет собой многоуровневый набор интегрированных средств. Внизу расположены базисные службы, такие как ОС, а на самом верхнем уровне находятся потребители средств DCE приложения. Средства безопасности и управления пронизывают все уровни. OSF резервирует место для функций, которые могут появиться в будущем, таких как спулинг, поддержка транзакций и распределенная объектно-ориентированная среда.
Сетевые продукты Microsoft
В 1984 году Microsoft выпустила свой первый сетевой продукт, называемый Microsoft Networks, который обычно неформально называют MS-NET. Некоторые концепции, заложенные в MS-NET, такие как введение в структуру базовых компонент - редиректора и сетевого сервера - успешно перешли в LAN Manager, а затем и в Windows NT.
Microsoft все еще поставляет свою сетевую ОС LAN Manager. Большое количество независимых поставщиков имеют лицензии на эту ОС и поддерживают свои собственные версии LAN Manager как часть своих сетевых продуктов. В число этих компаний входят такие известные фирмы как AT&T и Hewlett-Packard. LAN Manager требует установки на файл-сервере операционной системы OS/2, рабочие станции могут работать под DOS, Windows или OS/2. OS/2 - это операционная система, реализующая истинную многозадачность, работающая в защищенном режиме микропроцессоров x86 и выше. LAN Manager использует 32-х битную версию файловой системы OS/2, называемую HPFS, которая оптимизирована для работы на файл-сервере за счет кэширования каталогов и данных. LAN Manager - это первая сетевая ОС, разработанная для поддержки среды клиент-сервер. Ключевыми компонентами LAN Manager являются редиректор и сервер. Особенно эффективно LAN Manager поддерживает архитектуру клиент-сервер для систем управления базами данных. LAN Manager разрешает рабочим станциям под OS/2 поддерживать сетевой сервис по технологии "равный-с-равным". Это означает, что рабочая станция может выполнять функции сервера баз данных, принт-сервера или коммуникационного сервера. Ограничением является то, что только один пользователь, кроме владельца этой рабочей станции, имеет доступ к такому одноранговому сервису.
Для работы в небольшой сети фирма Microsoft предлагает компактную, не требующую значительных аппаратных или программных затрат операционную систему Windows for Workgroups. Эта операционная система позволяет организовать сеть по схеме "равный-с-равным", при этом нет необходимости приобретать специальный компьютер для работы в качестве сетевого сервера. Эта операционная система особенно подходит для решения сетевых задач в коллективах, члены которого ранее широко использовали Windows 3.1. В Windows for Workgroups достигнута высокая производительность сетевой обработки за счет того, что все сетевые драйверы являются 32-х разрядными виртуальными драйверами.
С середины 1993 года Microsoft начала выпуск новых операционных систем "новой технологии" (New Technology - NT) Windows NT.
В сентябре 1995 года компания Microsoft выпустила еще одну новую операционную систему Windows 95 (кодовое название Chicago), предназначенную для замены Windows 3.1 и Windows for Workgroups 3.11 в настольных компьютерах с процессорами Intel x86.
Сетевые средства
Средства сетевого взаимодействия Windows NT направлены на реализацию взаимодействия с существующими типами сетей, обеспечение возможности загрузки и выгрузки сетевого программного обеспечения, а также на поддержку распределенных приложений.
Windows NT с точки зрения реализации сетевых средств имеет следующие особенности:
Встроенность на уровне драйверов. Это свойство обеспечивает быстродействие.
Открытость - обуславливается легкостью динамической загрузки-выгрузки, мультиплексируемостью протоколов.
Наличие RPC, именованных конвейеров и почтовых ящиков для поддержки распределенных приложений .
Наличие дополнительных сетевых средств, позволяющих строить сети в масштабах корпорации: дополнительные средства безопасности централизованное администрирование отказоустойчивость (UPS, зеркальные диски).
Windows NT унаследовала от своих предшественников редиректор и сервер, протокол верхнего уровня SMB и транспортный протокол NetBIOS (правда, с новым "наполнением" - NetBEUI). Как и в сети MS-NET редиректор перенаправляет локальные запросы ввода-вывода на удаленный сервер, а сервер принимает и обрабатывает эти запросы.
Сначала редиректор и сервер были написаны на ассемблере и располагались над существующим системным программным обеспечением MS-DOS. Новые редиректор и сервер встроены в Windows NT, они не зависят от архитектуры аппаратных средств, на которых работает ОС. Они написаны на С и выполнены как загружаемые драйверы файловой системы, которые могут загружаться или выгружаться в любое время. Они также могут сосуществовать с редиректорами и серверами других производителей.
Реализация редиректора и сервера как драйверов файловой системы делают их частью NT executive. Следовательно, они имеют доступ к специализированным интерфейсам, которые менеджер ввода-вывода обеспечивает для драйверов. Эти интерфейсы, в свою очередь, были разработаны с учетом нужд сетевых компонент. Доступ к интерфейсам драйверов плюс возможности непосредственного вызова кэш-менеджера дают значительный вклад в повышение производительности редиректора и сервера.
Многоуровневая модель драйверов менеджера ввода- вывода отражает многоуровневую модель сетевых протоколов. Так как редиректор и сервер являются драйверами, то они могут быть размещены на верхнем уровне, под которым располагаются все необходимые драйверы транспортных протоколов. Такая структура обеспечивает модульность сетевых компонент и создает эффективный путь от уровня редиректора или сервера вниз к транспортному и физическому уровням сети.
Сетевой редиректор обеспечивает средства, необходимые одному компьютеру Windows NT для доступа к файлам и принтерам другого компьютера. Так как он поддерживает SMB-протокол, то он работает с существующими серверами MS-NET и LAN Manager, обеспечивая доступ к системам MS-DOS, Windows и OS/2 из Windows NT. Механизмы безопасности обеспечивают защиту данных Windows NT, разделяемых по сети, от несанкционированного доступа.
Редиректор имеет одну основную задачу: поддержку распределенной файловой системы, которая ведет себя подобно локальной файловой системе, хотя и работает через ненадежную среду (сеть). Когда связь отказывает, редиректор ответственен за восстановление соединения, если это возможно, или же за возврат кода ошибки, чтобы приложение смогло повторить операцию.
Подобно другим драйверам файловой системы, редиректор должен поддерживать асинхронные операции ввода-вывода, если они вызываются. Когда пользовательский запрос является асинхронным, то редиректор должен вернуть управление немедленно, независимо от того, завершилась ли удаленная операция ввода-вывода или нет. При этом редиректор выполняется в контексте этой нити. Вызывающая нить должна продолжить свою работу, а редиректор должен ждать завершения запущенной операции. Есть два варианта решения этой проблемы: или редиректор сам создает новую нить, которая будет ждать, или он может передать эту работу уже готовой нити, существующей в системе. В Windows NT реализован второй вариант.
Редиректор отправляет и получает блоки SMB для выполнения своей работы. Протокол SMB является протоколом прикладного уровня, включающим сетевой уровень и уровень представления.
SMB реализует:
установление сессии,
файловый сервис,
сервис печати,
сервис сообщений.
Интерфейс, в соответствии с которым редиректор посылает блоки SMB, называется интерфейсом транспортных драйверов (transport driver interface - TDI). Редиректор вызывает функции TDI для передачи блоков SMB различным транспортным драйверам, загруженным в Windows NT. Для вызова функций TDI редиректор должен открыть канал, называемый виртуальной связью (virtual circuit), к машине назначения, а затем послать SMB-сообщение через эту виртуальную связь. Редиректор создает только одну виртуальную связь для каждого сервера, с которым соединена система Windows NT, и мультиплексирует через нее запросы к этому серверу. Транспортный уровень определяет, каким образом реализовать виртуальную связь, и пересылает данные через сеть.
Как и редиректор, сервер Windows NT на 100% совместим с существующими SMB-протоколами MS-NET и LAN Manager. Эта полная совместимость позволяет серверу обрабатывать запросы, исходящие не только от систем Windows NT, но и от других систем, работающих с программным обеспечением LAN Manager. Как и редиректор, сервер выполнен в виде драйвера файловой системы.
Может показаться странным, что сервер в соответствии с микроядерной концепцией не реализован как серверный процесс. Было бы логично ожидать, что сетевой сервер будет функционировать как защищенная подсистема - процесс, чьи нити ожидают поступления запросов по сети, выполняют их, а затем возвращают результаты по сети. Этот подход, как наиболее естественный, был тщательно рассмотрен при проектировании Windows NT, однако, учитывая опыт построения сетей VAX/VMS и опыт использования RPC, было решено выполнить сервер как драйвер файловой системы. Хотя сервер и не является драйвером в обычном смысле, и он не управляет файловой системой на самом деле, использование модели драйвера обеспечивает некоторые преимущества.
Главное из них состоит в том, что драйвер реализован в среде NT executive и может вызывать кэш-менеджер NT непосредственно, что оптимизирует передачу данных.
Например, когда сервер получает запрос на чтение большого количества данных, он вызывает кэш-менеджер для определения места расположения этих данных в кэше (или для загрузки этих данных в кэш, если их там нет) и для фиксации данных в памяти. Затем сервер передает данные непосредственно из кэша в сеть, минуя доступ к диску. Аналогично, при запросе на запись данных сервер вызывает кэш-менеджер для резервирования места для поступающих данных. Затем сервер пишет данные непосредственно в кэш. Записывая данные в кэш, сервер возвращает управление клиенту гораздо быстрее; затем кэш-менеджер записывает данные на диск в фоновом режиме (используя страничные средства менеджера виртуальной памяти).
Будучи драйвером файловой системы, сервер несколько более гибок по сравнению с его реализацией в виде процесса. Например, он может регистрировать функции завершения ввода-вывода, что позволяет ему получать управление немедленно после завершения работы драйверов нижнего уровня. Хотя сервер Windows NT реализован как драйвер файловой системы, другие серверы могут быть реализованы и как драйверы, и как серверные процессы.
Асинхронные вызовы обрабатываются сервером аналогично, с использованием пула рабочих нитей.
И редиректоры, и серверы, и транспортные драйверы могут быть в любое время загружены и выгружены.
Открытая архитектура сетевых средств Windows NT обеспечивает работу своих рабочих станций (и серверов) в гетерогенных сетях не только путем предоставления возможности динамически загружать и выгружать сетевые средства, но и путем непосредственного переключения с программных сетевых средств, ориентированных на взаимодействие с одним типом сетей, на программные средства для другого типа сетей в ходе работы системы. Windows NT поддерживает переключение программных средств на трех уровнях:
на уровне редиректоров - каждый редиректор предназначен для своего протокола (SMP, NCP, NFS, VINES);
на уровне драйверов транспортных протоколов, предоставляя для них и для редиректоров стандартный интерфейс TDI;
на уровне драйверов сетевых адаптеров - со стандартным интерфейсом NDIS 3.0.
Для доступа к другим типам сетей в Windows NT, помимо встроенного, могут загружаться дополнительные редиректоры. Специальные компоненты Windows NT решают, какой редиректор должен быть вызван для обслуживания запроса на удаленный ввод-вывод. За последние десятилетия получили распространение различные протоколы передачи информации по сети. И хотя Windows NT поддерживает не все эти протоколы, она, по крайней мере, разрешает включать их поддержку.
После того, как сетевой запрос достигает редиректора, он должен быть передан в сеть. В традиционной системе каждый редиректор жестко связан с определенным транспортным протоколом. В Windows NT поставлена задача гибкого подключения того или иного транспортного протокола, в зависимости от типа транспорта, используемого в другой сети. Для этого во всех редиректорах нижний уровень должен быть написан в соответствии с определенными соглашениями, которые и определяют единый программный интерфейс, называемый интерфейсом транспортных драйверов (TDI).
TDI позволяет редиректорам оставаться независимым от транспорта. Таким образом, одна версия редиректора может пользоваться любым транспортным механизмом. TDI обеспечивает набор функций, которые редиректоры могут использовать для пересылки любых типов данных с помощью транспортного уровня. TDI поддерживает как связи с установлением соединения (виртуальные связи), так и связи без установления соединения (датаграммные связи). Хотя LAN Manager использует связи с установлением соединений, Novell IPX является примером сети, которая использует связь без установления соединения. Microsoft изначально обеспечивает транспорты - NetBEUI (NetBIOS Extended User Interface), TCP/IP, IPX/SPX, DECnet и AppleTalk.
Сетевые адаптеры поставляются вместе с сетевыми драйверами, которые раньше часто были рассчитаны на взаимодействие с определенным типом транспортного протокола. Так как Windows NT позволяет загружать драйверы различных транспортных протоколов, то производители сетевых адаптеров, использующие такой подход, должны были писать различные варианты одного и того же драйвера, рассчитанные на связь с разными протоколами транспортного уровня.
Чтобы помочь производителям избежать этого, Windows NT обеспечивает интерфейс и программную среду, называемые "спецификация интерфейса сетевого драйвера" (NDIS), которые экранируют сетевые драйверы от деталей различных транспортных протоколов. Самый верхний уровень драйвера сетевого адаптера должен быть написан в соответствии с рекомендациями NDIS. В этом случае пользователь может работать с сетью TCP/IP и сетью NetBEUI (или DECnet, NetWare, VINES и т.п.), используя один сетевой адаптер и один сетевой драйвер. Среда NDIS использовалась в сетях LAN Manager, но для Windows NT она была обновлена.
Через свою нижнюю границу драйвер сетевого адаптера обычно взаимодействует непосредственно с адаптером или адаптерами, которые он обслуживает. Драйвер сетевого адаптера, реализованный для среды NDIS, управляет адаптером не непосредственно, а использует для этого функции, предоставляемые NDIS (например, для запуска ввода-вывода или обработки прерываний). Таким образом, среда NDIS образует некую оболочку, которая позволяет достаточно просто переносить драйверы сетевых адаптеров из одной ОС в другую. NDIS позволяет сетевым драйверам не содержать встроенных знаний о процессоре или операционной системе, на которых он работает.
Сетевые возможности
Система имеет средства поддержки протокола TCP/IP в составе пакета многопротокольной транспортной службы, что упрощает работу со стеками протоколов. Эта новая версия протоколов TCP/IP обеспечивает хорошую производительность. В отличие от Windows NT Server, LAN Server не содержит программы динамической конфигурации хоста DHCP, но ее появление планируется в будущих версиях. Для доступа к Internet LAN Server использует утилиты, входящие в состав Warp 3.0. Сама по себе OS/2 Warp позволяет подключаться к Internet только по модему, но LAN Server активно участвует в работе этих утилит, делая их доступными и по локальной сети.
SFT NetWare
, в которой были предусмотрены специальные средства обеспечения надежности системы и расширены возможности управления сетью. Такие средства, как учет используемых ресурсов и защита от несанкционированного доступа, позволили администраторам сети определять, когда и как пользователи осуществляют доступ к информации и ресурсам сети. Разработчики впервые получили возможность создавать многопользовательские прикладные программы, которые могут выполняться на сервере в качестве дополнительных процессов сетевой операционной системы и использовать ее функциональные возможности.
Операционная система
Шлюз SNA Server
В традиционной среде мейнфреймов вся обработка данных осуществляется на хост-машинах, причем мейнфреймы IBM традиционно считаются надежными средствами централизованного управления и администрирования такого рода обработки. Однако терминалы для доступа к мейнфреймам обычно не имеют средств пользовательского графического интерфейса, что усложняет работу пользователей, а также не могут производить обработку данных, как это делают персональные компьютеры. Кроме того, мейнфреймам недостает средств, необходимых для быстрой разработки приложений.
С другой стороны, настольные приложения, такие как Microsoft Access и Microsoft Excel, обеспечивают простоту использования данных, но не обладают достаточной мощностью для поддержки ответственных корпоративных данных. Чтобы получить преимущества от использования всех корпоративных данных, необходимо объединить данные, используемые в настольных компьютерах, с данными, хранящимися на серверах сетей и на мейнфреймах. Для западных пользователей эта проблема особенно актуальна, так как там около 80% всех компьютерных данных хранятся на мейнфреймах и других хостах.
Одним из средств объединения локальных сетей с мейнфреймами является Microsoft SNA Server for Windows NT, который обеспечивает для пользователей локальных сетей доступ к мейнфреймам и мини-компьютерам фирмы IBM.
По сравнению с прямым подключением персональных компьютеров к мейнфрейму, использование шлюза SNA Server экономит производительность как мейнфрейма, так и персоналок, обеспечивает централизованное управление взаимодействием, защищает корпоративные данные на уровне безопасности С2, обеспечивает высокую готовность доступа к мейнфрейму за счет средств отказоустойчивости и архивирования данных.
SNA Server обеспечивает:
Соединение со всеми популярными мейнфреймами архитектуры SNA (например, 3090 или ES/9000) и SNA-мини-компьютеров (семейства AS/400).
Использование всех типов SNA-каналов: SDLC, X.25, 802.2.
Взаимодействие с серверами локальной сети, работающими под управлением операционных систем: Microsoft, NetWare, Banyan VINES, AppleTalk.
Взаимодействие с клиентами сети, работающими под управлением: MS-DOS, Windows 3.x, Windows NT Workstation, Windows NT Server и Macintosh (UNIX через дополнительный шлюз TN3270).
Взаимодействие с клиентами через мосты, маршрутизаторы или сервер удаленного доступа RAS для Windows NT.
Шлюз SNA Server может использоваться в различных конфигурациях - один шлюз для доступа к одному хосту, один шлюз для доступа к нескольким хостам, много шлюзов для доступа к одному хосту, много шлюзов для доступа к нескольким хостам.
Шлюз поддерживает до 250 одновременных соединений в любых комбинациях восходящих соединений (с хостом), равноправных или нисходящих соединений. Шлюз поддерживает до 2 000 пользователей, а в одном домене Windows NT может быть до 50 шлюзов SNA Server. Шлюз использует ту учетную пользовательскую информацию, которая хранится на сервере Windows NT, а для доступа к хостам пользователям шлюза должны быть предоставлены специальные права. Шлюз можно администрировать и с хоста с помощью системы NetView.
Шлюзы
Итак, шлюз согласует коммуникационные протоколы одного стека с коммуникационными протоколами другого стека. Программные средства, реализующие шлюз, нет смысла устанавливать ни на одном из двух взаимодействующих компьютеров с разными стеками протоколов, гораздо рациональнее разместить их на некотором компьютере-посреднике. Прежде, чем обосновать это утверждение, рассмотрим принцип работы шлюза.
Рисунок 3.14 иллюстрирует принцип функционирования шлюза. В показанном примере шлюз, размещенный на компьютере 2, согласовывает протоколы клиентского компьютера 1 сети А с протоколами серверного компьютера 3 сети В. Допустим, что две сети используют полностью отличающиеся стеки протоколов. Как видно из рисунка, в шлюзе реализованы оба стека протоколов.

Рис. 3.14. Принципы функционирования шлюза
Запрос от прикладного процесса клиентского компьютера сети А поступает на прикладной уровень его стека протоколов. В соответствии с этим протоколом на прикладном уровне формируются соответствующий пакет (или несколько пакетов), в которых передается запрос на выполнение сервиса некоторому серверу сети В. Пакет прикладного уровня передается вниз по стеку компьютера сети А, а затем в соответствии с протоколами канального и физического уровней сети А поступает в компьютер 2, то есть в шлюз.
Здесь он передается от самого нижнего к самому верхнему уровню стека протоколов сети А. Затем пакет прикладного уровня стека сети А преобразуется (транслируется) в пакет прикладного уровня серверного стека сети В. Алгоритм преобразования пакетов зависит от конкретных протоколов и, как уже было сказано, может быть достаточно сложным. В качестве общей информации, позволяющей корректно провести трансляцию, может использоваться, например, информация о символьном имени сервера и символьном имени запрашиваемого ресурса сервера (в частности, это может быть имя каталога файловой системы). Преобразованный пакет от верхнего уровня стека сети В передается к нижним уровням в соответствии с правилами этого стека, а затем по физическим линиям связи в соответствии с протоколами физического и канального уровней сети В поступает в другую сеть к нужному серверу. Ответ сервера преобразуется шлюзом аналогично.
Шлюзы IP-сетей
За последние годы локальные сети масштаба предприятия увеличились в размерах и в настоящее время поддерживают жизненно необходимые для этих предприятий программы. Находясь на различных стадиях процесса интеграции сетей персональных компьютеров, организации-пользователи будут по разным причинам сталкиваться с необходимостью соединить хост-системы UNIX со своими сетями персональных компьютеров. На первых стадиях интеграции эти организации обычно просто хотят, чтобы пользователи UNIX-систем могли использовать недорогое периферийное оборудование, подключенное к сетям NetWare - принтеры, стриммеры и т.п. Важны также возможности перемещения и совместного использование файлов. Те организации, которые уже зашли достаточно далеко в процессе интеграции сетей, обычно начинают использовать хост-системы UNIX как файл-серверы или как системы конечного хранения и обработки баз данных. Рабочие станции персональных компьютеров в сети NetWare используют приложения предварительной обработки данных, имеющие доступ к базам данных хостов. И, наконец, в настоящее время многие организации хотели бы интегрировать приложения, работающие в их сетях персональных компьютеров, с приложениями хост-системы.
Проблемы соединения этих двух типов сетевых сред заключаются в том, что они используют различные стеки протоколов на всех уровнях, начиная с сетевого. Сети Novell NetWare используют протоколы IPX/SPX на сетевом уровне и протокол NCP на уровне взаимодействия верхних уровней клиентской и серверной частей ОС. В UNIX-сетях, как правило, используются протоколы стека DoD с сетевыми протоколам TCP/IP и такими протоколами уровня клиент-сервер, как telnet (эмуляция терминала), FTP (пересылка файлов) и популярный протокол NFS фирмы Sun, позволяющий монтировать удаленную файловую систему в локальное дерево каталогов.
На рисунке 7.6 показаны продукты фирмы Novell для взаимодействия с UNIX-сетями и основные выполняемые ими функции.
Символьные связи
Версия UNIX System V Release 4 вводит новый тип связи - мягкая связь, называемая символьной связью и реализуемая с помощью системного вызова symlink. Символьная связь - это файл данных, содержащий имя файла, с которым предполагается установить связь. Слово "предполагается" использовано потому, что символьная связь может быть создана даже с несуществующим файлом. При создании символьной связи образуется как новый вход в каталоге, так и новый индексный дескриптор inode. Кроме этого, резервируется отдельный блок данных для хранения полного имени файла, на который он ссылается.
Многие системные вызовы пользуются файлом символьных связей для поиска реального файла. Связанные файлы не обязательно располагаются в той же файловой системе.
Имеются три системных вызова, которые имеют отношение к символьным связям:
readlink - чтение полного имени файла или каталога, на который ссылается символьная связь. Эта информация хранится в блоке, связанном с символьной связью.
lstat - аналогичен системному вызову stat, но используется для получения информации о самой связи.
lchown - аналогичен системному вызову chown, но используется для изменения владельца самой символьной связи.
Синхронизация в распределенных системах
К вопросам связи процессов, реализуемой путем передачи сообщений или вызовов RPC, тесно примыкают и вопросы синхронизации процессов. Синхронизация необходима процессам для организации совместного использования ресурсов, таких как файлы или устройства, а также для обмена данными.
В однопроцессорных системах решение задач взаимного исключения, критических областей и других проблем синхронизации осуществлялось с использованием общих методов, таких как семафоры и мониторы. Однако эти методы не совсем подходят для распределенных систем, так как все они базируются на использовании разделяемой оперативной памяти. Например, два процесса, которые взаимодействуют, используя семафор, должны иметь доступ к нему. Если оба процесса выполняются на одной и той же машине, они могут иметь совместный доступ к семафору, хранящемуся, например, в ядре, делая системные вызовы. Однако, если процессы выполняются на разных машинах, то этот метод не применим, для распределенных систем нужны новые подходы.
Система управления компьютерами System Management Server
Эта система предназначена для централизованного управления объединенными в сеть персональными компьютерами.
Система ввода-вывода
Основу системы ввода-вывода ОС UNIX составляют драйверы внешних устройств и средства буферизации данных. ОС UNIX использует два различных интерфейса с внешними устройствами: байт-ориентированный и блок-ориентированный.
Системы обработки сообщений MHS и GroupWise
Для пользователей сетей NetWare сейчас доступны две мощные системы обработки сообщений: Message Handling System (MHS) и GroupWise. Некоторое пересечение функций этих систем объясняется тем, что первая система была разработана в недрах фирмы Novell уже достаточно давно и дошла в своем развитии до версии 2.0, а система GroupWise перешла к Novell как наследство компании Word Prefect, приобретенной Novell. У этих систем имеются достаточно четкие отличия: система MHS представляет собой основу для построения мощных систем электронной почты, а система GroupWise - это уже законченная электронная почта плюс построенная на ней надстройка для групповой работы над документами.
Cредства MHS фирмы Novell уже доступны в течение нескольких лет; на сегодняшний день более 1000 зарегистрированных корпоративных и независимых разработчиков программного обеспечения разработали приложения, использующие MHS. Последняя версия этой системы управления сообщениями по схеме "запоминание-и-передача" называется Global MHS. Она представляет собой работающее на сервере приложение, выполненное в форме NLM-модулей.
Доступ к MHS обеспечивается способом, очень отличающимся от распространенных программных интерфейсов электронной почты типа MAPI или VIM. MHS не имеет программируемого интерфейса. Файл-сообщение отсылается путем добавления текстового (ASCII) заголовка, который содержит инструкции о адресе и способе доставки. Этот файл с присоединенными сообщениями в двоичном или любом другом формате сохраняется в каталоге, который периодически опрашивается сервером MHS. В этом процессе не участвуют ни вызовы процедур, ни библиотечные функции. Хотя и с некоторой натяжкой, этот подход очень похож на способ адресации сообщений в протоколе SMTP, используемом в сетях Internet.
MHS-серверы имеют такие развитые свойства, как автоматическая маршрутизация по критерию стоимости или функции синхронизации справочников, которые обновляют справочники MHS во всей корпорации, независимо от того, где были сделаны изменения.
В новой версии NetWare 4. 1 справочная служба MHS интегрирована со службой каталогов NetWare NDS, что значительно снижает административные издержки - в сети существует единая глобальная справочная служба.
Для создания программируемого интерфейса к MHS третьи фирмы разработали динамические библиотеки среды Windows, функции которых автоматизируют адресацию сообщений в формате MHS, используя наглядные меню выбора адреса в стиле Windows. Фирма Novell сама недавно выпустила набор библиотек DLL, которые обеспечивают доступ к функциям MHS для приложений, использующих VIM, MAPI или CMC.
Для приложений управления документами MHS поддерживает встроенную трансляцию форматов документов. Для удаленных пользователей Novell поставляет продукт Remote MHS, который делает интерфейсы MHS, VIM, Simple MAPI и CMC доступными для любого удаленного Windows-приложения.
Как и в случае продуктов, основанных на моделях синхронного взаимодействия клиент-сервер и асинхронной передачи сообщений, корпоративные свойства средств модели "запоминание-и-передача" следует воспринимать с некоторой долей скептицизма. Несмотря на многочисленные обещания, продукты этой модели еще не обеспечивают поддержку гетерогенности, необходимую для полномасштабной циркуляции документов, изображений и форм по корпоративной сети. Легкая синхронизация справочных служб различных систем модели "запоминание-и-передача" все еще только ожидается, равно как и следование стандарту X.500. Пока магистрали таких служб непригодны для транзакционных приложений, если только сервисы "запоминание-и-передача" не интегрированы в транзакционные журнальные системы (очень мало поставщиков говорит сегодня об этом).
Несмотря на необходимость улучшений, разработчики корпоративных сетей уже начали использовать системы передачи сообщений модели "запоминание-и-передача" для критических приложений, включая транспортировку запросов к базам данных и обновление баз данных. Действительно, организациям, которые интенсивно используют Windows, cc:Mail или NetWare, было бы странно игнорировать ресурсы модели "запоминание-и-передача" при рассмотрении вариантов корпоративной интеграции.
Сегодня магистрали сервисов "запоминание-и-передача" наилучшим образом подходят широкому кругу приложений обработки файлов и документов, и у них есть все шансы стать чем то более значительным, чем они есть, в недалеком будущем.
GroupWise - это в основном пакет электронной почты, но в то же время он предоставляет из себя и нечто большее. В него включены средства индивидуального, группового и ресурсного планирования. Пользователи могут составлять собственные списки неотложных дел и "заводить" напоминающие о них будильники. С помощью прекрасно работающего механизма правил можно, например, автоматически удалить все сообщения заданного пользователя или послать ответ по обратному адресу.
Пакет теперь поддерживает 12 клиентских платформ и использует для запуска серверных процессов серверы NetWare и несколько различных UNIX-серверов. Ранее сетевые администраторы вынуждены были некоторым задачам WordPerfect Office отводить выделенные DOS и OS/2 серверы.
Недостатком версии GroupWise 4.1 является то обстоятельство, что шлюзы для связи с другими почтовыми системами и доменами GroupWise по-прежнему работают только на DOS. Поэтому асинхронные коммуникации необходимо распределять по DOS-машинам. Таким образом, на пути к тому, чтобы продукту было достаточно для работы одного сервера, сделан заметный шаг.
В состав GroupWise входит предназначенная для удаленных пользователей клиентская часть, имеющая тот же интерфейс, что и версия для локальных рабочих станций.
Для большинства организаций существенно соответствие GroupWise стандарту X.500.
Серверная часть GroupWise состоит из нескольких NLM-модулей, отвечающих за пересылку сообщений между пользовательскими почтовыми ящиками, почтовыми отделениями и удаленными доменами. Вплоть до версии 4.1 эти функции выполнялись только на компьютерах, работающих под управлением DOS, либо в сеансе DOS под управлением OS/2. Реализация в виде NLM-модулей оказалась значительно удобнее и проще в эксплуатации.
Перед NLM-модулями, входящими в пакет GroupWise, на сервер NetWare следует загрузить несколько других NLM-модулей, и, прежде всего, разработанный Novell вспомогательный NLM-модуль протокола SNMP.
Поддержка данного протокола включена в GroupWise, однако модуль должен быть загружен даже в том случае, когда поддержка SNMP не нужна.
Одним из основных NLM-модулей является сервер сообщений MS. Этот модуль отвечает за пересылку корреспонденции между входящими в состав домена почтовыми отделениями. Модуль Office Server занимается доставкой корреспонденции от сервера сообщений к почтовым ящикам пользователей. Для каждого почтового отделения, входящего в состав домена, загружается своя копия модуля Office Server.
Административный сервер ADS отвечает за передачу запросов на синхронизацию каталогов между доменами GroupWise.
В состав пакета входит модуль BDS, осуществляющий синхронизацию каталогов GroupWise и NetWare. Он выявляет любые изменения в базе данных сетевых ресурсов среды NetWare 3.x и 4.x и в соответствие с ними обновляет различную служебную информацию GroupWise, в частности списки пользователей.
Количество шлюзов, предлагаемых в составе пакета GroupWise, впечатляет, однако это достижение частично обесценивается отсутствием поддержки различных платформ. Все 23 имеющихся в настоящее время шлюза являются DOS-ориентированными. Набор обслуживаемых систем весьма широк - от OV/VM компании IBM и стандарта Х.400 до cc:mail компании Lotus и Massage Router компании DEC. Связь с удаленными доменами осуществляется с помощью шлюза Async Gateway. В дальнейшем предполагается использовать для этих целей пакет NetWare Connect.
Диапазон услуг, предлагаемых GroupWise, очень широк. Интегрированные в пакет средства планирования допускают составление графиков личных встреч и деловых совещаний с учетом занятости таких специфических ресурсов, как конференц-залы или аудиовизуальное оборудование. В области электронных конференций Novell реализовала популярную в Internet технология обслуживания по спискам, которая дает возможность подписаться на электронный бюллетень и получать все посылаемые в него сообщения.
Служба каталогов DCE состоит из 4-х элементов:
CDS (Cell Directory Service) - служба каталогов ячейки. Ячейка сети - это группа систем, администрируемых как единое целое. CDS оптимизируется для локального доступа. Большинство запросов к службе каталогов относятся к ресурсам той же ячейки. Каждая ячейка сети нуждается по крайней мере в одной CDS.
GDA (Global Directory Agent) - агент глобального каталога. GDA - это шлюз имен, который соединяет домен DCE с другими административными доменами посредством глобальной службы каталогов X.500 и DNS (domain name service - сервис имен домена). GDA передает запрос на имя, которое он не смог найти в локальной ячейке, службе каталогов другой ячейки, или глобальной службе каталогов (в зависимости от места хранения имени). Для того, чтобы отыскать имя, клиент делает запрос к локальному агенту GDA. Затем GDA передает запрос на междоменное имя службе X.500. Эта служба возвращает ответ GDA, который в свою очередь передает его клиенту. OSF GDA может быть совместим с любой схемой глобального именования.
GDS (Global Directory Service) - глобальная служба каталогов. Основанная на стандарте X.500, GDS работает на самом верхнем уровне иерархии и обеспечивает связь множества ячеек в множестве организаций.
XDS (X/Open Directory Service) - обеспечивает поддержку X/Open API функций службы каталогов и позволяет разработчикам писать приложения, независимые от нижележащих уровней архитектуры службы каталогов. XDS-совместимые приложения будут работать одинаковым образом со службами каталогов DCE и X.500.
Службы именования ресурсов и проблемы прозрачности доступа
Подобно большой организации, большая корпоративная сеть нуждается в централизованном хранении как можно более полной справочной информации о самой себе (начиная с данных о пользователях, серверах, рабочих станциях и кончая данными о кабельной системе). Естественно организовать эту информацию в виде базы данных, ведение которой поручить сетевой операционной системе. Данные из этой базы могут быть востребованы многими сетевыми системными приложениями, в первую очередь системами управления и администрирования. Кроме этого, такая база полезна при организации электронной почты, систем коллективной работы, службы безопасности, службы инвентаризации программного и аппаратного обеспечения сети, да и для практически любого крупного бизнес-приложения.
Хотя полезных применений единой справочной службы много, она нужна по крайней мере для эффективного решения задачи администрирования, то есть ведения учетной информации на пользователей сети и определения прав доступа этих пользователей к разделяемым ресурсам сети. Эта задача всегда решалась каким-либо способом во всех многопользовательских операционных системах, не обязательно сетевых. В локальных версиях UNIX имеются файлы с предопределенными именами, хранящие эту информацию - например, файл /etc/passwd хранит информацию о пользователях и их паролях, а также о группах пользователей.
В идеале сетевая справочная информация должна быть реализована в виде единой базы данных, а не представлять собой набор баз данных, специализирующихся на хранении информации того или иного вида, как это часто бывает в реальных операционных системах. Например, в Windows NT имеется по крайней мере пять различных типов справочных баз данных. Главный справочник домена (NT Domain Directory Service) хранит информацию о пользователях, которая используется при организации их логического входа в сеть. Данные о тех же пользователях могут содержаться и в другом справочнике, используемом электронной почтой Microsoft Mail. Еще три базы данных поддерживают разрешение низкоуровневых адресов: WINS - устанавливает соответствие Netbios-имен IP-адресам, справочник DNS - сервер имен домена - оказывается полезным при подключении NT-сети к Internet, и наконец, справочник протокола DHCP используется для автоматического назначения IP-адресов компьютерам сети.
Ближе к идеалу находятся справочные службы, поставляемые фирмой Banyan (продукт Streettalk III) и фирмой Novell (NetWare Directory Services), предлагающие единый справочник для всех сетевых приложений.
Единая база данных, хранящая справочную информацию, предоставляет все то же многообразие возможностей и порождает все то же множество проблем, что и любая другая крупная база данных. Она позволяет осуществлять различные операции поиска, сортировки, модификации и т.п., что очень сильно облегчает жизнь как администраторам, так и пользователям. Набор разрозненных баз данных не предоставляет такого прозрачного доступа к ресурсам сети, как это имеет место в случае использования ОС NetWare 3.x с ее базой bindery, локальной для каждого сервера. В последнем случае пользователь должен заранее знать, на каком сервере находится нужный ему ресурс и производить логическое подключение к этому серверу для получения доступа к этому ресурсу. Для того, чтобы получить доступ к ресурсам какого-нибудь сервера, пользователь должен иметь там свою учетную информацию, которая дублируется таким образом на всех серверах сети. В единой базе данных о каждом пользователе существует только одна запись.
Но за удобства приходится расплачиваться решением проблем распределенности, репликации и синхронизации, которые возникают при построении крупномасштабной базы данных для большой сети.
Реализация справочной службы над полностью централизованной базой данных, хранящейся только в виде одной копии на одном из серверов сети, не подходит для большой системы по нескольким причинам, и в первую очередь из-за низкой производительности и низкой надежности такого решения. Производительность будет низкой из-за того, что запросы на логический вход всех пользователей будут поступать в единственный сервер, который при большом количестве пользователей обязательно перестанет справляться с их обработкой, то есть такое решение плохо масштабируется в отношении количества пользователей и разделяемых ресурсов. Надежность также не может быть высокой в системе с единственной копией данных.
Кроме снятия ограничений по производительности и надежности, желательно, чтобы структура базы данных позволяла производить логическое группирование ресурсов и пользователей по структурным подразделениям предприятия и назначать для каждой такой группы своего администратора.
Проблемы сохранения производительности и надежности при увеличении масштаба сети решаются за счет использования распределенных баз данных справочной информации. Разделение данных между несколькими серверами снижает нагрузку на каждый сервер, а надежность при этом достигается за счет наличия нескольких копий (называемых часто репликами) каждой части базы данных. Для каждой части базы данных можно назначить своего администратора, который обладает правами доступа только к объектам своей порции информации о всей системе. Для пользователя же (и для сетевых приложений) такая распределенная база данных представляется единой базой данных, которая обеспечивает доступ ко всем ресурсам сети вне зависимости от того, с какой рабочей станции осуществил свой вход в сеть пользователь.
Существует два подхода к организации справочной службы сети: доменный и глобальный. Рассмотрим эти подходы на конкретных примерах - доменной справочной службе ОС Windows NT и глобальной справочной службе NDS ОС NetWare. Естественно, это не единственные операционные системы, где такие службы имеются - доменная служба реализована в Microsoft LAN Manager и IBM LAN Server, а глобальная справочная служба - в ОС Banyan VINES (служба Streettalk III). Более того, существует стандарт X.500, разработанный МККТТ для глобальной справочной службы почтовых систем, который с успехом может применяться и применяется для хранения любой справочной информации.
Solaris
Solaris 2.x - это операционная система компании Sun, базирующаяся на UNIX System V Release 4. Она включает:
базовую операционную систему SunOS 5.x и систему сетевой поддержки ONC (Open Network Computing);
оконную систему Open Windows версии 3.х (построенную на базе X11R5) с интерфейсом в стандарте OPEN LOOK;
набор вспомогательных утилит (диспетчер файлов, почту, печать, календарь и другие) DeskSet версии 3.х.
Компания Sun доработала исходный код UNIX System V Release 4 в соответствии со своими потребностями. Новая ОС Solaris 2.x имеет несколько основных отличий от базовой операционной системы:
реализована многонитевость,
поддерживается симметричная многопроцессорная обработка,
предусмотрен режим реального времени: допускаются прерывания процессов в системной фазе, что обеспечивает гарантированное время ответа на запросы.
Сетевая среда Solaris 2.x включает в себя известную и уже ставшую стандартом сетевую файловую систему NFS, глобальную справочную службу и средства разработки распределенных приложений. Сегодня Solaris стал одной из самых распространенных версий UNIX. Эта ОС работает на платформах SPARC, Intel x86, а, возможно, в скором времени будет работать и на PowerPC.
Осенью 1994 года компания Sun Microsystems объявила о выпуске новой версии операционной системы Solaris для платформ SPARC и Intel x86 - Solaris 2.4. Эта версия появилась в результате тщательного и долгого тестирования предыдущих версий. На сегодняшний день Solaris 2.4 является наиболее стабильной и качественной версией Solaris. Новое качество выражается не только в устранении всех замеченных в ходе тестирования недостатков, но и в более высокой производительности, чем у Solaris 2.x. В частности, увеличена средняя производительность при работе с СУБД за счет реализации асинхронных операций ввода-вывода в ядре, а не в библиотеках. Производительность файлового сервера NFS увеличилась в результате более эффективного использования механизма многонитевой обработки. Кроме того, гораздо быстрее стали работать протоколы TCP/IP и программы, реализующие пользовательский интерфейс. Важным свойством Solaris 2.4 является переносимость - программы, написанные для SPARC, могут выполняться на х86 и наоборот.
Состояние процессов
В многозадачной (многопроцессной) системе процесс может находиться в одном из трех основных состояний:
ВЫПОЛНЕНИЕ - активное состояние процесса, во время которого процесс обладает всеми необходимыми ресурсами и непосредственно выполняется процессором;
ОЖИДАНИЕ - пассивное состояние процесса, процесс заблокирован, он не может выполняться по своим внутренним причинам, он ждет осуществления некоторого события, например, завершения операции ввода-вывода, получения сообщения от другого процесса, освобождения какого-либо необходимого ему ресурса;
ГОТОВНОСТЬ - также пассивное состояние процесса, но в этом случае процесс заблокирован в связи с внешними по отношению к нему обстоятельствами: процесс имеет все требуемые для него ресурсы, он готов выполняться, однако процессор занят выполнением другого процесса.
В ходе жизненного цикла каждый процесс переходит из одного состояния в другое в соответствии с алгоритмом планирования процессов, реализуемым в данной операционной системе. Типичный граф состояний процесса показан на рисунке 2.1.
В состоянии ВЫПОЛНЕНИЕ в однопроцессорной системе может находиться только один процесс, а в каждом из состояний ОЖИДАНИЕ и ГОТОВНОСТЬ - несколько процессов, эти процессы образуют очереди соответственно ожидающих и готовых процессов. Жизненный цикл процесса начинается с состояния ГОТОВНОСТЬ, когда процесс готов к выполнению и ждет своей очереди. При активизации процесс переходит в состояние ВЫПОЛНЕНИЕ и находится в нем до тех пор, пока либо он сам освободит процессор, перейдя в состояние ОЖИДАНИЯ какого-нибудь события, либо будет насильно "вытеснен" из процессора, например, вследствие исчерпания отведенного данному процессу кванта процессорного времени. В последнем случае процесс возвращается в состояние ГОТОВНОСТЬ. В это же состояние процесс переходит из состояния ОЖИДАНИЕ, после того, как ожидаемое событие произойдет.

Рис. 2.1. Граф состояний процесса в многозадачной среде
Совместимость
Одним из аспектов совместимости является способность ОС выполнять программы, написанные для других ОС или для более ранних версий данной операционной системы, а также для другой аппаратной платформы.
Необходимо разделять вопросы двоичной совместимости и совместимости на уровне исходных текстов приложений. Двоичная совместимость достигается в том случае, когда можно взять исполняемую программу и запустить ее на выполнение на другой ОС. Для этого необходимы: совместимость на уровне команд процессора, совместимость на уровне системных вызовов и даже на уровне библиотечных вызовов, если они являются динамически связываемыми.
Совместимость на уровне исходных текстов требует наличия соответствующего компилятора в составе программного обеспечения, а также совместимости на уровне библиотек и системных вызовов. При этом необходима перекомпиляция имеющихся исходных текстов в новый выполняемый модуль.
Совместимость на уровне исходных текстов важна в основном для разработчиков приложений, в распоряжении которых эти исходные тексты всегда имеются. Но для конечных пользователей практическое значение имеет только двоичная совместимость, так как только в этом случае они могут использовать один и тот же коммерческий продукт, поставляемый в виде двоичного исполняемого кода, в различных операционных средах и на различных машинах.
Обладает ли новая ОС двоичной совместимостью или совместимостью исходных текстов с существующими системами, зависит от многих факторов. Самый главный из них - архитектура процессора, на котором работает новая ОС. Если процессор, на который переносится ОС, использует тот же набор команд (возможно с некоторыми добавлениями) и тот же диапазон адресов, тогда двоичная совместимость может быть достигнута достаточно просто.
Гораздо сложнее достичь двоичной совместимости между процессорами, основанными на разных архитектурах. Для того, чтобы один компьютер выполнял программы другого (например, DOS-программу на Mac), этот компьютер должен работать с машинными командами, которые ему изначально непонятны.
Например, процессор типа 680x0 на Mac должен исполнять двоичный код, предназначенный для процессора 80x86 в PC. Процессор 80x86 имеет свои собственные дешифратор команд, регистры и внутреннюю архитектуру. Процессор 680x0 не понимает двоичный код 80x86, поэтому он должен выбрать каждую команду, декодировать ее, чтобы определить, для чего она предназначена, а затем выполнить эквивалентную подпрограмму, написанную для 680x0. Так как к тому же у 680x0 нет в точности таких же регистров, флагов и внутреннего арифметико-логического устройства, как в 80x86, он должен имитировать все эти элементы с использованием своих регистров или памяти. И он должен тщательно воспроизводить результаты каждой команды, что требует специально написанных подпрограмм для 680x0, гарантирующих, что состояние эмулируемых регистров и флагов после выполнения каждой команды будет в точности таким же, как и на реальном 80x86.
Это простая, но очень медленная работа, так как микрокод внутри процессора 80x86 исполняется на значительно более быстродействующем уровне, чем эмулирующие его внешние команды 680x0. За время выполнения одной команды 80x86 на 680x0, реальный 80x86 может выполнить десятки команд. Следовательно, если процессор, производящий эмуляцию, не настолько быстр, чтобы компенсировать все потери при эмуляции, то программы, исполняющиеся под эмуляцией, будут очень медленными.
Выходом в таких случаях является использование так называемых прикладных сред. Учитывая, что основную часть программы, как правило, составляют вызовы библиотечных функций, прикладная среда имитирует библиотечные функции целиком, используя заранее написанную библиотеку функций аналогичного назначения, а остальные команды эмулирует каждую по отдельности.
Соответствие стандартам POSIX также является средством обеспечения совместимости программных и пользовательских интерфейсов. Во второй половине 80-х правительственные агентства США начали разрабатывать POSIX как стандарты на поставляемое оборудование при заключении правительственных контрактов в компьютерной области.POSIX - это "интерфейс переносимой ОС, базирующейся на UNIX". POSIX - собрание международных стандартов интерфейсов ОС в стиле UNIX. Использование стандарта POSIX (IEEE стандарт 1003.1 - 1988) позволяет создавать программы стиле UNIX, которые могут легко переноситься из одной системы в другую.
Совместимость с NetWare
Сетевая ОС LAN Server не содержит средств прямой связи с серверами NetWare (то есть не имеет стека протоколов Novell). Отчасти, это результат архитектурного решения: LAN Server работает под управлением OS/2, для которой пользователи могут приобрести отдельную программу - редиректор для NetWare. Можно создать шлюз между серверами по схеме "сервер под управлением базовой ОС", хотя результат получается более скромный, чем у системы Windows NT Server. Для этого нужно запустить редиректор NetWare на машине, функционирующей под управлением LAN Server. Пропускная способность такого соединения невелика, поэтому применять его надо с осторожностью.
Совместимость Windows NT с NetWare
Совместимость сетевых операционных систем предполагает использование одинакового стека коммуникационных протоколов, в том числе и верхнего прикладного уровня. Протоколы верхнего уровня (NCP, SMB, NFS, FTP, telnet) включают две части - клиентскую и серверную. При взаимодействии двух компьютеров на каждой стороне могут присутствовать как обе части прикладного протокола, так и по одной его части, в зависимости от этого образуется или одна, или две пары "клиент-сервер".
Для клиентской части протокола верхнего уровня, реализованного в виде модуля операционной системы, используются разные названия - редиректор (redirector), инициатор запросов или запросчик (requester). Эти компоненты получают запросы от приложений на доступ к удаленным ресурсам, расположенным на серверах, и ведут диалог с сервером в соответствии с каким-либо протоколом прикладного уровня. Совокупность функций, которая может использовать приложение для обращения к редиректору, называется прикладным интерфейсом (API) редиректора.
Существующая версия Windows NT 3.51 имеет встроенную поддержку стека протоколов Novell, а именно протоколов IPX/SPX и клиентской части NCP. При разработке первой версии Windows NT 3.1 между Microsoft и Novell существовало соглашение о том, что редиректор, реализующий клиентскую часть протокола NCP, будет написан силами сотрудников Novell и передан Microsoft в течение 60 дней после выпуска коммерческой версии Windows NT 3.1. Однако первая версия редиректора от Novell появилась только спустя четыре месяца и обладала существенными ограничениями: не поддерживался полностью API редиректора NetWare, в частности, поддерживались только 32-х разрядные вызовы, что означало невозможность работы старых 16 разрядных приложений клиента NetWare.
Через некоторое время Microsoft разработала свою собственную версию редиректора для NetWare, проведя большую работу по освоению NCP. Этот вариант оказался гораздо лучше, однако и он имеет недостатки: в нем отсутствует поддержка входных сценариев NetWare и службы каталогов NetWare Directory Services.
Отсутствие поддержки входных сценариев означает, что администратору сети будет сложно автоматизировать создание индивидуальной операционной среды NetWare для пользователей, использующих Windows NT в качестве клиентской машины серверов NetWare.
Организация, использующая NetWare, может добавить Windows NT в качестве:
клиентской рабочей станции,
файлового сервера или сервера печати наряду с NetWare,
файлового сервера или сервера печати вместо NetWare,
сервера баз данных или других приложений.
Сеть с файловыми серверами различных типов (NetWare и Windows NT) порождает сложные технические проблемы. Даже если серверы используют одинаковые транспортные протоколы, в данном случае протокол IPX (в реализации Microsoft имеющий название NWLink), клиентским рабочим станциям все равно придется загружать два разных инициатора запросов. У клиента, работающего в среде MS-DOS, для этого может просто не хватить памяти.
Для смягчения перехода от NetWare к Windows NT Server разработано несколько инструментальных программ, в том числе утилита Migration Tool, которая включена в комплект поставки Windows NT Server. Эта утилита переносит учетную информацию пользователей (имена пользователей, ограничения и права доступа) и данные с одного или нескольких файловых серверов NetWare на сервер Windows NT. Migration Tool подбирает наилучшее соответствие между возможностями NetWare и возможностями Windows NT. Однако имеется ряд существенных различий в том, как обрабатываются такие вещи, как ограничения. В NetWare подобная информация обрабатывается для каждого пользователя в отдельности, а в Windows NT она общая для целого сервера.
Компания Beame and Whiteside Software создала первый NFS сервер для Windows NT, а также продукт под названием BW-Multiconnect, который превращает сервер Windows NT в сервер NetWare. Системы Windows NT с установленным продуктом BW-Multiconnect посылают широковещательные сообщения по протоколу SAP (протокол объявления сервисов и серверов по сети - Service Advertising Protocol, с помощью которого клиенты NetWare узнают о наличии в сети серверов и о тех услугах, которые они предоставляют).
BW-Multiconnect должен облегчить сосуществование и миграцию от NetWare к Windows NT. Хотя он и может работать как единственный NCP-сервер сети, он не предназначен для этой роли, так как предоставляет лишь ограниченный набор утилит под Windows и DOS, и не обрабатывает входных командных файлов NetWare. Но когда в сети есть "настоящий" файловый сервер NetWare, то пользователи могут войти в этот сервер, выполнить системный входной командный файл, а затем подсоединиться к серверу Windows NT. Этот продукт превращает в сервер NetWare как Windows NT Server, так и Windows NT Workstation.
Microsoft ведет работу над созданием своих собственных файл- и принт-серверов NetWare для Windows NT. Кроме этого, скоро должен появиться редиректор NetWare для Windows NT, поддерживающий NDS.
Рассмотренные способы организации взаимодействия сетей построены на использовании принципа мультиплексирования протоколов. Другим подходом является использование шлюза. Шлюз действует как транслятор, что позволяет получать доступ к файлам и ресурсам печати на файловом сервере NetWare, не пользуясь ничем, кроме загруженного редиректора Windows NT. Шлюз преобразовывает SMB-сообщения, посланные каким-либо Windows NT-клиентом, в NCP-сообщения, которые посылаются на серверы NetWare. В этом случае имеется экономия памяти на клиентских машинах, так как не требуется загружать дополнительные редиректоры.
Вариант шлюза подходит только для приложений, использующих для запросов к серверу NetWare только стандартный API, а при использовании специфического для NetWare API нельзя обойтись без установки дополнительного редиректора.
Если NetWare-шлюз загружен, Windows NT Server может подсоединиться к одному или нескольким файловым серверам NetWare и подключиться к любому дисковому тому, очереди на печать или каталогу. После того, как сервер подключился к ресурсам, их можно начинать использовать совместно с другими пользователями через File Manager или Print manager, как если бы они были локальными ресурсами.То есть пользователи, вошедшие в домен, на сервере которого установлен шлюз к NetWare, получают доступ к серверам NetWare.
Трансляция протоколов в шлюзе замедляет доступ к серверу NetWare по сравнению с доступом через редиректор клиента. При тестировании замедление в малозагруженном шлюзе составило от 10% до 15%.
Имя пользователя, используемое шлюзом для входа в сервер NetWare, должно входить в группу NTGateway на сервере Windows NT. Разрешение на доступ к ресурсам NetWare предоставляется пользователям сервером Windows NT точно так же, как если бы это были его локальные ресурсы.
Современные архитектуры файловых систем
Разработчики новых операционных систем стремятся обеспечить пользователя возможностью работать сразу с несколькими файловыми системами. В новом понимании файловая система состоит из многих составляющих, в число которых входят и файловые системы в традиционном понимании.
Новая файловая система имеет многоуровневую структуру (рисунок 2.39), на верхнем уровне которой располагается так называемый переключатель файловых систем (в Windows 95, например, такой переключатель называется устанавливаемым диспетчером файловой системы - installable filesystem manager, IFS). Он обеспечивает интерфейс между запросами приложения и конкретной файловой системой, к которой обращается это приложение. Переключатель файловых систем преобразует запросы в формат, воспринимаемый следующим уровнем - уровнем файловых систем.

Рис. 2.39. Архитектура современной файловой системы
Каждый компонент уровня файловых систем выполнен в виде драйвера соответствующей файловой системы и поддерживает определенную организацию файловой системы. Переключатель является единственным модулем, который может обращаться к драйверу файловой системы. Приложение не может обращаться к нему напрямую. Драйвер файловой системы может быть написан в виде реентерабельного кода, что позволяет сразу нескольким приложениям выполнять операции с файлами. Каждый драйвер файловой системы в процессе собственной инициализации регистрируется у переключателя, передавая ему таблицу точек входа, которые будут использоваться при последующих обращениях к файловой системе.
Для выполнения своих функций драйверы файловых систем обращаются к подсистеме ввода-вывода, образующей следующий слой файловой системы новой архитектуры. Подсистема ввода вывода - это составная часть файловой системы, которая отвечает за загрузку, инициализацию и управление всеми модулями низших уровней файловой системы. Обычно эти модули представляют собой драйверы портов, которые непосредственно занимаются работой с аппаратными средствами. Кроме этого подсистема ввода-вывода обеспечивает некоторый сервис драйверам файловой системы, что позволяет им осуществлять запросы к конкретным устройствам.
Подсистема ввода-вывода должна постоянно присутствовать в памяти и организовывать совместную работу иерархии драйверов устройств. В эту иерархию могут входить драйверы устройств определенного типа (драйверы жестких дисков или накопителей на лентах), драйверы, поддерживаемые поставщиками (такие драйверы перехватывают запросы к блочным устройствам и могут частично изменить поведение существующего драйвера этого устройства, например, зашифровать данные), драйверы портов, которые управляют конкретными адаптерами.
Большое число уровней архитектуры файловой системы обеспечивает авторам драйверов устройств большую гибкость - драйвер может получить управление на любом этапе выполнения запроса - от вызова приложением функции, которая занимается работой с файлами, до того момента, когда работающий на самом низком уровне драйвер устройства начинает просматривать регистры контроллера. Многоуровневый механизм работы файловой системы реализован посредством цепочек вызова.
В ходе инициализации драйвер устройства может добавить себя к цепочке вызова некоторого устройства, определив при этом уровень последующего обращения. Подсистема ввода-вывода помещает адрес целевой функции в цепочку вызова устройства, используя заданный уровень для того, чтобы должным образом упорядочить цепочку. По мере выполнения запроса, подсистема ввода-вывода последовательно вызывает все функции, ранее помещенные в цепочку вызова.
Внесенная в цепочку вызова процедура драйвера может решить передать запрос дальше - в измененном или в неизмененном виде - на следующий уровень, или, если это возможно, процедура может удовлетворить запрос, не передавая его дальше по цепочке.
Способы адресации
Для того, чтобы послать сообщение, необходимо указать адрес получателя. В очень простой сети адрес может задаваться в виде константы, но в более сложных сетях нужен и более изощренный способ адресации.
Одним из вариантов адресации на верхнем уровне является использование физических адресов сетевых адаптеров. Если в получающем компьютере выполняется только один процесс, то ядро будет знать, что делать с поступившим сообщением - передать его этому процессу. Однако, если на машине выполняется несколько процессов, то ядру не известно, какому из них предназначено сообщение, поэтому использование сетевого адреса адаптера в качестве адреса получателя приводит к очень серьезному ограничению - на каждой машине должен выполняться только один процесс.
Альтернативная адресная система использует имена назначения, состоящие из двух частей, определяющие номер машины и номер процесса. Однако адресация типа "машина-процесс" далека от идеала, в частности, она не гибка и не прозрачна, так как пользователь должен явно задавать адрес машины-получателя. В этом случае, если в один прекрасный день машина, на которой работает сервер, отказывает, то программа, в которой жестко используется адрес сервера, не сможет работать с другим сервером, установленном на другой машине.
Другим вариантом могло бы быть назначение каждому процессу уникального адреса, который никак не связан с адресом машины. Одним из способов достижения этой цели является использование централизованного механизма распределения адресов процессов, который работает просто, как счетчик. При получении запроса на выделение адреса он просто возвращает текущее значение счетчика, а затем наращивает его на единицу. Недостатком этой схемы является то, что централизованные компоненты, подобные этому, не обеспечивают в достаточной степени расширяемость систем. Еще один метод назначения процессам уникальных идентификаторов заключается в разрешении каждому процессу выбора своего собственного идентификатора из очень большого адресного пространства, такого как пространство 64-х битных целых чисел.
Вероятность выбора одного и того же числа двумя процессами является ничтожной, а система хорошо расширяется. Однако здесь имеется одна проблема: как процесс-отправитель может узнать номер машины процесса-получателя. В сети, которая поддерживает широковещательный режим (то есть в ней предусмотрен такой адрес, который принимают все сетевые адаптеры), отправитель может широковещательно передать специальный пакет, который содержит идентификатор процесса назначения. Все ядра получат эти сообщения, проверят адрес процесса и, если он совпадает с идентификатором одного из процессов этой машины, пошлют ответное сообщение "Я здесь", содержащее сетевой адрес машины.
Хотя эта схема и прозрачна, но широковещательные сообщения перегружают систему. Такой перегрузки можно избежать, выделив в сети специальную машину для отображения высокоуровневых символьных имен. При применении такой системы процессы адресуются с помощью символьных строк, и в программы вставляются эти строки, а не номера машин или процессов. Каждый раз перед первой попыткой связаться, процесс должен послать запрос специальному отображающему процессу, обычно называемому сервером имен, запрашивая номер машины, на которой работает процесс-получатель.
Совершенно иной подход - это использование специальной аппаратуры. Пусть процессы выбирают свои адреса случайно, а конструкция сетевых адаптеров позволяет хранить эти адреса. Теперь адреса процессов не обнаруживаются путем широковещательной передачи, а непосредственно указываются в кадрах, заменяя там адреса сетевых адаптеров.
Способы обеспечения надежности
В системах NetWare предусмотрен ряд функций, обеспечивающих надежность системы и целостность данных. Ниже перечислены функции, которые обеспечивают защиту всех частей сервера: от устройств хранения данных до критичных файлов прикладных программ. Наличие таких функций позволяет NetWare обеспечить очень высокий уровень надежности сети.
Средства обеспечения надежности SFT I:
Проверка чтением после записи. После записи на диск каждый блок данных немедленно считывается в память для проверки читаемости. Первоначальное содержание блока не стирается до окончания проверки. Если данные не читаются, они записываются в другой блок диска, а первый блок помечается как дефектный.
Дублирование каталогов. NetWare хранит копию структуры корневого каталога. Если портится основная структура, то начинает использоваться резервная.
Дублирование таблицы размещения файлов FAT. NetWare хранит копию FAT и использует ее при порче основной таблицы FAT.
Оперативное исправление 1 (Hot Fix 1). Запись или перезапись данных из дефектных блоков в специальную резервную область диска.
Контроль UPS.
Средства обеспечения надежности SFT II:
Зеркальное отображение дисков, подключенных к одному дисковому контроллеру (Disk Mirroring).
Дуплексирование дисков, подключенных к различным дисковым контроллерам (Disk Duplexing).
Оперативное исправление 2 (Hot Fix 2). Повторное выполнение операции чтения на отраженном диске и запись данных в резервную область.
Система отслеживания транзакций (TTS).
Средства обеспечения надежности SFT III заключаются в полном динамическом зеркальном отображении двух серверов, которые могут находится на значительном удалении друг от друга (при использовании оптоволоконного кабеля для межсерверной связи - до 4 км).
Средства обеспечения надежности уровней SFT I и SFT II реализованы в NetWare v3.11, NetWare v3.12 и NetWare v4.x. Уровень надежности SFT III реализован пока только в NetWare SFT III v3.11.
Способы обеспечения открытости и расширяемости
Все сетевые сервисы, утилиты сервера или работающие на сервере приложения выполнены в NetWare в виде загружаемых модулей - NetWare Loadable Modules, NLMs, которые могут динамически загружаться и выгружаться в любое время без остановки сервера. Структура ОС NetWare приведена на рисунке 7.1.
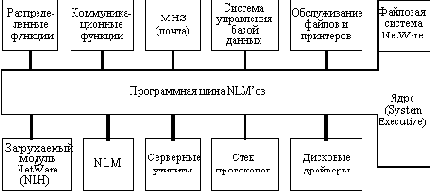
Рис. 7.1. Структура ОС NetWare
Ядро системы, называемое System Executive, выполняет базовые задачи ОС по управлению памятью, планированию и диспетчированию нитей, управлению файловой системой, также поддерживает программную шину для интерфейса NLM'ов. Каждый NLM выполняет либо функции операционной системы (драйвер диска или сетевого адаптера, утилита пространства имен, файловый сервер или модуль почтового сервиса), либо является пользовательским модулем, реализующим дополнительный сетевой сервис - например, сервис SQL-сервера или сервера печати. Для ядра системы все модули NLM равноправны, поэтому расширение или сужение функций системы осуществляется путем добавления или выгрузки соответствующего NLM'а.
Novell обеспечивает расширяемость системы NetWare за счет предоставления программистам набора инструментальных средств и строго описанных интерфейсов API для разработки собственных NLM-приложений, использующих все возможности 32-разрядного окружения. В настоящее время существует большое количество программных систем третьих фирм, реализованных в виде NLM-приложений, для серверов NetWare - серверы баз данных, коммуникационные серверы и т.п.
Открытость ОС NetWare обеспечивается поддержкой ею наиболее популярных стеков протоколов в строгом соответствии с существующими стандартами. NetWare поддерживает такие популярные сетевые протоколы, как IPX/SPX, TCP/IP, Apple Talk, и средства их мультиплексирования, такие как STREAMS и TLI. Стандарт ODI позволяет независимым разработчикам сетевых адаптеров легко включать свои NLM-драйверы в состав серверной ОС NetWare. Кроме того, фирма Novell разработала для NetWare большое количество программных средств - шлюзов к другим широко распространенным сетям, таким, как сети Internet и SNA.
Сравнение вариантов организации взаимодействия сетей
Возвращаясь к принципам организации взаимодействия сетей, сравним два основных подхода - мультиплексирование протоколов и трансляцию протоколов (шлюзы).
Встроенные в сетевую ОС средства мультиплексирования протоколов дают все те преимущества, которые присущи встроенным средствам:
Эти средства не нужно отдельно приобретать;
Нет проблем их совместимости с другими продуктами.
Основным недостатком этого подхода является избыточность. Хотя средства мультиплексирования обычно позволяют загружать и выгружать по желанию пользователя различные стеки протоколов, но если нужно одновременно работать с тремя различными сетями, то в каждую рабочую станцию необходимо загрузить все три стека одновременно.
Шлюз по своей природе является выделенным сервисом, разделяемым всеми источниками запросов к серверам другой сети. Использование шлюзов обеспечивает следующие преимущества:
Позволяет сосредоточить все функции согласования протоколов в одном месте и разгрузить рабочие станции от дополнительного программного обеспечения, а их пользователей - от необходимости его генерации. Шлюз сохраняет в локальной сети ее родную среду протоколов, что повышает производительность, так как стек протоколов был специально спроектирован для данной операционной среды и наилучшим образом учитывает ее особенности.
Возникающие проблемы легко локализуются.
Обслуживающий персонал работает в привычной среде, где можно использовать имеющийся опыт по поддержанию сети. Шлюзы сохраняют различные, несовместимые сети в их первозданном виде. Если имеется несколько различных сетей, то для их совместной работы может понадобиться значительное количество шлюзов. Для доступа пользователей сети UNIX к мейнфрейму понадобится шлюз UNIX-SNA, для подключения пользователей NetWare к компьютерам UNIX и мейнфрейму нужно два шлюза - NetWare-UNIX и NetWare-SNA.
Недостатки использования шлюзов:
Шлюзы работают, как правило, медленно; пользователи замечают уменьшение производительности при обращении к другой сети через шлюз.
Шлюз как централизованное средство понижает надежность сети.
Средства аппаратной поддержки
Процессоры Intel 80386, 80486 и Pentium с точки зрения рассматриваемых в данном разделе вопросов имеют аналогичные средства, поэтому для краткости в тексте используется термин "процессор i386", хотя вся информация этого раздела в равной степени относится к трем моделям процессоров фирмы Intel.
Процессор i386 имеет два режима работы - реальный (real mode) и защищенный (protected mode). В реальном режиме процессор i386 работает как быстрый процессор 8086 с несколько расширенным набором команд. В защищенном режиме процессор i386 может использовать все механизмы 32-х разрядной организации памяти, в том числе механизмы поддержки виртуальной памяти и механизмы переключения задач. Кроме этого, в защищенном режиме для каждой задачи процессор i386 может эмулировать 86 и 286 процессоры, которые в этом случае называются виртуальными процессорами. Таким образом, при многозадачной работе в защищенном режиме процессор i386 работает как несколько виртуальных процессоров, имеющих общую память. В отличие от реального режима, режим виртуального процессора i86, который называется в этом случае режимом V86, поддерживает страничную организацию памяти и средства многозадачности. Поэтому задачи, выполняющиеся в режиме V86, используют те же средства межзадачной защиты и защиты ОС от пользовательских задач, что и задачи, работающие в защищенном режиме i386. Однако максимальный размер виртуального адресного пространства составляет 1 Мб, как и у процессора i86.
Переключение процессора i386 из реального режима в защищенный и обратно осуществляется просто путем выполнения команды MOV, которая изменяет бит режима в одном из управляющих регистров процессора. Переход процессора в режим V86 происходит похожим образом путем изменения значения определенного бита в другом регистре процессора.
Средства BackOffice
Компания Microsoft объединяет под названием BackOffice набор своих серверов: сервер Windows NT Server, составляющий основу для построения остальных специализированных серверов: сервера баз данных Microsoft SQL Server, почтового сервера Microsoft Mail Server и сервера интегрированной службы обработки сообщений Microsoft Exchange, шлюз к SNA-сетям Microsoft SNA Server и сервер управления вычислительной системой Microsoft System Management Server. Все эти продукты хорошо работают вместе, образуя интегрированную и управляемую систему специализированных серверов офиса. В этой интегрированной среде можно построить приложения модели клиент-сервер практически любого масштаба, используя серверные возможности базы данных, почты, средств организации групповой работы.
Средства OLE
Для пользователей Windows объектно-ориентированный подход проявляется при работе с программами, использующими технологию OLE фирмы Microsoft. В первой версии OLE, которая дебютировала в Windows 3.1, пользователи могли вставлять объекты в документы-клиенты. Такие объекты устанавливали ссылку на данные (в случае связывания) или содержали данные (в случае внедрения) в формате, распознаваемом программой-сервером. Для запуска программы-сервера пользователи делали двойной щелчок на объекте, посредством чего передавали данные серверу для редактирования. OLE 2.0, доступная в настоящее время в качестве расширения Windows 3.1, переопределяет документ-клиент как контейнер. Когда пользователь щелкает дважды над объектом OLE 2.0, вставленным в документ-контейнер, он активизируется в том же самом месте. Представим, например, что контейнером является документ Microsoft Word 6.0, а вставленный объект представляет собой набор ячеек в формате Excel 5.0. Когда вы щелкнете дважды над объектом электронной таблицы, меню и управляющие элементы Word как по волшебству поменяются на меню Excel. В результате, пока объект электронной таблицы находится в фокусе, текстовый процессор становится электронной таблицей.
Инфраструктура, требуемая для обеспечения столь сложных взаимодействий объектов, настолько обширна, что Microsoft называет OLE 2.0 "1/3 операционной системы". Хранение объектов, например, использует docfile, который в действительности является миниатюрной файловой системой, содержащейся внутри обычного файла MS-DOS. Docfile имеет свои собственные внутренние механизмы для семантики подкаталогов, блокировок и транзакций (т.е. фиксации-отката).
Наиболее заметный недостаток OLE - отсутствие сетевой поддержки, и это будет иметь наивысший приоритет при разработке будущих версий OLE. Следующая основная итерация OLE появится в распределенной, объектной версии Windows, называемой Cairo (Каир), ожидаемой в 1995 году.
Средства поддержки сегментации памяти
Физическое адресное пространство процессора i386 составляет 4 Гбайта, что определяется 32-разрядной шиной адреса. Физическая память является линейной с адресами от 00000000 до FFFFFFFF в шестнадцатеричном представлении. Виртуальный адрес, используемый в программе, представляет собой пару - номер сегмента и смещение внутри сегмента. Смещение хранится в соответствующем поле команды, а номер сегмента - в одном из шести сегментных регистров процессора (CS, SS, DS, ES, FS или GS), каждый из которых является 16-битным. Средства сегментации образуют верхний уровень средств управления виртуальной памятью процессора i386, а средства страничной организации - нижний уровень. Средства страничной организации могут быть как включены, так и выключены (за счет установки определенного бита в управляющем регистре процессора), и в зависимости от этого изменяется смысл преобразования виртуального адреса, которое выполняют средства сегментации. Сначала рассмотрим случай работы средств сегментации при отключенном механизме управления страницами.
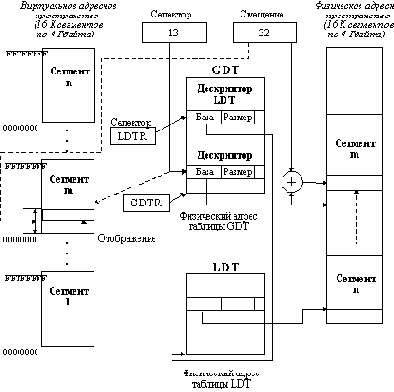
Рис. 2.19. Поддержка сегментов
На рисунке 2.19 показано виртуальное адресное пространство процессора i386 при отключенном механизме управления страницами. 32-битное смещение определяет размер виртуального сегмента в 232=4 Гбайта, а количество сегментов определяется размером поля, отведенного в сегментном регистре под номер сегмента. На рисунке 2.20,а показана структура данных в сегментном регистре. Эта структура называется селектором, так как предназначена для выбора дескриптора определенного сегмента из таблиц дескрипторов сегментов. Дескриптор сегмента описывает все характеристики сегмента, необходимые для проверки правильности доступа к нему и нахождения его в физическом адресном пространстве. Процессор i386 поддерживает две таблицы дескрипторов сегментов - глобальную (Global Descriptor Table, GDT) и локальную (Local Descriptor Table, LDT). Глобальная таблица предназначена для описания сегментов операционной системы и сегментов межзадачного взаимодействия, то есть сегментов, которые в принципе могут использоваться всеми процессами, а локальная таблица - для сегментов отдельных задач.
Таблица GDT одна, а таблиц LDT должно быть столько, сколько в системе выполняется задач. При этом активной в каждый момент времени может быть только одна из таблиц LDT.
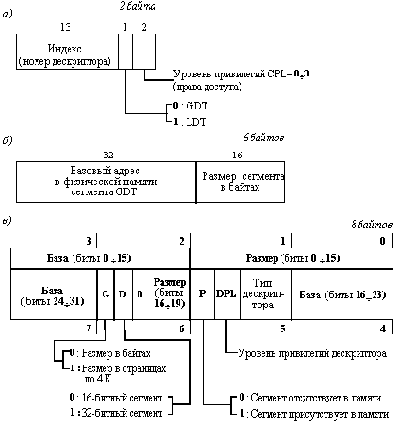
Рис. 2.20. Форматы селектора и дескрипторов данных и кода:
а - формат селектора; б - формат регистра GDTR;
в - формат дескриптора сегмента данных или кода
Из рисунка 2.20 видно, что селектор состоит из трех полей - 13-битного поля индекса (номера сегмента) в таблицах GDT и LDT, 1-битного поля - указателя типа используемой таблицы дескрипторов и двухбитного поля текущих прав доступа задачи - CPL. Разрядность поля индекса определяет максимальное число глобальных и локальных сегментов задачи - по 8K (213) сегментов каждого типа, всего 16 K. С учетом максимального размера сегмента - 4 Гбайта - каждая задача при чисто сегментной организации виртуальной памяти работает в виртуальном адресном пространстве в 64 Тбайта.
Теперь проследим, как виртуальное пространство отображается на физическое пространство размером в 4 Гбайта при чисто сегментном механизме отображения. Итак, когда задаче необходимо получить доступ к ячейке физической памяти, то для выбора дескриптора виртуального сегмента используется значение селектора из соответствующего (в зависимости от команды и стадии ее выполнения - выборка кода команды или данных) сегментного регистра процессора. Значение поля типа таблицы указывает на то, какую таблицу нужно использовать - GDT или LDT. Рассмотрим сначала случай использования таблицы GDT. Для хранения таблиц GDT и LDT используется оперативная память (использование быстрой ассоциативной памяти процессора для хранения элементов этих таблиц рассмотрим позже). Для того, чтобы процессор смог найти в физической памяти таблицу GDT, ее полный 32-битный физический адрес (адрес начала таблицы), а также размер (поле в 16 бит) хранятся в специальном регистре процессора GDTR (рисунок 2.20, б). Каждый дескриптор в таблицах GDT и LDT имеет размер 8 байт, поэтому максимальный размер этих таблиц - 64 К (8(8 К дескрипторов).
Для извлечения нужного дескриптора из таблицы процессор складывает базовый адрес таблицы GDT из регистра GDTR со сдвинутым на 3 разряда влево (умножение на 8, в соответствии с числом байтов в элементе таблицы GDT) значением поля индекса из сегментного регистра и получает физический линейный адрес нужного дескриптора в физической памяти. Таблица GDT постоянно присутствует в физической памяти, поэтому процессор извлекает по этому адресу нужный дескриптор сегмента и помещает его во внутренний (программно недоступный) регистр процессора. (Таких регистров шесть и каждый из них соответствует определенному сегментному регистру, что значительно ускоряет работу процессора).
Дескриптор виртуального сегмента (рисунок 2.20,в) состоит из нескольких полей, основными из которых являются поле базы - базового 32-разрядного физического адреса начала сегмента, поле размера сегмента и поле прав доступа к сегменту - DPL (Descriptor Privilege Level). Сначала процессор определяет правильность адреса, сравнивая смещение и размер сегмента (в случае выхода за границы сегмента происходит прерывание типа исключение - exсeption). Потом процессор проверяет права доступа задачи к данному сегменту, сравнивая значения полей CPL селектора и DPL дескриптора сегмента. В процессоре i386 мандатный способ определения прав доступа (называемый также механизмом колец защиты), при котором имеется несколько уровней прав доступа, и объекты какого-либо уровня имеют доступ ко всем объектам равного уровня или более низких уровней, но не имеет доступа к объектам более высоких уровней. В процессоре i386 существует четыре уровня прав доступа - от 0-го, который является самым высоким, до 3-го - самого низкого. Очевидно, что операционная система может использовать механизм уровней защиты по своему усмотрению. Однако предполагается, что нулевой уровень будет использован для ядра операционной системы, а третий уровень - для прикладных программ, промежуточные уровни - для утилит и подсистем операционной системы, менее привилегированных, чем ядро.
Таким образом, доступ к виртуальному сегменту считается законным, если уровень прав селектора CPL выше или равен уровню прав сегмента DPL (CPL ( DPL). При нарушении прав доступа происходит прерывание, как и в случае несоблюдения границ сегмента. Далее проверяется наличие сегмента в физической памяти по значению бита P дескриптора, и если сегмент отсутствует в физической памяти, то происходит прерывание. При наличии сегмента в памяти вычисляется физический линейный адрес путем сложения базы сегмента и смещения и производится доступ к элементу физической памяти по этому адресу.
В случае, когда селектор указывает на таблицу LDT, виртуальный адрес преобразуется в физический аналогичным образом, но для доступа к самой таблице LDT добавляется еще один этап, так как в процессоре регистр LDTR указывает на размещение таблицы LDT не прямо, а косвенно. Сам регистр LDTR имеет размер 16 бит и содержит селектор дескриптора таблицы GDT, который описывает расположение этой таблицы в физической памяти. Поэтому при доступе к элементу физической памяти через таблицу LDT происходит двукратное преобразование виртуального адреса в физический, причем оба раза по описанной выше схеме. Сначала по значению селектора LDTR определяется физический адрес дескриптора из таблицы GDT, описывающего начало расположения таблицы LDT в физической памяти, а затем с помощью селектора задачи вычисляется смещение в таблице LDT и определяется физический адрес нужного дескриптора. Далее процесс аналогичен преобразованию виртуального адреса с помощью таблицы GDT.

Рис. 2.21. Типы дескрипторов
Дескриптор сегмента содержит еще несколько полей. Однобитное поле G определяет единицу измерения размера сегмента, при G = 0 размер определяется в байтах, и тогда сегмент не может быть больше 64 К, а при G = 1 размер определяется в 4К-байтных страницах, при этом максимальный размер сегмента достигает указанных 4 Гбайт. Поле D определяет тип адресации сегмента: при D = 0 сегмент является 16-битным (для режима эмуляции 16-битных процессоров i86 и i286), а при D = 1 сегмент является 32-битным.Кроме этого в дескрипторе имеется поле типа сегмента, которое в свою очередь делится на несколько полей (рисунок 2.21). Поле S определяет, является ли сегмент системным (S = 1) или пользовательским (S = 0). В свою очередь пользовательские сегменты делятся на сегменты данных (E=0) и сегменты кода (E=1). Для сегмента данных определяются однобитные поля:
Средства вызова подпрограмм и задач
Операционная система, как однозадачная, так и многозадачная, должна предоставлять задачам средства вызова подпрограмм операционной системы, библиотечных подпрограмм, а также иметь средства для запуска задач, а при многозадачной работе средства быстрого переключения с задачи на задачу. Вызов подпрограммы отличается от запуска задачи тем, что в первом случае адресное пространство остается тем же (таблица LDT остается прежней), а при вызове задачи адресное пространство полностью меняется.
Вызов подпрограмм без смены кодового сегмента в защищенном режиме процессора i386 производится аналогично вызову в реальном режиме с помощью команд JMP и CALL.
Для вызова подпрограммы, код которой находится в другом сегменте (который может принадлежать библиотеке, другой задаче или операционной системе), процессор i386 предоставляет 2 варианта вызова, причем оба используют защиту с помощью прав доступа.
Первый способ состоит в непосредственном указании в поле команды JMP или CALL селектора сегмента, содержащего код вызываемой подпрограммы, а также смещение в этом сегменте адреса начала подпрограммы.
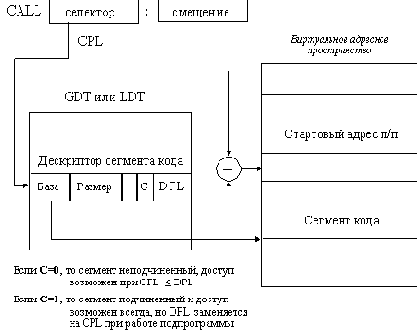
Рис. 2.25. Непосредственный вызов подпрограммы
Схема такого вызова приведена на рисунке 2.25. Здесь и далее показан только этап получения линейного адреса в виртуальном пространстве, а следующий этап (подразумевается, что механизм поддержки страниц включен) преобразования этого адреса в номер физической страницы опущен, так как он не содержит ничего специфического по сравнению с доступом к сегменту данных, рассмотренному выше. Разрешение вызова происходит в зависимости от значения поля C в дескрипторе сегмента вызываемого кода. При C=0 вызываемый сегмент не считается подчиненным, и вызов разрешается, только если уровень прав вызывающего кода не меньше уровня прав вызываемого сегмента. При C=1 вызываемый сегмент считается подчиненным и допускает вызов из кода с любым уровнем прав доступа, но при выполнении подпрограмма наделяется уровнем прав вызвавшего кода.
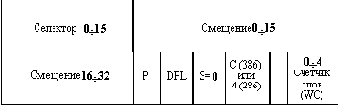
Рис. 2.26. Формат дескриптора шлюза вызова подпрограммы
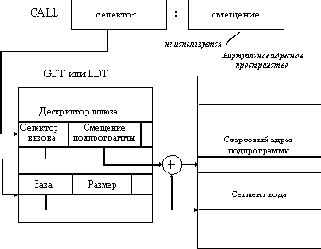
Рис. 2.27. Вызов подпрограммы через шлюз вызова
Очевидно, что первый способ непригоден для вызова функций операционной системы, имеющей обычно нулевой уровень прав, из пользовательской программы, работающей, как правило, на третьем уровне. Поэтому процессор i386 предоставляет другой способ вызова подпрограмм, основанный на том, что заранее определяется набор точек входа в привилегированные кодовые сегменты, и эти точки входа описываются с помощью специальных дескрипторов - дескрипторов шлюзов вызова подпрограмм. Этот дескриптор принадлежит к системным дескрипторам, и его структура отличается от структуры дескрипторов сегментов кода и данных (рисунок 2.26). Схема его использования приведена на рисунке 2.27. Селектор из поля команды CALL используется для указания на дескриптор шлюза вызова подпрограммы в таблицах GDT или LDT. Для использования этого дескриптора вызывающий код должен иметь не меньший уровень прав, чем дескриптор, но если дескриптор шлюза доступен, то он может указывать на дескриптор сегмента вызываемого кода, имеющий более высокий уровень, чем имеет шлюз, и вызов при этом произойдет. При определении адреса входа в вызываемом сегменте смещение из поля команды CALL не используется, а используется смещение из дескриптора шлюза, что не дает возможности задаче самой определять точку входа в защищенный кодовый сегмент.
При вызове кодов, обладающих различными уровнями привилегий, возникает проблема передачи параметров между различными стеками, так как для надежной защиты задачи различного уровня привилегий имеют различные сегменты стеков. Селекторы этих сегментов хранятся в контексте задачи - сегменте TSS (Task State Segment). Если вызывается подпрограмма, имеющая другой уровень привилегий, то из текущего стека в стек уровня доступа вызываемого сегмента копируется столько 32-разрядных слов, сколько указано в поле счетчика слов дескриптора шлюза.
Структура сегмента TSS задачи приведена на рисунке 2.28. Контекст задачи должен содержать все данные для того, чтобы можно было восстановить выполнение прерванной в произвольный момент времени задачи, то есть значения регистров процессора, указатели на открытые файлы и некоторые другие, зависящие от операционной системы, переменные.
Скорость переключения контекста в значительной степени влияет на скоростные качества многозадачной операционной системы. Процессор i386 производит аппаратное переключение контекста задачи, хранящегося в сегменте TSS. Как видно из рисунка, сегмент TSS имеет фиксированные поля, отведенные для значений регистров процессора, как универсальных, так и некоторых управляющих (например LDTR и CR3). Для описания возможностей доступа задачи к портам ввода-вывода процессор использует в защищенном режиме поле IOPL (Input/Output Privilege Level) в своем регистре EFLAGS и карту битовых полей доступа к портам. Для получения возможности выполнять команды ввода-вывода выполняемый код должен иметь уровень прав не ниже значения поля IOPL. Если же это условие соблюдается, то возможность доступа к порту с конкретным адресом определяется значением соответствующего бита в карте ввода-вывода сегмента TSS (карта состоит из 64 Кбит для описания доступа к 65536 портам).
Битовая карта ввода/вывода (БКВВ) (
(8 Кбайт
Дополнительная информация ОС
Относительный адрес БККВ0
