Работа на платформе
Работа на платформе PowerPC
Общие органы управления и панели диалога с Windows 95
Новый пользовательский интерфейс
Вытесняющая многозадачность
Многонитевость
Защита памяти
Поддержка службы Microsoft Network
Win32 API
Поддержка службы Microsoft
Поддержка службы Microsoft Network
Пользовательский интерфейс Windows 95
Незначительно улучшенная версия
Windows 95
Последняя основная версия обычной
Объектно-ориентированная архитектура
Объектно-ориентированная файловая система
Сетевые средства OLE
Служба каталогов
Встроенные сетевые средства ATM
Аутентификация с помощью службы Kerberos
Последняя основная версия обычной Windows
унифицированная ОС для всех
Единая, унифицированная ОС для всех пользователей
A
- поле доступа к сегменту (1 означает, что после очистки этого поля к сегменту было обращение по чтению или записи, это поле может использоваться операционной системой в ее стратегии замены страниц в оперативной памяти).
Для сегмента кода используются однобитные признаки:
- имеет смысл, аналогичный полю A сегмента данных,
A. Уменьшение требований к оперативной памяти и повышение производительности ядра
Одной из важнейших особенностей UNIX SVR4.2 является возможность эффективно работать на ЭВМ с процессором 386SX и 6 MБ оперативной памяти. Эта возможность появилась в результате работы, направленной на уменьшение размера и увеличение скорости важнейших программных компонентов системы, включая ядро и средства графики. Была проделана работа по улучшению программ загрузчика системы и закрытия системы, а также и драйверов устройств SCSI.
Изменения в структуре ОС и повышение производительности снизили минимальные требования к оперативной памяти на 30%. Преимущества UNIX SVR4.2 по требованиям к объему оперативной памяти еще более заметны по сравнению с системами с аналогичными возможностями. Так, для работы ПО Solaris фирмы SUN требуется минимум 12 МБ памяти, причем для нормальной работы SUN рекомендует использовать 16 МБ ОЗУ.
В ОС UNIX SVR4.2 производительность при нормальной загрузке, при "грязной" загрузке после неаккуратного закрытия, а также при закрытии системы значительно увеличилась по сравнению с предыдущими версиями. В частности, время закрытия системы сократилось на 58% (с 38 до 17 секунд) на типичной аппаратной конфигурации ЭВМ. Загрузка системы при нормальных условиях эквивалентна физическому включению машины после аккуратного закрытия. Время нормальной загрузки сократилось на 48% (с 65 до 38 секунд). При "грязной" загрузке эти времена составляют соответственно 140 и 40 секунд (71%).
которая расширяла функциональные возможности операционной
, которая расширяла функциональные возможности операционной системы сервера
Алгоритм планирования процессов и нитей
В Windows NT реализована вытесняющая многозадачность, при которой операционная система не ждет, когда нить сама захочет освободить процессор, а принудительно снимает ее с выполнения после того, как та израсходовала отведенное ей время (квант), или если в очереди готовых появилась нить с более высоким приоритетом. При такой организации разделения процессора ни одна нить не займет процессор на очень долгое время.

Рис. 8.3. Граф состояний нити
В ОС Windows NT нить в ходе своего существования может иметь одно из шести состояний (рисунок 8.3). Жизненный цикл нити начинается в тот момент, когда программа создает новую нить. Запрос передается NT executive, менеджер процессов выделяет память для объекта-нити и обращается к ядру, чтобы инициализировать объект-нить ядра. После инициализации нить проходит через следующие состояния:
Готовность. При поиске нити на выполнение диспетчер просматривает только нити, находящиеся в состоянии готовности, у которых есть все для выполнения, но не хватает только процессора.
Первоочередная готовность (standby). Для каждого процессора системы выбирается одна нить, которая будет выполняться следующей (самая первая нить в очереди). Когда условия позволяют, происходит переключение на контекст этой нити.
Выполнение. Как только происходит переключение контекстов, нить переходит в состояние выполнения и находится в нем до тех пор, пока либо ядро не вытеснит ее из-за того, что появилась более приоритетная нить или закончился квант времени, выделенный этой нити, либо нить завершится вообще, либо она по собственной инициативе перейдет в состояние ожидания.
Ожидание. Нить может входить в состояние ожидания несколькими способами: нить по своей инициативе ожидает некоторый объект для того, чтобы синхронизировать свое выполнение; операционная система (например, подсистема ввода-вывода) может ожидать в интересах нити; подсистема окружения может непосредственно заставить нить приостановить себя. Когда ожидание нити подойдет к концу, она возвращается в состояние готовности.
Переходное состояние. Нить входит в переходное состояние, если она готова к выполнению, но ресурсы, которые ей нужны, заняты. Например, страница, содержащая стек нити, может быть выгружена из оперативной памяти на диск. При освобождении ресурсов нить переходит в состояние готовности.
Завершение. Когда выполнение нити закончилось, она входит в состояние завершения. Находясь в этом состоянии, нить может быть либо удалена, либо не удалена. Это зависит от алгоритма работы менеджера объектов, в соответствии с которым он и решает, когда удалять объект. Если executive имеет указатель на объект-нить, то она может быть инициализирована и использована снова.
Диспетчер ядра использует для определения порядка выполнения нитей алгоритм, основанный на приоритетах, в соответствии с которым каждой нити присваивается число - приоритет, и нити с более высоким приоритетом выполняются раньше нитей с меньшим приоритетом. В самом начале нить получает приоритет от процесса, который создает ее. В свою очередь, процесс получает приоритет в тот момент, когда его создает подсистема той или иной прикладной среды. Значение базового приоритета присваивается процессу системой по умолчанию или системным администратором. Нить наследует этот базовый приоритет и может изменить его, немного увеличив или уменьшив. На основании получившегося в результате приоритета, называемого приоритетом планирования, начинается выполнение нити. В ходе выполнения приоритет планирования может меняться.
Windows NT поддерживает 32 уровня приоритетов, разделенных на два класса - класс реального времени и класс переменных приоритетов. Нити реального времени, приоритеты которых находятся в диапазоне от 16 до 31, являются более приоритетными процессами и используются для выполнения задач, критичных ко времени.
Каждый раз, когда необходимо выбрать нить для выполнения, диспетчер прежде всего просматривает очередь готовых нитей реального времени и обращается к другим нитям, только когда очередь нитей реального времени пуста.
Большинство нитей в системе попадают в класс нитей с переменными приоритетами, диапазон приоритетов которых от 0 до 15. Этот класс имеет название "переменные приоритеты" потому, что диспетчер настраивает систему, выбирая (понижая или повышая) приоритеты нитей этого класса.
Алгоритм планирования нитей в Windows NT объединяет в себе обе базовых концепции - квантование и приоритеты. Как и во всех других алгоритмах, основанных на квантовании, каждой нити назначается квант, в течение которого она может выполняться. Нить освобождает процессор, если:
блокируется, уходя в состояние ожидания;
завершается;
исчерпан квант;
в очереди готовых появляется более приоритетная нить.
Использование динамических приоритетов, изменяющихся во времени, позволяет реализовать адаптивное планирование, при котором не дискриминируются интерактивные задачи, часто выполняющие операции ввода-вывода и недоиспользующие выделенные им кванты. Если нить полностью исчерпала свой квант, то ее приоритет понижается на некоторую величину. В то же время приоритет нитей, которые перешли в состояние ожидания, не использовав полностью выделенный им квант, повышается. Приоритет не изменяется, если нить вытеснена более приоритетной нитью.
Для того, чтобы обеспечить хорошее время реакции системы, алгоритм планирования использует наряду с квантованием концепцию абсолютных приоритетов. В соответствии с этой концепцией при появлении в очереди готовых нитей такой, у которой приоритет выше, чем у выполняющейся в данный момент, происходит смена активной нити на нить с самым высоким приоритетом.
В многопроцессорных системах при диспетчеризации и планировании нитей играет роль их процессорная совместимость: после того, как ядро выбрало нить с наивысшим приоритетом, оно проверяет, какой процессор может выполнить данную нить и, если атрибут нити "процессорная совместимость" не позволяет нити выполняться ни на одном из свободных процессоров, то выбирается следующая в порядке приоритетов нить.
Алгоритм синхронизации логических часов
В централизованной однопроцессорной системе, как правило, важно только относительное время и не важна точность часов. В распределенной системе, где каждый процессор имеет собственные часы со своей точностью хода, ситуация резко меняется: программы, использующие время (например, программы, подобные команде make в UNIX, которые используют время создания файлов, или программы, для которых важно время прибытия сообщений и т.п.) становятся зависимыми от того, часами какого компьютера они пользуются. В распределенных системах синхронизация физических часов (показывающих реальное время) является сложной проблемой, но с другой стороны очень часто в этом нет никакой необходимости: то есть процессам не нужно, чтобы во всех машинах было правильное время, для них важно, чтобы оно было везде одинаковое, более того, для некоторых процессов важен только правильный порядок событий. В этом случае мы имеем дело с логическими часами.
Введем для двух произвольных событий отношение "случилось до". Выражение a ® b читается "a случилось до b" и означает, что все процессы в системе считают, что сначала произошло событие a, а потом - событие b. Отношение "случилось до" обладает свойством транзитивности: если выражения a ® b и b ® c истинны, то справедливо и выражение a ® c. Для двух событий одного и того же процесса всегда можно установить отношение "случилось до", аналогично может быть установлено это отношение и для событий передачи сообщения одним процессом и приемом его другим, так как прием не может произойти раньше отправки. Однако, если два произвольных события случились в разных процессах на разных машинах, и эти процессы не имеют между собой никакой связи (даже косвенной через третьи процессы), то нельзя сказать с полной определенностью, какое из событий произошло раньше, а какое позже.
Ставится задача создания такого механизма ведения времени, который бы для каждого события а мог указать значение времени Т(а), с которым бы были согласны все процессы в системе.
При этом должно выполняться условие: если а ® b , то Т(а) < Т(b). Кроме того, время может только увеличиваться и, следовательно, любые корректировки времени могут выполняться только путем добавления положительных значений, и никогда - путем вычитания.
Рассмотрим алгоритм решения этой задачи, который предложил Lamport. Для отметок времени в нем используются события. На рисунке 3.6 показаны три процесса, выполняющихся на разных машинах, каждая из которых имеет свои часы, идущие со своей скоростью. Как видно из рисунка, когда часы процесса 0 показали время 6, в процессе 1 часы показывали 8, а в процессе 2 - 10. Предполагается, что все эти часы идут с постоянной для себя скоростью.
В момент времени 6 процесс 0 посылает сообщение А процессу 1. Это сообщение приходит к процессу 1 в момент времени 16 по его часам. В логическом смысле это вполне возможно, так как 6<16. Аналогично, сообщение В, посланное процессом 1 процессу 2 пришло к последнему в момент времени 40, то есть его передача заняла 16 единиц времени, что также является правдоподобным.
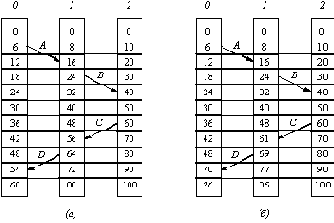
Рис. 3.6. Синхронизация логических часов
а - три процесса, каждый со своими собственными часами;
б - алгоритм синхронизации логических часов
Ну а далее начинаются весьма странные вещи. Сообщение С от процесса 2 к процессу 1 было отправлено в момент времени 64, а поступило в место назначения в момент времени 54. Очевидно, что это невозможно. Такие ситуации необходимо предотвращать. Решение Lamport'а вытекает непосредственно из отношений "случилось до". Так как С было отправлено в момент 60, то оно должно дойти в момент 61 или позже. Следовательно, каждое сообщение должно нести с собой время своего отправления по часам машины-отправителя. Если в машине, получившей сообщение, часы показывают время, которое меньше времени отправления, то эти часы переводятся вперед, так, чтобы они показали время, большее времени отправления сообщения. На рисунке 3.6,б видно, что С поступило в момент 61, а сообщение D - в 70.
Этот алгоритм удовлетворяет сформулированным выше требованиям.
Алгоритм Token Ring
Совершенно другой подход к достижению взаимного исключения в распределенных системах иллюстрируется рисунком 3.7. Все процессы системы образуют логическое кольцо, т.е. каждый процесс знает номер своей позиции в кольце, а также номер ближайшего к нему следующего процесса. Когда кольцо инициализируется, процессу 0 передается так называемый токен. Токен циркулирует по кольцу. Он переходит от процесса n к процессу n+1 путем передачи сообщения по типу "точка-точка". Когда процесс получает токен от своего соседа, он анализирует, не требуется ли ему самому войти в критическую секцию. Если да, то процесс входит в критическую секцию. После того, как процесс выйдет из критической секции, он передает токен дальше по кольцу. Если же процесс, принявший токен от своего соседа, не заинтересован во вхождении в критическую секцию, то он сразу отправляет токен в кольцо. Следовательно, если ни один из процессов не желает входить в критическую секцию, то в этом случае токен просто циркулирует по кольцу с высокой скоростью.
Сравним эти три алгоритма взаимного исключения. Централизованный алгоритм является наиболее простым и наиболее эффективным. При его использовании требуется только три сообщения для того, чтобы процесс вошел и покинул критическую секцию: запрос и сообщение-разрешение для входа и сообщение об освобождении ресурса при выходе. При использовании распределенного алгоритма для одного использования критической секции требуется послать (n-1) сообщений-запросов (где n - число процессов) - по одному на каждый процесс и получить (n-1) сообщений-разрешений, то есть всего необходимо 2(n-1) сообщений. В алгоритме Token Ring число сообщений переменно: от 1 в случае, если каждый процесс входил в критическую секцию, до бесконечно большого числа, при циркуляции токена по кольцу, в котором ни один процесс не входил в критическую секцию.
К сожалению все эти три алгоритма плохо защищены от отказов. В первом случае к краху приводит отказ координатора, во втором - отказ любого процесса (парадоксально, но распределенный алгоритм оказывается менее отказоустойчивым, чем централизованный), а в третьем - потеря токена или отказ процесса.
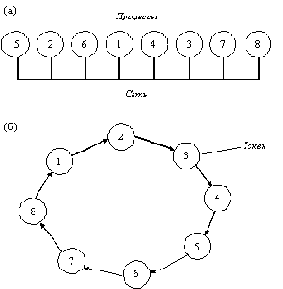
Рис. 3.7. Средства взаимного исключения в распределенных системах
а - неупорядоченная группа процессов в сети;
б - логическое кольцо, образованное программным обеспечением
Алгоритмы планирования процессов
Планирование процессов включает в себя решение следующих задач:
определение момента времени для смены выполняемого процесса;
выбор процесса на выполнение из очереди готовых процессов;
переключение контекстов "старого" и "нового" процессов.
Первые две задачи решаются программными средствами, а последняя в значительной степени аппаратно (см. раздел 2.3. "Средства аппаратной поддержки управления памятью и многозадачной среды в микропроцессорах Intel 80386, 80486 и Pentium").
Существует множество различных алгоритмов планирования процессов, по разному решающих вышеперечисленные задачи, преследующих различные цели и обеспечивающих различное качество мультипрограммирования. Среди этого множества алгоритмов рассмотрим подробнее две группы наиболее часто встречающихся алгоритмов: алгоритмы, основанные на квантовании, и алгоритмы, основанные на приоритетах.
В соответствии с алгоритмами, основанными на квантовании, смена активного процесса происходит, если:
процесс завершился и покинул систему,
произошла ошибка,
процесс перешел в состояние ОЖИДАНИЕ,
исчерпан квант процессорного времени, отведенный данному процессу.
Процесс, который исчерпал свой квант, переводится в состояние ГОТОВНОСТЬ и ожидает, когда ему будет предоставлен новый квант процессорного времени, а на выполнение в соответствии с определенным правилом выбирается новый процесс из очереди готовых. Таким образом, ни один процесс не занимает процессор надолго, поэтому квантование широко используется в системах разделения времени. Граф состояний процесса, изображенный на рисунке 2.1, соответствует алгоритму планирования, основанному на квантовании.
Кванты, выделяемые процессам, могут быть одинаковыми для всех процессов или различными. Кванты, выделяемые одному процессу, могут быть фиксированной величины или изменяться в разные периоды жизни процесса. Процессы, которые не полностью использовали выделенный им квант (например, из-за ухода на выполнение операций ввода-вывода), могут получить или не получить компенсацию в виде привилегий при последующем обслуживании.
По разному может быть организована очередь готовых процессов: циклически, по правилу "первый пришел - первый обслужился" (FIFO) или по правилу "последний пришел - первый обслужился" (LIFO).
Другая группа алгоритмов использует понятие "приоритет" процесса. Приоритет - это число, характеризующее степень привилегированности процесса при использовании ресурсов вычислительной машины, в частности, процессорного времени: чем выше приоритет, тем выше привилегии.
Приоритет может выражаться целыми или дробными, положительным или отрицательным значением.Чем выше привилегии процесса, тем меньше времени он будет проводить в очередях. Приоритет может назначаться директивно администратором системы в зависимости от важности работы или внесенной платы, либо вычисляться самой ОС по определенным правилам, он может оставаться фиксированным на протяжении всей жизни процесса либо изменяться во времени в соответствии с некоторым законом. В последнем случае приоритеты называются динамическими.
Существует две разновидности приоритетных алгоритмов: алгоритмы, использующие относительные приоритеты, и алгоритмы, использующие абсолютные приоритеты.
В обоих случаях выбор процесса на выполнение из очереди готовых осуществляется одинаково: выбирается процесс, имеющий наивысший приоритет. По разному решается проблема определения момента смены активного процесса. В системах с относительными приоритетами активный процесс выполняется до тех пор, пока он сам не покинет процессор, перейдя в состояние ОЖИДАНИЕ (или же произойдет ошибка, или процесс завершится). В системах с абсолютными приоритетами выполнение активного процесса прерывается еще при одном условии: если в очереди готовых процессов появился процесс, приоритет которого выше приоритета активного процесса. В этом случае прерванный процесс переходит в состояние готовности. На рисунке 2.2 показаны графы состояний процесса для алгоритмов с относительными (а) и абсолютными (б) приоритетами.
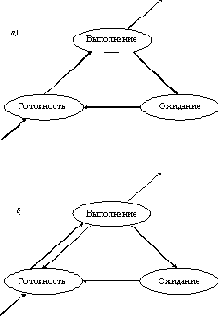
Рис. 2.2. Графы состояний процессов в системах
(а) с относительными приоритетами; (б)с абсолютными приоритетами
Во многих операционных системах алгоритмы планирования построены с использованием как квантования, так и приоритетов. Например, в основе планирования лежит квантование, но величина кванта и/или порядок выбора процесса из очереди готовых определяется приоритетами процессов.
Алгоритмы взаимного исключения
Системы, состоящие из нескольких процессов, часто легче программировать, используя так называемые критические секции. Когда процессу нужно читать или модифицировать некоторые разделяемые структуры данных, он прежде всего входит в критическую секцию для того, чтобы обеспечить себе исключительное право использования этих данных, при этом он уверен, что никакой процесс не будет иметь доступа к этому ресурсу одновременно с ним. Это называется взаимным исключением. В однопроцессорных системах критические секции защищаются семафорами, мониторами и другими аналогичными конструкциями. Рассмотрим, какие алгоритмы могут быть использованы в распределенных системах.
AVL
- резерв для нужд операционной системы (available for use).
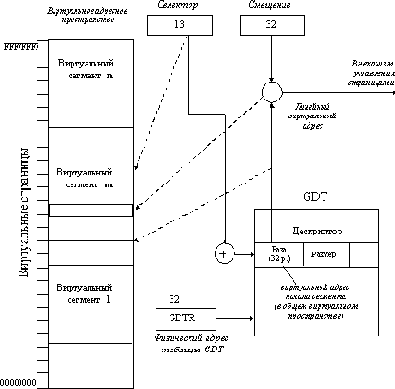
Рис. 2.22. Сегментно-страничный механизм
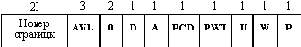
Рис. 2.23. Формат дескриптора страницы
При небольшом размере страницы процессора i386 относительно размеров адресных пространств, таблица страниц должна занимать в памяти весьма значительное место - 4 байта ( 1М = 4 Мбайта. Это слишком много для нынешних моделей персональных компьютеров, поэтому в процессоре i386 используется деление всей таблицы страниц на разделы по 1024 дескриптора. Размер раздела выбран так, чтобы один раздел занимал одну физическую страницу (1024 ( 4 байта = 4 Кбайта). Всего получается 1024 раздела (1024 ( 1024 = 1М). Для того, чтобы не хранить все разделы таблицы страниц одновременно в физической памяти, используется каталог разделов таблицы страниц, который использует такие же по структуре дескрипторы страниц, что и в таблице страниц. Поэтому для хранения информации о дескрипторах 1024 разделов необходима память 4 К, т.е. одна физическая страница. Совокупность дескрипторов, описывающих состояние и характеристики виртуальных страниц разделов таблицы страниц, называется каталогом разделов или таблиц. Виртуальная страница, хранящая содержимое каталога, всегда находится в физической памяти, и номер ее физической страницы указан в специальном управляющем регистре CR3 процессора (точнее, в одном из полей этого регистра).
Преобразование линейного виртуального адреса в физический происходит следующим образом (рисунок 2.24). Поле номера виртуальной страницы (старшие 20 разрядов) делится на две равные части по 10 разрядов - поле номера раздела и поле номера страницы в разделе. С помощью номера физической страницы, хранящей каталог и смещения в этой странице, задаваемого полем номера раздела, процессор находит дескриптор виртуальной страницы раздела. В соответствии с атрибутами этого дескриптора определяются права доступа к этой странице, а также наличие ее в физической памяти. В случае ее отсутствия происходит страничное прерывание, и операционная система должна в этом случае переместить ее в память.
После того, как нужная страница находится в памяти, для определения адреса элемента данных используется смещение, определяемое полем номера страницы линейного виртуального адреса.
Таким образом, при доступе к странице в процессоре используется двухуровневая схема адресации страниц, что замедляет преобразование, но позволяет использовать страничный механизм и для хранения самой таблицы страниц, и существенно уменьшить объем физической памяти для ее хранения. Для ускорения страничных преобразований в блоке управления страницами используется ассоциативная память, в которой кэшируется 32 комбинации "номер виртуальной страницы - номер физической страницы". Эта специальная кэш-память (дополнительная по отношению к 8 Кбайтному кэшу данных процессоров i486 и Pentium) значительно ускоряет преобразование адресов, так как в случае попадания в кэш длительный процесс, описанный выше, исключается.
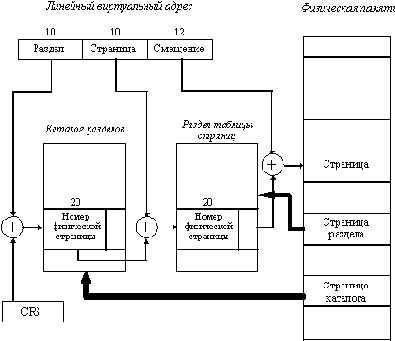
Рис. 2.24. Преобразование линейного виртуального адреса в физический адрес
Организация виртуальной памяти в процессоре i386 позволяет защитить адресные пространства различных процессов за счет двух механизмов:
Изоляция адресных пространств процессов в физической памяти путем назначения им различных физических страниц или сегментов (если страничный механизм отключен).
Защита сегментов от несанкционированного доступа с помощью привилегий четырех уровней.
B. Отказоустойчивая файловая система Veritas
В дополнение к стандартным файловым системам (BFS, UFS, S5) UnixWare поддерживает: CD-ROM File System (CDFS), NetWare UNIX Client File System (NUCFS) и Veritas Fault Resilient File System. Система Veritas, основанная на транзакционном механизме операций с файловой системой, обеспечивает не только улучшенную производительность, но и высокую устойчивость к отказам системы.
Базовые операции RPC
Чтобы понять работу RPC, рассмотрим вначале выполнение вызова локальной процедуры в обычной машине, работающей автономно. Пусть это, например, будет системный вызов
count=read (fd,buf,nbytes);
где fd - целое число,
buf - массив символов,
nbytes - целое число.
Чтобы осуществить вызов, вызывающая процедура заталкивает параметры в стек в обратном порядке (рисунок 3.1). После того, как вызов read выполнен, он помещает возвращаемое значение в регистр, перемещает адрес возврата и возвращает управление вызывающей процедуре, которая выбирает параметры из стека, возвращая его в исходное состояние. Заметим, что в языке С параметры могут вызываться или по ссылке (by name), или по значению (by value). По отношению к вызываемой процедуре параметры-значения являются инициализируемыми локальными переменными. Вызываемая процедура может изменить их, и это не повлияет на значение оригиналов этих переменных в вызывающей процедуре.
Если в вызываемую процедуру передается указатель на переменную, то изменение значения этой переменной вызываемой процедурой влечет изменение значения этой переменной и для вызывающей процедуры. Этот факт весьма существенен для RPC.
Существует также другой механизм передачи параметров, который не используется в языке С. Он называется call-by-copy/restore и состоит в необходимости копирования вызывающей программой переменных в стек в виде значений, а затем копирования назад после выполнения вызова поверх оригинальных значений вызывающей процедуры.
Решение о том, какой механизм передачи параметров использовать, принимается разработчиками языка. Иногда это зависит от типа передаваемых данных. В языке С, например, целые и другие скалярные данные всегда передаются по значению, а массивы - по ссылке.

Рис. 3.1. а) Стек до выполнения вызова read;
б) Стек во время выполнения процедуры;
в) Стек после возврата в вызывающую программу
Идея, положенная в основу RPC, состоит в том, чтобы сделать вызов удаленной процедуры выглядящим по возможности также, как и вызов локальной процедуры. Другими словами - сделать RPC прозрачным: вызывающей процедуре не требуется знать, что вызываемая процедура находится на другой машине, и наоборот.
RPC достигает прозрачности следующим путем. Когда вызываемая процедура действительно является удаленной, в библиотеку помещается вместо локальной процедуры другая версия процедуры, называемая клиентским стабом (stub - заглушка). Подобно оригинальной процедуре, стаб вызывается с использованием вызывающей последовательности (как на рисунке 3.1), так же происходит прерывание при обращении к ядру. Только в отличие от оригинальной процедуры он не помещает параметры в регистры и не запрашивает у ядра данные, вместо этого он формирует сообщение для отправки ядру удаленной машины.
Базовые примитивы передачи сообщений в распределенных системах
Единственным по-настоящему важным отличием распределенных систем от централизованных является межпроцессная взаимосвязь. В централизованных системах связь между процессами, как правило, предполагает наличие разделяемой памяти. Типичный пример - проблема "поставщик-потребитель", в этом случае один процесс пишет в разделяемый буфер, а другой - читает из него. Даже наиболее простая форма синхронизации - семафор - требует, чтобы хотя бы одно слово (переменная самого семафора) было разделяемым. В распределенных системах нет какой бы то ни было разделяемой памяти, таким образом вся природа межпроцессных коммуникаций должна быть продумана заново.
Основой этого взаимодействия может служить только передача по сети сообщений. В самом простом случае системные средства обеспечения связи могут быть сведены к двум основным системным вызовам (примитивам), один - для посылки сообщения, другой - для получения сообщения. В дальнейшем на их базе могут быть построены более мощные средства сетевых коммуникаций, такие как распределенная файловая система или вызов удаленных процедур, которые, в свою очередь, также могут служить основой для построения других сетевых сервисов.
Несмотря на концептуальную простоту этих системных вызовов - ПОСЛАТЬ и ПОЛУЧИТЬ - существуют различные варианты их реализации, от правильного выбора которых зависит эффективность работы сети. В частности, эффективность коммуникаций в сети зависит от способа задания адреса, от того, является ли системный вызов блокирующим или неблокирующим, какие выбраны способы буферизации сообщений и насколько надежным является протокол обмена сообщениями.
Безопасность
В дополнение к стандарту POSIX правительство США также определило требования компьютерной безопасности для приложений, используемых правительством. Многие из этих требований являются желаемыми свойствами для любой многопользовательской системы. Правила безопасности определяют такие свойства, как защита ресурсов одного пользователя от других и установление квот по ресурсам для предотвращения захвата одним пользователем всех системных ресурсов ( таких как память).
Обеспечение защиты информации от несанкционированного доступа является обязательной функцией сетевых операционных систем. В большинстве популярных систем гарантируется степень безопасности данных, соответствующая уровню С2 в системе стандартов США.
Основы стандартов в области безопасности были заложены "Критериями оценки надежных компьютерных систем". Этот документ, изданный в США в 1983 году национальным центром компьютерной безопасности (NCSC - National Computer Security Center), часто называют Оранжевой Книгой.
В соответствии с требованиями Оранжевой книги безопасной считается такая система, которая "посредством специальных механизмов защиты контролирует доступ к информации таким образом, что только имеющие соответствующие полномочия лица или процессы, выполняющиеся от их имени, могут получить доступ на чтение, запись, создание или удаление информации".
Иерархия уровней безопасности, приведенная в Оранжевой Книге, помечает низший уровень безопасности как D, а высший - как А.
В класс D попадают системы, оценка которых выявила их несоответствие требованиям всех других классов.
Основными свойствами, характерными для С-систем, являются: наличие подсистемы учета событий, связанных с безопасностью, и избирательный контроль доступа. Уровень С делится на 2 подуровня: уровень С1, обеспечивающий защиту данных от ошибок пользователей, но не от действий злоумышленников, и более строгий уровень С2. На уровне С2 должны присутствовать средства секретного входа, обеспечивающие идентификацию пользователей путем ввода уникального имени и пароля перед тем, как им будет разрешен доступ к системе. Избирательный контроль доступа, требуемый на этом уровне позволяет владельцу ресурса определить, кто имеет доступ к ресурсу и что он может с ним делать.
Владелец делает это путем предоставляемых прав доступа пользователю или группе пользователей. Средства учета и наблюдения (auditing) - обеспечивают возможность обнаружить и зафиксировать важные события, связанные с безопасностью, или любые попытки создать, получить доступ или удалить системные ресурсы. Защита памяти - заключается в том, что память инициализируется перед тем, как повторно используется. На этом уровне система не защищена от ошибок пользователя, но поведение его может быть проконтролировано по записям в журнале, оставленным средствами наблюдения и аудитинга.
Системы уровня В основаны на помеченных данных и распределении пользователей по категориям, то есть реализуют мандатный контроль доступа. Каждому пользователю присваивается рейтинг защиты, и он может получать доступ к данным только в соответствии с этим рейтингом. Этот уровень в отличие от уровня С защищает систему от ошибочного поведения пользователя.
Уровень А является самым высоким уровнем безопасности, он требует в дополнение ко всем требованиям уровня В выполнения формального, математически обоснованного доказательства соответствия системы требованиям безопасности.
Различные коммерческие структуры (например, банки) особо выделяют необходимость учетной службы, аналогичной той, что предлагают государственные рекомендации С2. Любая деятельность, связанная с безопасностью, может быть отслежена и тем самым учтена. Это как раз то, что требует С2 и то, что обычно нужно банкам. Однако, коммерческие пользователи, как правило, не хотят расплачиваться производительностью за повышенный уровень безопасности. А-уровень безопасности занимает своими управляющими механизмами до 90% процессорного времени. Более безопасные системы не только снижают эффективность, но и существенно ограничивают число доступных прикладных пакетов, которые соответствующим образом могут выполняться в подобной системе. Например для ОС Solaris (версия UNIX) есть несколько тысяч приложений, а для ее аналога В-уровня - только сотня.
Битва Microsoft - IBM на рынке настольных ОС
Когда бета-тестеры получили Chicago, первую публичную версию Windows 95, те, кто уже использовал OS/2, отметили чрезвычайную схожесть двух систем. Например, обе начинают работу с показа красивой заставки, а затем приглашают пользователя к работе за вместительным рабочим столом; обе системы рассматривают иконки и программы как объекты; обе используют правую кнопку мыши для управления поведением объектов; обе используют более 20 дискет для инсталляции. Пользовательский интерфейс обеих систем имеет одинаковый уровень изощренности, требования к аппаратным ресурсам компьютера похожи, и они обе основаны на использовании одинакового набора лежащих в основе системы технологий. Эти технологии включают многозадачность и многонитевость, способность выполнять DOS-программы с помощью виртуальных машин процессоров Intel 80x86, полную 32-х битную организацию.
И это не случайность. С тех пор, как IBM выпустила версию 2.0 OS/2, а Microsoft решила позиционировать Windows NT как корпоративную ОС, стала ясно видна важная брешь в линии операционных систем Microsoft, которую и заполнила IBM. Попытки Microsoft выдвинуть Windows 3.1 на ту же роль наиболее развитой ОС для настольных систем, что и OS/2, имели ограниченный успех. Аналитики считают, что корпорация Microsoft действительно хотела, чтобы Windows NT заняла на рынке то же место, что и OS/2, но OS/2 уже заняла его к тому времени, когда вышла Windows NT.
В результате Microsoft стала нести потери в объемах продаж, и, что более важно, терять твердую почву для своих операционных систем. Когда стало ясно, что Windows NT вряд ли в полной мере станет лидером настольных ОС высшего класса, маркетинговая машина Microsoft стала меньше говорить о возможностях Windows NT и начала говорить о возможностях Windows 95. Ясно, что IBM и OS/2 оказали значительное влияние на стратегию Microsoft в области операционных систем.
IBM, в свою очередь, постоянно создает здоровую конкуренцию для линии Windows. Windows 95 не сравнима с OS/2 2.2. Скорее конкурировать будут Windows 95 и OS/2 Warp 3/0.
Warp - это выстрел с дальним прицелом, направленный на вытеснение Windows. И, хотя Warp имеет некоторые исходные преимущества и как система выглядит "лучше", Windows по прежнему является надежным выбором.
Имена операционных систем могут измениться, но равновесие в битве IBM/Microsoft останется тем же. Через два года Microsoft и IBM смогут обмениваться аналогичными выстрелами в сражении Cairo - OS/2 вместо Windows 95 - Warp.
Существуют две причины - фактическая и эмоциональная - которые мешают установлению перемирия между этими двумя компаниями:
Фактически, IBM была в этой области первой. OS/2 превратилась в работающий продукт со свей версией 2.0 в 1992 году. С этого времени она стала многозадачной, многонитевой системой с удобным объектно-ориентированным интерфейсом. Усилия по развитию OS/2 были неторопливыми и постоянными, и система получала похвалы и поддержку на всем пути своего развития. Однако Windows по прежнему держала наибольшую долю рынка. Преимущества OS/2 были не всесторонними, и, несмотря на усилия технических и маркетинговых специалистов IBM, система не стала вполне совершенной.
В отношении управления системой, с OS/2 работать не проще, чем с Windows. Конфликты с аппаратной и программной совместимостью могут по прежнему вызывать проблемы, и их решение не выглядит универсальным и интуитивным.
Эмоционально, IBM чувствует себя "преданной" Microsoft, которая сбежала из рядов разработчиков OS/2. Это не совсем справедливо по отношению к Microsoft, так как компания вправе вкладывать свои капиталы с ту сферу деятельности, которая по ее мнению принесет наибольшую прибыль. Хотя Microsoft могла бы вести себя более тактично и продолжать партнерство по OS/2.
Хотя сейчас IBM далеко не та компания, какою она была в те далекие дни, когда она доминировала на рынке персональных компьютеров, ей тоже не хватает такта. Эта компания была первой так долго, что она не умеет выступать на вторых ролях. Первоначальная стратегия игнорирования общественных потребностей и навязывания дорогих, но не всегда обоснованных решений, быстро потерпела неудачу.С появлением клонов персональных компьютеров отпала необходимость платить больше только за марку IBM. Поэтому с момента появления версии OS/2 2.0 IBM изменила свою стратегию. Она стала играть по тем же правилам, по которым играют остальные компании.
Блокирующие и неблокирующие примитивы
Примитивы бывают блокирующими и неблокирующими, иногда они называются соответственно синхронными и асинхронными. При использовании блокирующего примитива, процесс, выдавший запрос на его выполнение, приостанавливается до полного завершения примитива. Например, вызов примитива ПОЛУЧИТЬ приостанавливает вызывающий процесс до получения сообщения.
При использовании неблокирующего примитива управление возвращается вызывающему процессу немедленно, еще до того, как требуемая работа будет выполнена. Преимуществом этой схемы является параллельное выполнение вызывающего процесса и процесса передачи сообщения. Обычно в ОС имеется один из двух видов примитивов и очень редко - оба. Однако выигрыш в производительности при использовании неблокирующих примитивов компенсируется серьезным недостатком: отправитель не может модифицировать буфер сообщения, пока сообщение не отправлено, а узнать, отправлено ли сообщение, отправитель не может. Отсюда сложности в построении программ, которые передают последовательность сообщений с помощью неблокирующих примитивов.
Имеется два возможных выхода. Первое решение - это заставить ядро копировать сообщение в свой внутренний буфер, а затем разрешить процессу продолжить выполнение. С точки зрения процесса эта схема ничем не отличается от схемы блокирующего вызова: как только процесс снова получает управление, он может повторно использовать буфер.
Второе решение заключается в прерывании процесса-отправителя после отправки сообщения, чтобы проинформировать его, что буфер снова доступен. Здесь не требуется копирование, что экономит время, но прерывание пользовательского уровня делает программирование запутанным, сложным, может привести к возникновению гонок.
Вопросом, тесно связанным с блокирующими и неблокирующими вызовами, является вопрос тайм-аутов. В системе с блокирующим вызовом ПОСЛАТЬ при отсутствии ответа вызывающий процесс может заблокироваться навсегда. Для предотвращения такой ситуации в некоторых системах вызывающий процесс может задать временной интервал, в течение которого он ждет ответ. Если за это время сообщение не поступает, вызов ПОСЛАТЬ завершается с кодом ошибки.
Буферизуемые и небуферизуемые примитивы
Примитивы, которые были описаны, являются небуферизуемыми примитивами. Это означает, что вызов ПОЛУЧИТЬ сообщает ядру машины, на которой он выполняется, адрес буфера, в который следует поместить пребывающее для него сообщение.
Эта схема работает прекрасно при условии, что получатель выполняет вызов ПОЛУЧИТЬ раньше, чем отправитель выполняет вызов ПОСЛАТЬ. Вызов ПОЛУЧИТЬ сообщает ядру машины, на которой выполняется, по какому адресу должно поступить ожидаемое сообщение, и в какую область памяти необходимо его поместить. Проблема возникает тогда, когда вызов ПОСЛАТЬ сделан раньше вызова ПОЛУЧИТЬ. Каким образом сможет узнать ядро на машине получателя, какому процессу адресовано вновь поступившее сообщение, если их несколько? И как оно узнает, куда его скопировать?
Один из вариантов - просто отказаться от сообщения, позволить отправителю взять тайм-аут и надеяться, что получатель все-таки выполнит вызов ПОЛУЧИТЬ перед повторной передачей сообщения. Этот подход не сложен в реализации, но, к сожалению, отправитель (или скорее ядро его машины) может сделать несколько таких безуспешных попыток. Еще хуже то, что после достаточно большого числа безуспешных попыток ядро отправителя может сделать неправильный вывод об аварии на машине получателя или о неправильности использованного адреса.
Второй подход к этой проблеме заключается в том, чтобы хранить хотя бы некоторое время, поступающие сообщения в ядре получателя на тот случай, что вскоре будет выполнен соответствующий вызов ПОЛУЧИТЬ. Каждый раз, когда поступает такое "неожидаемое" сообщение, включается таймер. Если заданный временной интервал истекает раньше, чем происходит соответствующий вызов ПОЛУЧИТЬ, то сообщение теряется.
Хотя этот метод и уменьшает вероятность потери сообщений, он порождает проблему хранения и управления преждевременно поступившими сообщениями. Необходимы буферы, которые следует где-то размещать, освобождать, в общем, которыми нужно управлять. Концептуально простым способом управления буферами является определение новой структуры данных, называемой почтовым ящиком.
Процесс, который заинтересован в получении сообщений, обращается к ядру с запросом о создании для него почтового ящика и сообщает адрес, по которому ему могут поступать сетевые пакеты, после чего все сообщения с данным адресом будут помещены в его почтовый ящик. Такой способ часто называют буферизуемым примитивом.
C
- бит подчинения, разрешает или запрещает вызов данного кодового сегмента из другого кодового сегмента с более низкими правами доступа.
В процессоре i386 существует большое количество системных сегментов, к которым в частности относятся системные сегменты типа LDT, шлюзы вызова подпрограмм и задач и сегменты состояния задачи TSS.
Таким образом, для использования чисто сегментного механизма процессора i386 операционной системе необходимо сформировать таблицы GDT и LDT, загрузить их в память (для начала достаточно загрузить только таблицу GDT), загрузить указатели на эти таблицы в регистры GDTR и LDTR и выключить страничную поддержку. Если же операционная система не хочет использовать сегментную организацию виртуальной памяти, то ей достаточно создать таблицу дескрипторов из одного входа (дескриптора) и загрузить базовые значения сегмента в дескриптор. Виртуальное адресное пространство задачи будет состоять из одного сегмента длиной максимум в 4 Гбайта.
C. Переносимость приложений
Унифицированная программная среда UnixWare обеспечивает поддержку широкого спектра приложений различных систем UNIX, включая SCO, ISC UNIX System V R3, SCO XENIX и BSD UNIX. Совместимость приложений обеспечивается строгим соблюдением промышленных стандартов UNIX System V Application Binary Interface (ABI), System V Interface Definition (SVID), iBSC2 и др.
Цели Mach
ОС Mach значительно изменилась со времени ее первой реализации в виде RIG. Цели проекта также изменились со временем. На текущий момент основные цели выглядят так:
Обеспечение базовых функций для создания других операционных систем (например, UNIX).
Поддержка больших разреженных адресных пространств.
Обеспечение прозрачного доступа к сетевым ресурсам.
Поддержка параллелизма как в системе, так и в приложениях.
Обеспечение переносимости Mach на различные типы компьютеров.
Централизованный алгоритм
Наиболее очевидный и простой путь реализации взаимного исключения в распределенных системах - это применение тех же методов, которые используются в однопроцессорных системах. Один из процессов выбирается в качестве координатора (например, процесс, выполняющийся на машине, имеющей наибольшее значение сетевого адреса). Когда какой-либо процесс хочет войти в критическую секцию, он посылает сообщение с запросом к координатору, оповещая его о том, в какую критическую секцию он хочет войти, и ждет от координатора разрешение. Если в этот момент ни один из процессов не находится в критической секции, то координатор посылает ответ с разрешением. Если же некоторый процесс уже выполняет критическую секцию, связанную с данным ресурсом, то никакой ответ не посылается; запрашивавший процесс ставится в очередь, и после освобождения критической секции ему отправляется ответ-разрешение. Этот алгоритм гарантирует взаимное исключение, но вследствие своей централизованной природы обладает низкой отказоустойчивостью.
Четвертый период (1980 - настоящее время)
Следующий период в эволюции операционных систем связан с появлением больших интегральных схем (БИС). В эти годы произошло резкое возрастание степени интеграции и удешевление микросхем. Компьютер стал доступен отдельному человеку, и наступила эра персональных компьютеров. С точки зрения архитектуры персональные компьютеры ничем не отличались от класса миникомпьютеров типа PDP-11, но вот цена у них существенно отличалась. Если миникомпьютер дал возможность иметь собственную вычислительную машину отделу предприятия или университету, то персональный компьютер сделал это возможным для отдельного человека.
Компьютеры стали широко использоваться неспециалистами, что потребовало разработки "дружественного" программного обеспечения, это положило конец кастовости программистов.
На рынке операционных систем доминировали две системы: MS-DOS и UNIX. Однопрограммная однопользовательская ОС MS-DOS широко использовалась для компьютеров, построенных на базе микропроцессоров Intel 8088, а затем 80286, 80386 и 80486. Мультипрограммная многопользовательская ОС UNIX доминировала в среде "не-интеловских" компьютеров, особенно построенных на базе высокопроизводительных RISC-процессоров.
В середине 80-х стали бурно развиваться сети персональных компьютеров, работающие под управлением сетевых или распределенных ОС.
В сетевых ОС пользователи должны быть осведомлены о наличии других компьютеров и должны делать логический вход в другой компьютер, чтобы воспользоваться его ресурсами, преимущественно файлами. Каждая машина в сети выполняет свою собственную локальную операционную систему, отличающуюся от ОС автономного компьютера наличием дополнительных средств, позволяющих компьютеру работать в сети. Сетевая ОС не имеет фундаментальных отличий от ОС однопроцессорного компьютера. Она обязательно содержит программную поддержку для сетевых интерфейсных устройств (драйвер сетевого адаптера), а также средства для удаленного входа в другие компьютеры сети и средства доступа к удаленным файлам, однако эти дополнения существенно не меняют структуру самой операционной системы.
Четыре модели организации связи доменов
Механизм доменов можно использовать на предприятии различными способами. В зависимости от специфики предприятия можно объединить ресурсы и пользователей в различное количество доменов, а также по-разному установить между ними доверительные отношения.
Microsoft предлагает использовать четыре типовые модели использования доменов на предприятии:
Модель с одним доменом;
Модель с главным доменом;
Модель с несколькими главными доменами;
Модель с полными доверительными отношениями.
Модель с одним доменом
Эта модель подходит для организации, в которой имеется не очень много пользователей, и нет необходимости разделять ресурсы сети по организационным подразделениям. Главный ограничитель для этой модели - производительность, которая падает, когда пользователи просматривают домен, включающий много серверов.
Использование только одного домена также означает, что сетевой администратор всегда должен администрировать все серверы. Разделение сети на несколько доменов позволяет назначать администраторов, которые могут администрировать только отдельные серверы, а не всю сеть.
D. Графический интерфейс
Стандарт X-Window, на основе которого построен мощный и удобный графический пользовательский интерфейс (GUI) UnixWare, в сочетании с сетевыми возможностями системы, позволяет эффективно использовать перспективные архитектуры типа "клиент-сервер". Графическая среда Desktop Manager позволяет выбирать одну из двух стандартных систем графического интерфейса (OSF/Motif или OPEN LOOK) и обеспечивает при работе с графическими объектами на экране доступ к приложениям, большинству системных программ и развитой системе подсказок. Предусмотрена также возможность непосредственного программирования функций Desktop Manager.
Динамическое связывание
Рассмотрим вопрос о том, как клиент задает месторасположение сервера. Одним из методов решения этой проблемы является непосредственное использование сетевого адреса сервера в клиентской программе. Недостаток такого подхода - его чрезвычайная негибкость: при перемещении сервера, или при увеличении числа серверов, или при изменении интерфейса во всех этих и многих других случаях необходимо перекомпилировать все программы, которые использовали жесткое задание адреса сервера. Для того, чтобы избежать всех этих проблем, в некоторых распределенных системах используется так называемое динамическое связывание.
Начальным моментом для динамического связывания является формальное определение (спецификация) сервера. Спецификация содержит имя файл-сервера, номер версии и список процедур-услуг, предоставляемых данным сервером для клиентов (рисунок 3.5). Для каждой процедуры дается описание ее параметров с указанием того, является ли данный параметр входным или выходным относительно сервера. Некоторые параметры могут быть одновременно входными и выходными - например, некоторый массив, который посылается клиентом на сервер, модифицируется там, а затем возвращается обратно клиенту (операция copy/ restore).
Рис. 3.5. Спецификация сервера RPC
Формальная спецификация сервера используется в качестве исходных данных для программы-генератора стабов, которая создает как клиентские, так и серверные стабы. Затем они помещаются в соответствующие библиотеки. Когда пользовательская (клиентская) программа вызывает любую процедуру, определенную в спецификации сервера, соответствующая стаб-процедура связывается с двоичным кодом программы. Аналогично, когда компилируется сервер, с ним связываются серверные стабы.
При запуске сервера самым первым его действием является передача своего серверного интерфейса специальной программе, называемой binder'ом. Этот процесс, известный как процесс регистрации сервера, включает передачу сервером своего имени, номера версии, уникального идентификатора и описателя местонахождения сервера.
Описатель системно независим и может представлять собой IP, Ethernet, X.500 или еще какой-либо адрес. Кроме того, он может содержать и другую информацию, например, относящуюся к аутентификации.
Когда клиент вызывает одну из удаленных процедур первый раз, например, read, клиентский стаб видит, что он еще не подсоединен к серверу, и посылает сообщение binder-программе с просьбой об импорте интерфейса нужной версии нужного сервера. Если такой сервер существует, то binder передает описатель и уникальный идентификатор клиентскому стабу.
Клиентский стаб при посылке сообщения с запросом использует в качестве адреса описатель. В сообщении содержатся параметры и уникальный идентификатор, который ядро сервера использует для того, чтобы направить поступившее сообщение в нужный сервер в случае, если их несколько на этой машине.
Этот метод, заключающийся в импорте/экспорте интерфейсов, обладает высокой гибкостью. Например, может быть несколько серверов, поддерживающих один и тот же интерфейс, и клиенты распределяются по серверам случайным образом. В рамках этого метода становится возможным периодический опрос серверов, анализ их работоспособности и, в случае отказа, автоматическое отключение, что повышает общую отказоустойчивость системы. Этот метод может также поддерживать аутентификацию клиента. Например, сервер может определить, что он может быть использован только клиентами из определенного списка.
Однако у динамического связывания имеются недостатки, например, дополнительные накладные расходы (временные затраты) на экспорт и импорт интерфейсов. Величина этих затрат может быть значительна, так как многие клиентские процессы существуют короткое время, а при каждом старте процесса процедура импорта интерфейса должна быть снова выполнена. Кроме того, в больших распределенных системах может стать узким местом программа binder, а создание нескольких программ аналогичного назначения также увеличивает накладные расходы на создание и синхронизацию процессов.
Доменный подход
Домен - это основная единица администрирования и обеспечения безопасности в Windows NT. Для домена существует общая база данных учетной информации пользователей (user accounts), так что при входе в домен пользователь получает доступ сразу ко всем разрешенным ресурсам всех серверов домена.
Доверительные отношения (trust relationships) обеспечивают транзитную аутентификацию, при которой пользователь имеет только одну учетную запись в одном домене, но может получить доступ к ресурсам всех доменов сети.
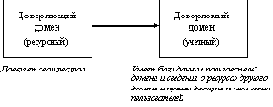
Рис. 3.20. Доверительные отношения между доменами
Пользователи могут входить в сеть не только из рабочих станций того домена, где хранится их учетная информация, но и из рабочих станций доменов, которые доверяют этому домену. Домен, хранящий учетную информацию, часто называют учетным, а доверяющий домен - ресурсным.
Доверительные отношения не являются транзитивными. Например, если домен А доверяет домену В, а В доверяет С, то это не значит, что А автоматически доверяет С.
Драйверы
Драйвер - это совокупность программ (секций), предназначенная для управления передачей данных между внешним устройством и оперативной памятью.
Связь ядра системы с драйверами (рисунок 5.15) обеспечивается с помощью двух системных таблиц:
bdevsw - таблица блок-ориентированных устройств и
cdevsw - таблица байт-ориентированных устройств.
Для связи используется следующая информация из индексных дескрипторов специальных файлов:
класс устройства (байт-ориентированное или блок-ориентированное),
тип устройства (лента, гибкий диск, жесткий диск, устройство печати, дисплей, канал связи и т.д.)
номер устройства.
Класс устройства определяет выбор таблицы bdevsw или cdevsw. Эти таблицы содержат адреса программных секций драйверов, причем одна строка таблицы соответствует одному драйверу. Тип устройства определяет выбор драйвера. Типы устройств пронумерованы, т.е. тип определяет номер строки выбранной таблицы. Номер устройства передается драйверу в качестве параметра, так как в ОС UNIX драйверы спроектированы в расчете на обслуживание нескольких устройств одного типа.
Такая организация логической связи между ядром и драйверами позволяет легко настраивать систему на новую конфигурацию внешних устройств путем модификации таблиц bdevsw и cdevsw.
Драйвер байт-ориентированного устройства в общем случае состоит из секции открытия, чтения и записи файлов, а также секции управления режимом работы устройства. В зависимости от типа устройства некоторые секции могут отсутствовать. Это определенным образом отражено в таблице cdevsw. Секции записи и чтения обычно используются совместно с модулями обработки прерываний ввода-вывода от соответствующих устройств.
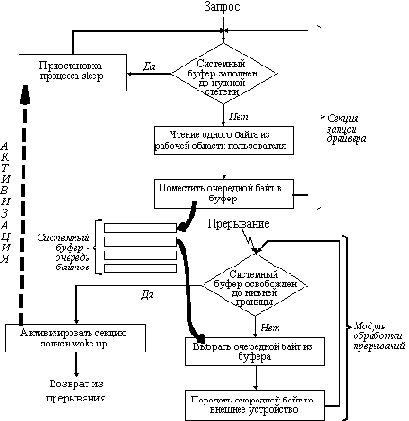
Рис. 5.16. Взаимодействие секции записи драйвера с модулем обработки прерывания
На рисунке 5.16 показано взаимодействие секции записи драйвера байт-ориентированного устройства с модулем обработки прерываний. Секция записи осуществляет передачу байтов из рабочей области программы, выдавшей запрос на обмен, в системный буфер, организованный в виде очереди байтов.
Передача байтов идет до тех пор, пока системный буфер не заполнится до некоторого, заранее определенного в драйвере, уровня. В результате секция записи драйвера приостанавливается, выполнив системную функцию sleep (аналог функций типа wait). Модуль обработки прерываний работает асинхронно секции записи. Он вызывается в моменты времени, определяемые готовностью устройства принять следующий байт. Если при очередном прерывании оказывается, что очередь байтов уменьшилась до определенной нижней границы, то модуль обработки прерываний активизирует секцию записи драйвера путем обращения к системной функции wakeup.
Аналогично организована работа при чтении данных с устройства.
Драйвер блок-ориентированного устройства состоит в общем случае из секций открытия и закрытия файлов, а также секции стратегии. Кроме адресов этих секций, в таблице bdevsw указаны адреса так называемых таблиц устройств (rktab). Эти таблицы содержат информацию о состоянии устройства - занято или свободно, указатели на буфера, для которых активизированы операции обмена с данным устройством, а также указатели на цепочку буферов, в которых находятся блоки данных, предназначенные для обмена с данным устройством.
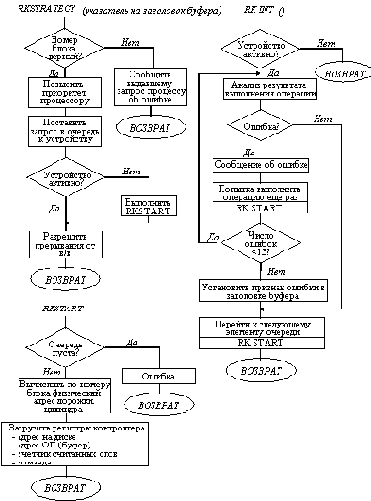
Рис 5.17. Структурная схема драйвера диска типа RK
На рисунке 5.17 приведена упрощенная схема драйвера жесткого диска. Секция стратегии - rkstrategy - выполняет постановку запроса на ввод-вывод в очередь к устройству путем присоединения указанного буфера к цепочке буферов, уже предназначенных для обмена с данным устройством. В случае необходимости секция стратегии запускает устройство (программа rkstart) для выполнения чтения или записи блока с устройства. Вся информация о требуемой операции может быть получена из заголовка буфера, указатель на который передается секции стратегии в качестве аргумента.
После запуска устройства управление возвращается процессу, выдавшему запрос к драйверу.
Об окончании ввода-вывода каждого блока устройство оповещает операционную систему сигналом прерывания.Первое слово вектора прерываний данного устройства содержит адрес секции драйвера - модуля обработки прерываний rkintr. Модуль обработки прерываний проводит анализ правильности выполнения ввода-вывода. Если зафиксирована ошибка, то несколько раз повторяется запуск этой же операции, после чего драйвер переходит к вводу-выводу следующего блока данных из очереди к устройству.
Драйверы устройств
Весь зависимый от устройства код помещается в драйвер устройства. Каждый драйвер управляет устройствами одного типа или, может быть, одного класса.
В операционной системе только драйвер устройства знает о конкретных особенностях какого-либо устройства. Например, только драйвер диска имеет дело с дорожками, секторами, цилиндрами, временем установления головки и другими факторами, обеспечивающими правильную работу диска.
Драйвер устройства принимает запрос от устройств программного слоя и решает, как его выполнить. Типичным запросом является чтение n блоков данных. Если драйвер был свободен во время поступления запроса, то он начинает выполнять запрос немедленно. Если же он был занят обслуживанием другого запроса, то вновь поступивший запрос присоединяется к очереди уже имеющихся запросов, и он будет выполнен, когда наступит его очередь.
Первый шаг в реализации запроса ввода-вывода, например, для диска, состоит в преобразовании его из абстрактной формы в конкретную. Для дискового драйвера это означает преобразование номеров блоков в номера цилиндров, головок, секторов, проверку, работает ли мотор, находится ли головка над нужным цилиндром. Короче говоря, он должен решить, какие операции контроллера нужно выполнить и в какой последовательности.
После передачи команды контроллеру драйвер должен решить, блокировать ли себя до окончания заданной операции или нет. Если операция занимает значительное время, как при печати некоторого блока данных, то драйвер блокируется до тех пор, пока операция не завершится, и обработчик прерывания не разблокирует его. Если команда ввода-вывода выполняется быстро (например, прокрутка экрана), то драйвер ожидает ее завершения без блокирования.
E. Поддержка национальных алфавитов
В UnixWare предусмотрен широкий набор средств "интернационализации", включающий поддержку различных раскладок клавиатуры, наборов символов и языков пользовательского интерфейса.
ED
- направления распространения сегмента (ED = 0 для обычного сегмента данных, распространяющегося в сторону увеличения адресов, ED = 1 для стекового сегмента данных, распространяющегося в сторону уменьшения адресов),
F. Масштабируемые шрифты
В комплект поставки UnixWare входит система Adobe Type Manager, обеспечивающая доступ к тысячам существующих масштабируемых шрифтов формата Type 1.
Файловая система
Файловая система - это часть операционной системы, назначение которой состоит в том, чтобы обеспечить пользователю удобный интерфейс при работе с данными, хранящимися на диске, и обеспечить совместное использование файлов несколькими пользователями и процессами.
В широком смысле понятие "файловая система" включает:
совокупность всех файлов на диске,
наборы структур данных, используемых для управления файлами, такие, например, как каталоги файлов, дескрипторы файлов, таблицы распределения свободного и занятого пространства на диске,
комплекс системных программных средств, реализующих управление файлами, в частности: создание, уничтожение, чтение, запись, именование, поиск и другие операции над файлами.
Файловая система NetWare значительно отличается от файловых систем ОС общего назначения следующими ключевыми свойствами:
в ней предприняты дополнительные меры по сохранению целостности данных;
достигнута высокая производительность;
обеспечена емкость файловых систем класса мейнфреймов;
обеспечивается широкий набор функций файловых API для серверных приложений.
Файловая система NetWare 4.x обратно совместима с файловой системой NetWare 3.x, но имеет несколько новых свойств, включая интерфейс монитора файловой системы.
Файловая система AFS
AFS была разработана в университете Карнеги-Меллона и названа в честь спонсоров-основателей университета Andrew Carnegie и Andrew Mellon. Эта система, созданная для студентов университета, не является прозрачной системой, в которой все ресурсы динамически назначаются всем пользователям при возникновении потребностей. Несмотря на это, файловая система была спроектирована так, чтобы обеспечить прозрачность доступа каждому пользователю, независимо от того, какой рабочей станцией он пользуется.
Особенностью этой файловой системы является возможность работы с большим (до 10 000) числом рабочих станций.

Рис. 4.5. Конфигурация системы, используемая AFS в университете Карнеги-Меллона
Конфигурация системы показана на рисунке 4.5. Она состоит из кластеров, каждый из которых включает файловый сервер и несколько десятков рабочих станций. Идея состоит в том, чтобы распределить большую часть трафика в пределах отдельных кластеров и тем самым уменьшить загрузку позвоночника сети.
Так как студенты могли входить в систему и в университете, и в общежитии, то иногда они оказывались далеко от сервера, который содержал их файлы. Несмотря на это, пользователь должен иметь возможность работать на произвольно выбранной рабочей станции, как на своем персональном компьютере.
Физически нет разницы между машиной клиента и сервера, и все они выполняют одну и ту же ОС BSD UNIX с его большим монолитным ядром. Однако над ядром выполняются совершенно различные программы серверов и клиентов. На клиент-машинах выполняются менеджеры окон, редакторы и другое стандартное программное обеспечение системы UNIX. Каждый клиент имеет также часть кода - venus, которая управляет интерфейсом между клиентом и серверной частью системы, называемой vice. Вначале venus выполнялся в пользовательском режиме, но позже он был перемещен в ядро для повышения производительности. Venus работает также в качестве менеджера кэша. В дальнейшем мы будем называть venus просто клиентом, а vice - сервером.
Пространство имен, видимое пользовательскими программами, выглядит как традиционное дерево в ОС UNIX с добавленным к нему каталогом /cmu (рисунок 4.5).
Содержимое каталога /cmu поддерживается AFS посредством vice-серверов и идентично на всех рабочих станциях. Другие каталоги и файлы исключительно локальны и не разделяются. Возможности разделяемой файловой системы предоставляются путем монтирования к каталогу /cmu. Файл, который UNIX ожидает найти в верхней части файловой системы, может быть перемещен символьной связью из разделяемой файловой системы (например, /bin/sh может быть символьно связан с /cmu/bin/sh).
В основе AFS лежит стремление делать для каждого пользователя как можно больше на его рабочей станции и как можно меньше взаимодействовать с остальной системой. При открытии удаленного файла весь файл (или его значительная часть, если он очень большой) загружается на диск рабочей станции и кэшируется там, причем процесс, который сделал вызов OPEN, даже не знает об этом. По этой причине каждая рабочая станция имеет диск.
После загрузки файла на локальный диск он помещается в локальный каталог /cash, так что он выглядит для ОС как нормальный файл. Дескриптор файла, возвращаемый системным вызовом OPEN, соответствует именно этому файлу, так что вызовы READ и WRITE работают обычным путем, без участия клиента и сервера. Другими словами, хотя системный вызов OPEN значительно изменен, реализация READ и WRITE не изменилась.
Безопасность - это главный вопрос в системе с 10 000 пользователей. Так как пользователи вольны перегружать свои рабочие станции, когда захотят и могут выполнять на них модифицированные версии ОС, то главный принцип сервера - не доверять клиентским рабочим станциям. Все сообщения между рабочими станциями шифруются на уровне аппаратуры.
Защита выполнена несколько необычным путем. Каталоги защищаются списками прав доступа (ACL), но файлы имеют обычные биты RWX UNIX'а. Разработчики системы предпочитают механизм ACL, но так как многие UNIX-программы работают с битами RWX, то они оставлены для совместимости. Списки прав доступа могут содержать и отсутствие прав, так что можно, например, потребовать, чтобы доступ к файлу был разрешен для всех, кроме одного конкретного человека.
Диски рабочих станций используются только для временных файлов, кэширования удаленных файлов и хранения страниц виртуальной памяти, но не для постоянной информации. Это существенно упрощает управление системой, в этом случае нужно управлять и архивировать только файлы серверов, а рабочие станции не требуют никаких забот. Концептуально они могут начинать каждый рабочий день с чистого листа.
AFS сконструирована для расширения до масштабов национальной файловой системы. Система, показанная на рисунке, на самом деле представляет собой отдельную ячейку (cell). Каждая ячейка - это административная единица, такая как отдел или компания. Ячейки могут быть соединены друг с другом с помощью монтирования, так что дерево разделяемых файлов может покрывать многие города.
В дополнение к концепциям файла, каталога и ячейки AFS поддерживает еще одно важное понятие - том. Том - это собрание каталогов, которые управляются вместе. Обычно все файлы какого-либо пользователя составляют том. Таким образом поддерево, входящее в /usr/john, может быть одним томом, поддерево, входящее в /usr/mary, может быть другим томом. Фактически, каждая ячейка представляет собой ничто иное, как набор томов, соединенных вместе некоторым, подходящим с точки зрения монтирования, образом. Большинство томов содержат пользовательские файлы, некоторые другие используются для двоичных выполняемых файлов и другой системной информации. Тома могут иметь признак "только для чтения".
Семантика, предлагаемая AFS, близка к сессионной семантике. Когда файл открывается, он берется у подходящего сервера и помещается в каталог /cash на локальном диске на рабочей станции. Все операции чтения-записи работают с кэшированной копией. При закрытии файла он выгружается назад на сервер. Следствием этой модели является то, что когда процесс открывает уже открытый файл, то версия, которую он видит, зависит от того, где находится процесс. Процесс на той же рабочей станции видит копию в каталоге /cash, при этом выполняется вся семантика UNIX.
В то же время процесс на другой рабочей станции продолжает видеть исходную версию файла на сервере. Только после того, как файл будет закрыт и отослан обратно на сервер, последующая операция открытия увидит новую версию. После того, как файл закрывается, он остается в кэше, на случай, если он скоро будет снова открыт. Как мы видели ранее, повторное открытие файла, который находится в кэше, порождает проблему: "Как клиент узнает, последняя ли это версия файла?" В первой версии AFS эта проблема решалась прямым запросом клиента к серверу. К сожалению эти запросы создавали большой трафик и впоследствии алгоритм был изменен. В новом алгоритме, когда клиент загружает файл в свой кэш, то он сообщает серверу, что его интересуют все операции открытия этого файла процессами на других рабочих станциях. В этом случае сервер создает таблицу, отмечающую местонахождение этого кэшированного файла. Если другой процесс где-либо в системе открывает этот файл, то сервер посылает сообщение клиенту, чтобы тот отметил этот вход кэша как недействительный. Если этот файл в настоящее время используется, то использующие его процессы могут продолжать делать это. Однако, если другой процесс пытается открыть его заново, то клиент должен свериться с сервером, действителен ли все еще этот вход в кэше, а если нет, то получить новую копию. Если рабочая станция терпит крах, а затем перезагружается, то все файлы в кэше отмечаются как недействительные.
Блокировка файла поддерживается с помощью системного вызова UNIX FLOCK. Если блокировка не снимается в течение 30 минут, то она снимается по тайм-ауту. Тома, предназначенные только для чтения, такие как системные двоичные файлы, реплицируются, а пользовательские файлы - нет.
Хотя прикладные программы видят традиционное пространство имен UNIX, внутренняя организация сервера и клиента использует совершенно другую схему имен. Они используют двухуровневую схему именования, при которой каталог содержит структуры, называемые fids (file identifiers), вместо традиционных номеров i-узлов.
Fid состоит из трех 32- х битных полей. Первое поле - это номер тома, который однозначно определяет отдельный том в системе. Это поле говорит, на каком томе находится файл. Второе поле называется vnode, это индекс в системных таблицах определенного тома. Оно определяет конкретный файл в данном томе. Третье поле - это уникальный номер, который используется для обеспечения повторного использования vnode. Если файл удаляется, то его vnode может быть повторно использован, но с другим значением уникального номера, для того, чтобы обнаружить и отвергнуть все старые fids.
Протокол между сервером и клиентом использует fid для идентификации файла. Когда fid поступает в сервер, по значению номера тома производится поиск в базе данных, управляемой всеми серверами, чтобы обнаружить нужный сервер. Тома могут перемещаться между серверами, но не части томов, так что эта база данных требует периодического обновления, но перемещения томов случается редко, так что трафик обновления невелик. Перемещение тома является неделимым - сначала на сервере назначения делается копия тома, а затем удаляется оригинал. Этот механизм также используется для репликации томов только для чтения за исключением того, что исходный том не удаляется после его копирования. Этот же алгоритм используется для резервного копирования. Когда делается копия, то она помещается в файловую систему как том только для чтения. В течение последующих 24 часов процесс скопирует этот том на ленту. Дополнительное преимущество этого метода - пользователь, который случайно удалил файл, все еще имеет доступ ко вчерашней копии.
Теперь рассмотрим общий механизм доступа к файлам в AFS. Когда приложение выполняет системный вызов OPEN, то он перехватывается оболочкой клиента, которая первым делом проверяет, не начинается ли имя файла с /cmu. Если нет, то файл локальный, и обрабатывается обычным способом. Если да, то файл разделяемый. Производится грамматический разбор имени, покомпонентно находится fid. По fid проверяется кэш, и здесь имеется три возможности:
Файл находится в кэше, и он достоверен.
Файл находится в кэше, и он не достоверен.
Файл не находится в кэше.
В первом случае используется кэшированный файл. Во втором случае клиент запрашивает сервер, изменялся ли файл после его загрузки. Файл может быть недостоверным, если рабочая станция недавно перезагружалась или же некоторый другой процесс открыл файл для записи, но это не означает, что файл уже модифицирован, и его новая копия записана на сервер. Если файл не изменялся, то используется кэшированный файл. Если он изменялся, то используется новая копия. В третьем случае файл также просто загружается с сервера. Во всех трех случаях конечным результатом будет то, что копия файла будет на локальном диске в каталоге /cash, отмеченная как достоверная.
Вызовы приложения READ и WRITE не перехватываются оболочкой клиента, они обрабатываются обычным способом. Вызовы CLOSE перехватываются оболочкой клиента, которая проверяет, был ли модифицирован файл, и, если да, то переписывает его на сервер, который управляет данным томом.
Помимо кэширования файлов, оболочка клиента также управляет кэшем, который отображает имена файлов в идентификаторы файлов fid. Это ускоряет проверку, находится ли имя в кэше. Проблема возникает, когда файл был удален и заменен другим файлом. Однако этот новый файл будет иметь другое значение поля "уникальный номер", так что fid будет выявлен как недостоверный. При этом клиент удалит вход (pass, fid) и начнет грамматический разбор имени с самого начала. Если дисковый кэш переполняется, то клиент удаляет файлы в соответствии с алгоритмом LRU.
Vice работает на каждом сервере как отдельная многонитевая программа. Каждая нить обрабатывает один запрос. Протокол между сервером и клиентом использует RPC и построен непосредственно на API. В нем есть команды для перемещения файлов в обоих направлениях, блокирования файлов, управления каталогами и некоторые другие. Vice хранит свои таблицы в виртуальной памяти, так что они могут быть произвольной величины.
Так как клиент идентифицирует файлы по их идентификаторам fid, то у сервера возникает следующая проблема: как обеспечить доступ к UNIX-файлу, зная его vnode, но не зная его полное имя. Для решения этой проблемы в AFS в UNIX добавлен новый системный вызов, позволяющий обеспечить доступ к файлам по их индексам vnode.
Реализация DFS на базе AFS дает прекрасный пример того, как работают вместе различные компоненты DCE. DFS работает на каждом узле сети совместно со службой каталогов DCE, обеспечивая единое пространство имен для всех файлов, хранящихся в DFS. DFS использует списки ACL системы безопасности DCE для управления доступом к отдельным файлам. Потоковые функции RPC позволяют DFS передавать через глобальные сети большие объемы данных за одну операцию.
Файловая система HPFS
HPFS - сокращенное название высокопроизводительной файловой системы (high performance file system), совместно разработанной в 1989 году корпорациями IBM и Microsoft.
Эта система была разработана, чтобы преодолеть некоторые недостатки FAT, к числу которых относятся:
ограничения, налагаемые на размер файлов и дискового пространства;
ограничение длины имени файла;
фрагментация файлов, приводящая к снижению быстродействия системы и износу оборудования;
непроизводительные затраты памяти, вызванные большими размерами кластеров;
подверженность потерям данных.
Проблема непроизводительных потерь дискового пространства связана с тем, что место на диске выделяется целыми блоками - кластерами. Кластер - это единица дискового пространства, которыми оперирует файловая система при выделении места для файла. В среднем половина выделяемого кластера для каждого файла будет затрачиваться в пустую. Это может быть одной из причин нерационального использования памяти диска. Например, при емкости диска 510 Мбайт число размещенных на нем файлов может составить около 1,5 тысяч. В этом случае FAT приведет к потере 6 Мбайт пространства, обусловленной только размером выделяемого блока. Для очень распространенных сейчас дисков емкостью 850 Мбайт ситуация может оказаться еще более критической. На таком диске может разместиться около 2 тысяч файлов, что повлечет за собой потерю 20 Мбайт. Для сетевых дисков емкостью в несколько гигабайт потери достигают астрономических цифр. Чем больше размер раздела жесткого диска, тем больше объем минимальной неделимой области памяти, выделяемой файлу, тем больше потери.
Эти потери можно существенно сократить внедрением более эффективных файловых систем. Простой переход на HPFS, работающую в среде OS/2, позволяет вновь вернуться к первоначальному размеру выделяемого блока - 512 байт, причем для любых размеров диска. Размер вероятного выигрыша для диска емкостью 512 Мбайт, содержащего 8 000 файлов, составит около 30 Мбайт. Этот выигрыш связан с тем, что на каждом файле в среднем теряется не 4096 байт (половина размера кластера в FAT для диска данной емкости), а всего 256 байт.
В OS/ 2 положение осложняется применяемым методом хранения расширенных атрибутов (extended attributes). В разделе FAT файл, содержащий единственный символ, занял бы целый кластер для размещения собственно файла и еще один кластер для расширенных атрибутов.
Так как расширенные атрибуты почти всегда имеют объем меньше 300 байт, размер теряемого впустую дискового пространства изменяется от примерно половины кластера при использовании малых разделов до львиной доли объема кластер при больших разделах. В сумме на каждом файле теряется примерно кластер.
Переход на HPFS позволит сэкономить дисковое пространство. HPFS распределяет пространство, основываясь на физических 512-байтовых секторах, а не на кластерах, независимо от размера раздела. Система HPFS позволяет уменьшить и непроизводительные потери, так как в ней предусмотрено хранение до 300 байт расширенных атрибутов в F-узле файла, без захвата для этого дополнительного сектора.
Другая проблема связана с фрагментацией файлов, которая наиболее характерна для емких дисков с большим числом файлов. Фрагментация существенно сказывается на времени доступа к файлу. Другой негативный эффект фрагментации - повышенный износ диска. О серьезности этой проблемы говорит обилие утилит для дефрагментации дисков, использующих FAT.
Файловая система HPFS обеспечивает гораздо более низкий уровень фрагментации. Хотя избавиться полностью от нее не удается, снижение производительности, возникающее по этой причине, почти незаметно для пользователя.
Первые 16 секторов раздела HPFS составляют загрузочный блок. Эта область содержит метку диска и код начальной загрузки системы. Сектор 16, известный под названием суперблок, содержит много общей информации о файловой системе в целом: размер раздела, указатель на корневой каталог, счетчик элементов каталогов, номер версии HPFS, дату последней проверки и исправления раздела при помощи команды CHKDSK, а также дату последнего выполнения процедуры дефрагментации раздела. Он также содержит указатели на список испорченных блоков на диске, таблицу дефектных секторов и список доступных секторов.
Сектор 17 носит название SpareBlock (запасной блок). Он содержит указатель на список секторов, которые можно использовать для "горячего" исправления ошибок, счетчик доступных секторов для "горячего" исправления ошибок, указатель на резерв свободных блоков, применяемых для управления деревьями каталогов, и информацию о языковых наборах символов. Система HPFS использует информацию о языковых наборах, чтобы дать возможность пересылать файлы, составленные на разных языках, даже в том случае, когда имена файлов содержат уникальные для какого-либо языка символы. SpareBlock также содержит так называемый "грязный" флаг. Этот новый флаг сообщает операционной системе о том, было ли завершение предыдущего сеанса работы нормальным, либо произошло в результате сбоя электропитания, либо файлы не были закрыты должным образом по какой-то другой причине. Если этот флаг обнаружен во время начальной загрузки, то операционная система автоматически запускает утилиту CHKDSK, пытаясь обнаружить и исправить все ошибки, внесенные в файловую систему из-за неправильного выключения системы.
Рис. 9.3. Прием увеличения доступного непрерывного пространства
Во время форматирования раздела HPFS делит его на полосы по 8 Мбайт каждая. Каждая полоса - ее можно представить себе как виртуальный "мини-диск" - имеет отдельную таблицу объемом 2 Кбайт, в которой указывается , какие секторы полосы доступны, а какие заняты. Чтобы максимально увеличить протяженность непрерывного пространства для размещения файлов, таблицы попеременно располагаются в начале и в конце полос (рисунок 9.3). Этот метод позволяет файлам размером до 16 Мбайт (минус 4 Кбайта, отводимые для размещения таблицы) храниться в одной непрерывной области.
Затем файловая система HPFS оценивает размер каталога и резервирует необходимое пространство в полосе, расположенной ближе всего к середине диска. Сразу же после форматирования объем диска в HPFS кажется меньше, чем в FAT, так как заранее резервируется место для каталогов в центре диска.
Место резервируется в середине диска для того, чтобы физические головки, считывающие данные, никогда не проходили более половины ширины диска.
Тот факт, что все пространство заранее распределено, также позволяет HPFS использовать специально оптимизированное программное обеспечение для более быстрой и эффективной работы с каталогами. Сравните это с системой FAT, где головкам требуется пройти весь путь к началу диска и прочитать таблицу размещения файлов, затем найти кластер, вновь пройти к началу диска, чтобы определить в FAT местонахождения следующего кластера, и так далее. Эта процедура становится еще более неудобной по мере нарастания фрагментации. Поэтому ясно, что размещение каталогов в середине диска повышает производительность системы. Вместе с тем, такое предварительное распределение не накладывает ограничений на число файлов, которые могут быть размещены на жестком диске. В редких случаях, когда системе HPFS потребуется больше пространства, чем изначально было отведено под каталоги, она может выделить дополнительное пространство из любой доступной области диска.
Число файлов в каждом блоке каталога - переменная величина, зависящая от длины имен файлов, которые содержатся в нем. Имена файлов в HPFS могут иметь длину до 254 символов, они сортируются в порядке, определяемом последовательностью символов в текущей кодовой странице системы.
Скорость работы увеличивается также благодаря способу хранения элементов каталогов. Система FAT последовательно просматривает каждый элемент каталога, чтобы отыскать нужный файл. Поэтому в самом худшем случае приходится перебирать все файлы в каталоге, прежде, чем найдется нужный. Но HPFS использует для хранения элементов каталогов структуру данных, называемую В-деревом. Каждый элемент каталога начинается с числа, представляющего длину элемента, которая изменяется в зависимости от длины имени файла. Затем следуют время и дата создания файла, его размер и атрибуты (только для чтения, архивный, скрытый и системный), а также указатель на F-узел файла.
Каждый файл (и каталог) имеет F-узел - структуру данных, занимающую один сектор и содержащую принципиально важную информацию о файле.
F-узел содержит указатель на начало файла, первые 15 символов имени файла, дополнительные временные маркеры последней записи и последнего доступа, журнал, хранящий информацию о предыдущих обращениях к файлу, структуру распределения, описывающую размещение файла на диске, и первые 300 байт расширенных атрибутов файла. (Расширенные атрибуты редко занимают более 300 байт, что фактически означает, что HPFS для получения этой информации приходится читать на один сектор меньше, чем FAT.) Программы LAN Server и LAN Manager фирмы IBM также сохраняют в F-узле информацию об управлении пользовательским доступом (Access Control). Заметьте, что F-узлы хранятся в смежных с представляемыми ими файлами секторах, поэтому, когда файл открывается, то четыре автоматически считываемых в кэш сектора содержат F-узел и три первых сектора файла.
Структура размещения HPFS имеет дополнительные преимущества по сравнению с FAT благодаря техническому приему, называемому кодированием по длине выполнения (Run Length Encoding, RLE). Вместо того, чтобы определять в таблице каждый используемый сектор, HPFS сохраняет указатель на первый сектор и число последовательно расположенных используемых секторов. Каждая область дискового пространства, описываемая парой (сектор, длина), называется экстентом. Хотя HPFS и сводит фрагментацию к минимуму, файлы все же могут быть в некоторой степени фрагментированными. В таких ситуациях пары, описывающие экстенты, добавляются к F-узлу файла. Один F-узел может хранить до 8 экстентов, обеспечивая достаточное пространство для большинства файлов.
А если все же потребуется еще большее пространство, то HPFS изменяет структуру таким образом, что F-узел становится корнем В+-дерева секторов размещения. В+-дерево является вариантом бинарного В-дерева. Созданное как структура для более быстрого обнаружения данных по сравнению с методом последовательного перебора, бинарное дерево состоит из ветвей, каждая из которых представляет выбор одного из двух возможных продолжений.
Короткое дерево территориальных телефонных кодов может выглядеть так, как показано на рисунке 9.4,а. Здесь левая ветвь соответствует числам с меньшими значениями, чем значение в точке разветвления, а правая - с большими. Пусть выполняется поиск, например, кода 513. Вначале анализируется код в вершине дерева, поскольку 513 больше 212, то дальнейший поиск осуществляется по правой ветви. Так как 513 больше 407, то вновь поиск идет по правой ветви, где и находится нужный элемент данных. Для того, чтобы найти данные с помощью этого метода, потребовалось выполнить только два сравнения, в то время как для последовательного перебора могло бы потребоваться пять сравнений.
Рис. 9.4. Бинарные древовидные структуры
Эффективность бинарных деревьев зависит от последовательности, в которой в них добавляются новые элементы данных. Если, например, добавить код 617, то он будет следовать за кодом 513, а если добавить еще один код 714, то он последует за кодом 617. Поэтому, если элементы добавляются в порядке возрастания, то результирующее дерево становится все более похожим на последовательную структуру (рис. 9.4,б).
Структура В-дерева была разработана в целях предотвращения этой проблемы. Методы управления В-деревьями обеспечивают сбалансированность дерева. Структуру на рисунке 9.4 (б) лучше реорганизовать так, чтобы она приняла вид, показанный на рисунке 9.4 (в). Это делает дерево более эффективным, но приводит к дополнительным затратам, так как его балансировка выполняется всякий раз при добавлении или удалении элемента, либо при изменении значения элемента.
Возвращаясь к методу описания физической структуры файла, основанному на экстентах, следует учесть, что многие современные контроллеры дисков могут читать за одно обращение сразу несколько секторов. Применяемая в HPFS схема значительно повышает шансы использовать эту возможность, при этом происходит еще большее уменьшение числа требуемых операций взаимодействия между программой, файловой системой, драйвером дискового устройства и физическим диском.
HPFS имеет и другие оптимизирующие функции. Так при открытии или создании файла интеллектуальный алгоритм выделяет наиболее подходящую полосу. Программный интерфейс, используемый для создания файла, позволяет программисту сообщить операционной системе предполагаемый размер файла. С помощью этой информации HPFS может заранее выбрать для размещения файла полосу, имеющую непрерывную область наибольшего размера. Именно поэтому HPFS наиболее эффективно работает в больших разделах - больше число полос предоставляет большие возможности выбора.
Предположим, что многонитевая операционная система одновременно создает четыре новых файла на диске, использующем FAT. Так как для каждого файла нужен новый сектор, то он занимает ближайший доступный сектор в таблице размещения файлов. Это приводит к значительной фрагментации, так как кластеры между файлами распределяются вперемежку. HPFS выделила бы каждому из четырех файлов отдельную полосу, чтобы их содержимое оставалось непрерывным.
Как уже упоминалось, при открытии файла F-узел и первые три сектора считываются и помещаются в кэш. Если открываемый файл - исполняемый или если по данным журнала доступа к файлам в F-узле видно, что файл после открытия часто читается целиком, то многие секторы будут предварительно автоматически прочитаны и помещены в кэш.
Операции записи в кэш осуществляются особым образом, который называется "ленивой" записью. Когда программа посылает команду записи, HPFS помещает данные в кэш и немедленно сообщает программе, что операция выполнена, и только потом в фоновом режиме данные перемещаются из оперативной памяти на устройство. Это исключает длительную задержку, сопровождающую действительную операцию записи данных на устройство ввода-вывода. Однако при этом существует риск нарушения целостности данных. Например, уже после того, как программа получила от ОС сообщение об успешном завершении операции ввода-вывода, при попытке записать данные из кэша на диск драйвер этого устройства может сообщить об ошибке обращения к диску.
В таком случае весьма полезным является список блоков "горячего" исправления.
Если попытка записи на диск заканчивается неудачно, то HPFS отыскивает в SpareBlock блок, который можно использовать для "горячего" исправления. Данные записываются в область "горячего" исправления, а таблицы неисправных блоков обновляются, указывая испорченный сектор и блок. HPFS будет автоматически перенаправлять запросы чтения по новому адресу. Во время очередного выполнения утилиты CHKDSK файл будет скопирован в новое место, где он может храниться в непрерывной области. При обращении к нему нет необходимости переходить к блоку "горячего" исправления и обратно. Блок будет освобожден для использования в случае возникновения другой подобной проблемы. Таким образом, проблема решается автоматически без участи пользователя.
Для повышения эффективности система HPFS также предоставляет многоуровневые кэши. Например, она сохраняет в кэше подкаталоги, а также полное составное имя, записав в памяти контрольную сумму, однозначно определяющую путь к файлу. Поэтому при обращении к файлу, расположенному в глубоко вложенном каталоге, скорее всего будет возможен быстрый доступ сразу в нужный каталог без поиска по дереву каталогов.
HPFS обладает повышенной отказоустойчивостью по сравнению с FAT. Если на диске с FAT оказалась стертой таблица распределения файлов, то скорее всего окажутся потерянными все данные, которые находятся вне корневого каталога. В системе HPFS вместо таблицы размещения файлов применяется битовый массив, который содержит флаг, помечающий используемые секторы. Если область битового массива будет разрушена, пользователь этого не заметит, даже если это случится во время работы системы. F-узел файла также содержит информацию о размещении каждого файла. Поэтому область битового массива может быть восстановлена после поиска этой информации в F-узлах. Пользователь не увидит даже предупреждения - поиск выполняется автоматически. Этот процесс может быть запущен и с помощью утилиты CHKDSK, которая сравнивает битовый массив с информацией для файла о принадлежащих ему секторах.
Если при чтении битового массива обнаруживается ошибка, то создается новый битовый массив.
В системе FAT при порче каталогов теряются указатели на начало цепочки кластеров каждого файла. Можно соединить отдельные кластеры в файл, но многое придется делать в ручную. Так как утилиты, подобные CHKDSK, не знают имени файлов, то для того, чтобы восстановить их старые имена, придется загружать файлы в текстовый редактор и пытаться определить, что они из себя представляют.
При работе с HPFS в случае потери каталога у каждого файла из этого каталога теряется лишь дата последней операции записи в файл и иных изменений, дата создания и длинное имя файла (символы, следующие за первыми пятнадцатью). Элемент каталога - это всего лишь указатель на F-узел. В F-узле хранятся первые 15 символов имени файла (плюс информация о том, имелись ли в имени файла другие символы, кроме первых 15) и прочая информация, нужная для доступа к файлу. Утилиты восстановления могут впоследствии найти в F- узле сведения о том или ином файле. Эта избыточность, обеспечиваемая каталогом и F-узлами, значительно увеличивает шансы на восстановление данных. CHKDSK в настоящее время - единственная утилита восстановления, поставляемая с OS/2, которая, к сожалению, пока не использует всю имеющуюся информацию.
HPFS не налагает ограничений на максимальный размер файла, но OS/2 в настоящее время устанавливает предел в 2 Гбайта на один файл. Цель HPFS - доведение размера раздела до 2 Тбайт, но сегодня имеется ограничение в 64 Гбайта, поскольку некоторые части системы HPFS до сих пор остаются 16-разрядными.
реализован механизм виртуальной файловой
В UNIX System V Release 4 реализован механизм виртуальной файловой системы VFS (Virtual File System), который позволяет ядру системы одновременно поддерживать несколько различных типов файловых систем. Механизм VFS поддерживает для ядра некоторое абстрактное представление о файловой системе, скрывая от него конкретные особенности каждой файловой системы.
Типы файловых систем, поддерживаемых в UNIX System V Release 4:
s5 - традиционная файловая система UNIX System V, поддерживаемая в ранних версиях UNIX System V от AT&T;
ufs - файловая система, используемая по умолчанию в UNIX System V Release 4, которая ведет происхождение от файловой системы SunOS, которая в свою очередь, происходит от файловой системы Berkeley Fast File System (FFS);
nfs - адаптация известной файловой системы NFS фирмы Sun Microsystems, которая позволяет разделять файлы и каталоги в гетерогенных сетях;
rfs - файловая система Remote File Sharing из UNIX System V Release 3. По функциональным возможностям близка к NFS, но требует на каждом компьютере установки UNIX System V Release 3 или более поздних версий этой ОС;
Veritas - отказоустойчивая файловая система с транзакционным механизмом операций;
specfs - этот новый тип файловой системы обеспечивает единый интерфейс ко всем специальным файлам, описываемым в каталоге /dev;
fifofs - эта новая файловая система использует механизм VFS для реализации файлов FIFO, также известных как конвейеры (pipes), в среде STREAMS;
bfs - загрузочная файловая система. Предназначена для быстрой и простой загрузки и поэтому представляет собой очень простую плоскую файловую систему, состоящую из одного каталога;
/proс - файловая система этого типа обеспечивает доступ к образу адресного пространства каждого активного процесса системы, обычно используется для отладки и трассировки;
/dev/fd - этот тип файловой системы обеспечивает удобный метод ссылок на дескрипторы открытых файлов.
Не во всех коммерческих реализациях поддерживаются все эти файловые системы, отдельные производители могут предоставлять только некоторые из них.
Файлы, отображенные в памяти
Побочным продуктом новой архитектуры виртуальной памяти UNIX System V Release 4 является возможность отображать содержимое файла (или устройства) в виде последовательности байтов в виртуальное адресное пространство процесса. Это упрощает процедуру доступа процесса к данным.
Физическая организация файла
В общем случае файл может располагаться в несмежных блоках дисковой памяти. Логическая последовательность блоков в файле задается набором из 13 элементов. Первые 10 элементов предназначаются для непосредственного указания номеров первых 10 блоков файла. Если размер файла превышает 10 блоков, то в 11 элементе указывается номер блока, в котором содержится список следующих 128 блоков файла. Если файл имеет размер более, чем 10+128 блоков, то используется 12-й элемент, содержащий номер блока, в котором указываются номера 128 блоков, каждый из которых может содержать еще по 128 номеров блоков файла. Таким образом, 12-й элемент используется для двухуровневой косвенной адресации. В случае, если файл больше, чем 10+128+1282 блоков, то используется 13 элемент для трехуровневой косвенной адресации. При таком способе адресации предельный размер файла составляет 2 113 674 блока. Традиционная файловая система s5 поддерживает размеры блоков 512, 1024 или 2048 байт.
Физическая организация и адрес файла
Физическая организация файла описывает правила расположения файла на устройстве внешней памяти, в частности на диске. Файл состоит из физических записей - блоков. Блок - наименьшая единица данных, которой внешнее устройство обменивается с оперативной памятью. Непрерывное размещение - простейший вариант физической организации (рисунок 2.34,а), при котором файлу предоставляется последовательность блоков диска, образующих единый сплошной участок дисковой памяти. Для задания адреса файла в этом случае достаточно указать только номер начального блока. Другое достоинство этого метода - простота. Но имеются и два существенных недостатка. Во-первых, во время создания файла заранее не известна его длина, а значит не известно, сколько памяти надо зарезервировать для этого файла, во-вторых, при таком порядке размещения неизбежно возникает фрагментация, и пространство на диске используется не эффективно, так как отдельные участки маленького размера (минимально 1 блок) могут остаться не используемыми.
Следующий способ физической организации - размещение в виде связанного списка блоков дисковой памяти (рисунок 2.34,б ). При таком способе в начале каждого блока содержится указатель на следующий блок. В этом случае адрес файла также может быть задан одним числом - номером первого блока. В отличие от предыдущего способа, каждый блок может быть присоединен в цепочку какого-либо файла, следовательно фрагментация отсутствует. Файл может изменяться во время своего существования, наращивая число блоков. Недостатком является сложность реализации доступа к произвольно заданному месту файла: для того, чтобы прочитать пятый по порядку блок файла, необходимо последовательно прочитать четыре первых блока, прослеживая цепочку номеров блоков. Кроме того, при этом способе количество данных файла, содержащихся в одном блоке, не равно степени двойки (одно слово израсходовано на номер следующего блока), а многие программы читают данные блоками, размер которых равен степени двойки.
Рис. 2.34.
Физическая организация файла
а - непрерывное размещение; б - связанный список блоков;
в - связанный список индексов; г - перечень номеров блоков
Популярным способом, используемым, например, в файловой системе FAT операционной системы MS-DOS, является использование связанного списка индексов. С каждым блоком связывается некоторый элемент - индекс. Индексы располагаются в отдельной области диска (в MS-DOS это таблица FAT). Если некоторый блок распределен некоторому файлу, то индекс этого блока содержит номер следующего блока данного файла. При такой физической организации сохраняются все достоинства предыдущего способа, но снимаются оба отмеченных недостатка: во-первых, для доступа к произвольному месту файла достаточно прочитать только блок индексов, отсчитать нужное количество блоков файла по цепочке и определить номер нужного блока, и, во-вторых, данные файла занимают блок целиком, а значит имеют объем, равный степени двойки.
В заключение рассмотрим задание физического расположения файла путем простого перечисления номеров блоков, занимаемых этим файлом. ОС UNIX использует вариант данного способа, позволяющий обеспечить фиксированную длину адреса, независимо от размера файла. Для хранения адреса файла выделено 13 полей. Если размер файла меньше или равен 10 блокам, то номера этих блоков непосредственно перечислены в первых десяти полях адреса. Если размер файла больше 10 блоков, то следующее 11-е поле содержит адрес блока, в котором могут быть расположены еще 128 номеров следующих блоков файла. Если файл больше, чем 10+128 блоков, то используется 12-е поле, в котором находится номер блока, содержащего 128 номеров блоков, которые содержат по 128 номеров блоков данного файла. И, наконец, если файл больше 10+128+128(128, то используется последнее 13-е поле для тройной косвенной адресации, что позволяет задать адрес файла, имеющего размер максимум 10+ 128 + 128(128 + 128(128(128.
Физическая организация устройств ввода-вывода
Устройства ввода-вывода делятся на два типа: блок-ориентированные устройства и байт-ориентированные устройства. Блок-ориентированные устройства хранят информацию в блоках фиксированного размера, каждый из которых имеет свой собственный адрес. Самое распространенное блок-ориентированное устройство - диск. Байт-ориентированные устройства не адресуемы и не позволяют производить операцию поиска, они генерируют или потребляют последовательность байтов. Примерами являются терминалы, строчные принтеры, сетевые адаптеры. Однако некоторые внешние устройства не относятся ни к одному классу, например, часы, которые, с одной стороны, не адресуемы, а с другой стороны, не порождают потока байтов. Это устройство только выдает сигнал прерывания в некоторые моменты времени.
Внешнее устройство обычно состоит из механического и электронного компонента. Электронный компонент называется контроллером устройства или адаптером. Механический компонент представляет собственно устройство. Некоторые контроллеры могут управлять несколькими устройствами. Если интерфейс между контроллером и устройством стандартизован, то независимые производители могут выпускать совместимые как контроллеры, так и устройства.
Операционная система обычно имеет дело не с устройством, а с контроллером. Контроллер, как правило, выполняет простые функции, например, преобразует поток бит в блоки, состоящие из байт, и осуществляют контроль и исправление ошибок. Каждый контроллер имеет несколько регистров, которые используются для взаимодействия с центральным процессором. В некоторых компьютерах эти регистры являются частью физического адресного пространства. В таких компьютерах нет специальных операций ввода-вывода. В других компьютерах адреса регистров ввода-вывода, называемых часто портами, образуют собственное адресное пространство за счет введения специальных операций ввода-вывода (например, команд IN и OUT в процессорах i86).
ОС выполняет ввод-вывод, записывая команды в регистры контроллера. Например, контроллер гибкого диска IBM PC принимает 15 команд, таких как READ, WRITE, SEEK, FORMAT и т.д. Когда команда принята, процессор оставляет контроллер и занимается другой работой. При завершении команды контроллер организует прерывание для того, чтобы передать управление процессором операционной системе, которая должна проверить результаты операции. Процессор получает результаты и статус устройства, читая информацию из регистров контроллера.
Физическая структура тома
Физический носитель, который доступен для приложений с помощью средств тома NetWare, состоит из блоков. Блок тома соответствует последовательности секторов физического носителя. Стандартный размер блока тома - 4K (8 секторов), но возможны блоки и больших размеров. Том NetWare - это массив блоков, а каждый блок - это массив секторов.
Блоки тома должны быть связаны с реальным физическим носителем. Этот носитель состоит из сегментов областей физического носителя, которые являются разделами (partitions), подготовленными для использования как части тома NetWare.
Таким образом, базовая структура тома NetWare включает:
Сегмент физического носителя, который подготовлен как раздел NetWare;
Секторы физического носителя, поддерживаемые контроллером диска;
Блоки, каждый из которыхпредставляет собой массив секторов;
Том, представляет собой массив блоков.
Том NetWare может быть многосегментным. Поэтому физический носитель тома может состоять из нескольких дисководов.
Многосегментные тома имеют следующую структуру:
Том может включать до 32 сегментов;
Отдельный физический носитель может состоять максимум из 8 сегментов, относящихся к одному или нескольким томам.
Размещение сегментов одного тома на разных дисках позволяет осуществлять операции чтения и записи различных частей этого тома одновременно, что повышает скорость доступа к данным. Однако при размещении сегментов тома на нескольких дисках требуется зеркальное отображение дисков для защиты информации при отказе какого-либо диска, иначе такой отказ приведет к потере одного или нескольких томов.
Таблица, которая описывает сегмент, называется таблицей определения тома Volume Definition Table (VDT). В этой таблице содержится имя тома, размер тома и информация о расположении сегментов тома на различных дисках. Каждый том NetWare содержит четыре копии (для обеспечения отказоустойчивости) таблицы VDT в каждом разделе NetWare диска. Кроме таблиц VDT раздел NetWare содержит область переназначения дефектных блоков Hot Fix, остальная часть раздела NetWare отводится под сегменты, которые могут принадлежать различным томам.
На сервере NetWare должен быть один диск, содержащий раздел DOS. Этот раздел является активным и с него после выполнения стартового командного файла DOS autoexec.bat автоматически стартует ОС NetWare.
Форматы сообщений
Как уже было сказано, тело сообщения может быть простым или сложным, в зависимости от значения управляющего бита заголовка. Структура сложного сообщения показана на рисунке 6.11. Тело сложного сообщения состоит из последовательности пар (дескриптор, поле данных). Каждый дескриптор несет информацию о том, что находится в поле данных, следующим непосредственно за дескриптором. Дескриптор может иметь два формата, различающихся только количеством бит в каждом его поле. Обычный формат дескриптора приведен на рисунке 6.12. Дескриптор определяет тип последующих данных, их длину, и количество однотипных данных (поле может содержать некоторое число данных одного типа). Возможны такие типы данны, как последовательность бит и байт, целое число различной длины, неструктурированное машинное слово, булевское значение, число с плавающей запятой, строка и мандат (право доступа). Имея такую информацию, система может попытаться выполнить преобразование данных между машинами, если они имеют различные внутренние представления данных. Это преобразование выполняется не ядром, а сервером сетевых сообщений (описан ниже). Преобразование данных выполняется и для простых сообщений (также этим сервером).
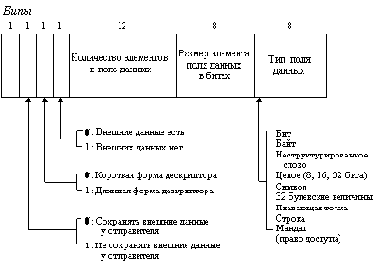
Рис. 6.12. Дескриптор комплексного сообщения
Одним из наиболее интересных типов данных, которые могут содержаться в поле данных сообщения, является мандат. Используя сложные сообщения, можно копировать или передавать мандаты доступа от одного процесса другому. Так как в Mach права доступа являются защищенными объектами ядра, то для их передачи нужен защищенный механизм.
Этот механизм состоит в следующем. Дескриптор может определить, что слово, стоящее в сообщении непосредственно за ним, содержит имя одного из прав доступа отправителя, и что это право нужно переслать процессу-получателю и вставить в его список прав. Этот дескриптор также определяет, должно ли право копироваться (то есть оригинал остается нетронутым) или же перемещаться (оригинал удаляется).
Кроме того, некоторые значения характеристики дескриптора Тип поля данных указывают ядру на то, что нужно модифицировать право при копировании или передаче.
Например, право ПОЛУЧИТЬ может трансформироваться в право ПОСЛАТЬ или ПОСЛАТЬ-ОДИН-РАЗ, так что получатель сможет посылать ответ через порт, к которому у отправителя есть только право ПОЛУЧИТЬ. Действительно, нормальным способом установления взаимодействия между двумя процессами является создание одним из них порта, а затем отправка мандата ПОЛУЧИТЬ для этого порта другому процессу, превращая его в мандат ПОСЛАТЬ по дороге.

Рис. 6.13. (а) Ситуация перед отправкой мандата; (б) Ситуация после его прибытия
Чтобы увидеть, как работает механизм передачи прав, рассмотрим случай, представленный на рисунке 6.13,а.
Мы видим два процесса, А и В, имеющие мандат 3 и 1 соответственно. Все права являются правом только ПОЛУЧИТЬ. Нумерация начинается с 1, так как значение 0 обозначает нуль-порт. Одна из нитей процесса А отправляет сообщение процессу В, и в этом сообщении содержится мандат 3.
Когда сообщение прибывает, ядро проверяет заголовок и видит, что это сложное сообщение. Затем ядро начинает обрабатывать дескрипторы в теле сообщения, один за другим. В этом примере сообщение содержит только один дескриптор, описывающий мандат и инструкции ядру, что его нужно превратить в мандат ПОСЛАТЬ (или, может быть ПОСЛАТЬ-ОДИН-РАЗ). Ядро выделяет одну свободную запись в списке права доступа получателя, например, запись номер 2 в данном случае, и модифицирует сообщение таким образом. что слово, следующее за дескриптором, теперь содержит значение 2, а не 3. Когда приемник получает сообщение, то он видит, что оно содержит новое право, с именем (индексом) 2. Он может использовать его немедленно, для отправки ответа.
Имеется еще один интересный тип данных, которые может передавать сообщение: внешние данные (out-of-line). Эти данные не содержатся непосредственно в сообщении, а описаны как область виртуального адресного пространства отправителя. Тем самым в Mach обеспечивается возможность передачи в пределах машины большого количества данных без их физического копирования. Слово, следующее за дескриптором внешних данных, содержит адрес, а размер и количество полей дает 20-битный счетчик байтов.
Все вместе это и определяет область виртуального адресного пространства. Для больших областей используется увеличенная форма дескриптора.
Когда сообщение прибывает к получателю, ядро выбирает нераспределенную часть виртуального адресного пространства того же размера, что и внешние данные, и отображает страницы отправителя в адресное пространство получателя, помечая их как страницы с копированием-при-записи. Адрес, следующий за дескриптором, изменяется и теперь указывает на область в адресном пространстве получателя. В зависимости от значения бита дескриптора область может быть удалена из адресного пространства отправителя или нет.
Хотя этот метод очень эффективен при копировании данных между процессами в пределах одной машины, он непригоден для использования в сети, так как страницы придется копировать, даже если они имеют режим только-для-чтения. То есть возможность логического копирования без физического теряется. Метод копирование-при-записи требует, чтобы сообщение было выровнено по границе страницы и составляло целое число страниц. Частично использованные страницы также позволяют получателю видеть данные, которые ему не следует видеть.
Сетевые операционные системы
В дополнение к средствам идентификации пользователей по имени и паролю UnixWare имеет развитые средства управления доступом к ресурсам системы. Имеется возможность полного протоколирования работы системы, включая регистрацию выполняемых команд и доступа к информации.
Гетерогенность
Только небольшое количество сетей обладает однородностью (гомогенностью) программного и аппаратного обеспечения. Однородными чаще являются сети, которые состоят из небольшого количества компонентов от одного производителя.
Немногие организации имеют сети, составленные из оборудования, например, только IBM или DEC. Дни сетей от одного производителя миновали. Нормой сегодняшнего дня являются сети неоднородные (гетерогенные), которые состоят из различных рабочих станций, операционных систем и приложений, а для реализации взаимодействия между компьютерами используют различные протоколы. Разнообразие всех компонентов, из которых строится сеть, порождает еще большее разнообразие структур сетей, получающихся из этих компонентов. А если продолжить далее, и рассмотреть более сложные образования, получающиеся в результате объединения отдельных сетей в единую большую сеть, то становится понятным то множество проблем, связанных с проектированием, администрированием и управлением такой гетерогенной интерсетью. В идеале это объединение неоднородных сетей должно быть прозрачным для пользователя.
Так как сети создавались большей частью случайным образом, то приобретенные компьютеры и ОС отвечают, как правило, индивидуальным потребностям группы пользователей. Сети отдела строились для решения конкретных задач групп сотрудников. Например, инженерный отдел мог выбрать рабочие станции SPARC фирмы Sun Microsystems, соединенные сетью Ethernet, потому что им нужны были приложения, работающие только в среде UNIX. Разделение файлов при этом реализовывалось с помощью TCP/IP и NFS. В отделе продаж той же самой организации уже могли быть куплены компьютеры PS/2, установлена сеть Token Ring и операционная система NetWare для решения их собственных задач: ведения базы данных о клиентах, подготовки писем, разработки коммерческих предложений. Затем в рекламном отделе были выбраны компьютеры Macintosh, поскольку они наилучшим образом подходят для создания презентационных материалов. Macintosh'и соединены посредством LocalTalk, а файлы и принтеры разделяются с использованием AppleTalk. Отдел, отвечающий за автоматизацию предприятия, должен интегрировать все эти плохо совместимые системы в единый прозрачный организм.
Добавление в вычислительную сеть новых, чужеродных элементов может происходить и при всякой значительной реорганизации предприятия, например, при смене владельца, что для нашей страны сейчас тоже становится весьма обычным делом. В этом случае вновь приобретенное предприятие и его вычислительное оборудование также должно быть интегрировано в общую структуру предприятия нового владельца.
Глобальная служба справочников сетевых ресурсов
Главным отличием ОС NetWare v 4.0х от предыдущих версий является введение единого для всех файл-серверов сетевого каталога (справочника сетевых ресурсов) - NetWare Directory Services (NDS), имеющего иерархическую древовидную структуру и основанного на международном стандарте X.500. В предыдущих версиях NetWare база данных сетевых ресурсов, называемая Bindery, была уникальна для каждого файл-сервера. Поэтому для получения доступа к нужным ресурсам пользователь должен был подключаться к предоставляющему этот ресурс файл-серверу.
В NetWare v 4.0х все сетевые ресурсы, такие как файлы, принтеры, прикладные программы и т.д. составляют единую логическую сущность, не зависящую от их физического размещения. Пользователю достаточно один раз подключиться к сети, чтобы получить доступ ко всем ее ресурсам, которыми он имеет право пользоваться. Пользователи и прикладные программы, которые обращаются к NDS для получения доступа к необходимым ресурсам, могут и не знать, как распределены эти ресурсы по серверам и подсетям (в отличие от предыдущих версий, где эти ресурсы были жестко "привязаны" к серверам). В NetWare 4.02 значительно расширена и улучшена служба NDS по сравнению с предыдущими версиями NetWare 4.x. Изменена процедура установки NDS, а для простой или не очень сложной структуры описания ресурсов сети обеспечен автоматический режим установки.
H. Интеграция с NetWare
UnixWare обеспечивает полную интеграцию с сетью NetWare, благодаря которой рабочие станции UnixWare имеют доступ к ресурсам (файловая система, принтеры, почта) сети NetWare, как и другие ee клиенты, а остальные пользователи локальной сети получают также терминальный доступ к серверу приложений UnixWare. При этом как на уровне клиента, так и на уровне сервера приложений операционная система UnixWare использует традиционный для NetWare сетевой протокол IPX. Пользователям UnixWare в локальной сети NetWare предоставляются следующие виды поддержки:
прозрачный доступ к файлам, принтерам и электронной почте;
протоколы IPX, SPX и NCP, встроенные в ядро операционной системы;
поддержка протоколов SAP (Service Advertising Protocol) и RIP (Routing Information Protocol);
графический пользовательский интерфейс с функциями NetWare.
I. Поддержка мультипроцессирования
Начиная с версии 2.0, UnixWare поддерживает симметричное мультипроцессирование (SMP). Оба варианта UnixWare 2.01 (Application Server и Personal Edition) поддерживают в базовой поставке 2 симметричных процессора Intel. UnixWare Application Server может поддерживать (за счет добавления модулей поддержки дополнительных процессоров) до 8 процессоров Intel. UnixWare 2.01 является многонитевой операционной системой.
Иерархия запоминающих устройств. Принцип кэширования данных
Память вычислительной машины представляет собой иерархию запоминающих устройств (внутренние регистры процессора, различные типы сверхоперативной и оперативной памяти, диски, ленты), отличающихся средним временем доступа и стоимостью хранения данных в расчете на один бит (рисунок 2.17). Пользователю хотелось бы иметь и недорогую и быструю память. Кэш-память представляет некоторое компромиссное решение этой проблемы.
Рис. 2.17. Иерархия ЗУ
Кэш-память - это способ организации совместного функционирования двух типов запоминающих устройств, отличающихся временем доступа и стоимостью хранения данных, который позволяет уменьшить среднее время доступа к данным за счет динамического копирования в "быстрое" ЗУ наиболее часто используемой информации из "медленного" ЗУ.
Кэш-памятью часто называют не только способ организации работы двух типов запоминающих устройств, но и одно из устройств - "быстрое" ЗУ. Оно стоит дороже и, как правило, имеет сравнительно небольшой объем. Важно, что механизм кэш-памяти является прозрачным для пользователя, который не должен сообщать никакой информации об интенсивности использования данных и не должен никак участвовать в перемещении данных из ЗУ одного типа в ЗУ другого типа, все это делается автоматически системными средствами.
Рассмотрим частный случай использования кэш-памяти для уменьшения среднего времени доступа к данным, хранящимся в оперативной памяти. Для этого между процессором и оперативной памятью помещается быстрое ЗУ, называемое просто кэш-памятью (рисунок 2.18). В качестве такового может быть использована, например, ассоциативная память. Содержимое кэш-памяти представляет собой совокупность записей обо всех загруженных в нее элементах данных. Каждая запись об элементе данных включает в себя адрес, который этот элемент данных имеет в оперативной памяти, и управляющую информацию: признак модификации и признак обращения к данным за некоторый последний период времени.
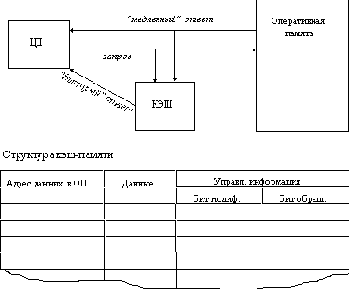
Рис. 2.18. Кэш-память
В системах, оснащенных кэш-памятью, каждый запрос к оперативной памяти выполняется в соответствии со следующим алгоритмом:
Просматривается содержимое кэш-памяти с целью определения, не находятся ли нужные данные в кэш-памяти; кэш-память не является адресуемой, поэтому поиск нужных данных осуществляется по содержимому - значению поля "адрес в оперативной памяти", взятому из запроса.
Если данные обнаруживаются в кэш-памяти, то они считываются из нее, и результат передается в процессор.
Если нужных данных нет, то они вместе со своим адресом копируются из оперативной памяти в кэш-память, и результат выполнения запроса передается в процессор. При копировании данных может оказаться, что в кэш-памяти нет свободного места, тогда выбираются данные, к которым в последний период было меньше всего обращений, для вытеснения из кэш-памяти. Если вытесняемые данные были модифицированы за время нахождения в кэш-памяти, то они переписываются в оперативную память. Если же эти данные не были модифицированы, то их место в кэш-памяти объявляется свободным.
На практике в кэш-память считывается не один элемент данных, к которому произошло обращение, а целый блок данных, это увеличивает вероятность так называемого "попадания в кэш", то есть нахождения нужных данных в кэш-памяти.
Покажем, как среднее время доступа к данным зависит от вероятности попадания в кэш. Пусть имеется основное запоминающие устройство со средним временем доступа к данным t1 и кэш-память, имеющая время доступа t2, очевидно, что t2<t1. Обозначим через t среднее время доступа к данным в системе с кэш-памятью, а через p -вероятность попадания в кэш. По формуле полной вероятности имеем:
t = t1((1 - p) + t2(p
Из нее видно, что среднее время доступа к данным в системе с кэш-памятью линейно зависит от вероятности попадания в кэш и изменяется от среднего времени доступа в основное ЗУ (при р=0) до среднего времени доступа непосредственно в кэш-память (при р=1).
В реальных системах вероятность попадания в кэш составляет примерно 0,9.Высокое значение вероятности нахождения данных в кэш-памяти связано с наличием у данных объективных свойств: пространственной и временной локальности.
Пространственная локальность. Если произошло обращение по некоторому адресу, то с высокой степенью вероятности в ближайшее время произойдет обращение к соседним адресам.
Временная локальность. Если произошло обращение по некоторому адресу, то следующее обращение по этому же адресу с большой вероятностью произойдет в ближайшее время.
Все предыдущие рассуждения справедливы и для других пар запоминающих устройств, например, для оперативной памяти и внешней памяти. В этом случае уменьшается среднее время доступа к данным, расположенным на диске, и роль кэш-памяти выполняет буфер в оперативной памяти.
Имена файлов
Файлы идентифицируются именами. Пользователи дают файлам символьные имена, при этом учитываются ограничения ОС как на используемые символы, так и на длину имени. До недавнего времени эти границы были весьма узкими. Так в популярной файловой системе FAT длина имен ограничивается известной схемой 8.3 (8 символов - собственно имя, 3 символа - расширение имени), а в ОС UNIX System V имя не может содержать более 14 символов. Однако пользователю гораздо удобнее работать с длинными именами, поскольку они позволяют дать файлу действительно мнемоническое название, по которому даже через достаточно большой промежуток времени можно будет вспомнить, что содержит этот файл. Поэтому современные файловые системы, как правило, поддерживают длинные символьные имена файлов. Например, Windows NT в своей новой файловой системе NTFS устанавливает, что имя файла может содержать до 255 символов, не считая завершающего нулевого символа.
При переходе к длинным именам возникает проблема совместимости с ранее созданными приложениями, использующими короткие имена. Чтобы приложения могли обращаться к файлам в соответствии с принятыми ранее соглашениями, файловая система должна уметь предоставлять эквивалентные короткие имена (псевдонимы) файлам, имеющим длинные имена. Таким образом, одной из важных задач становится проблема генерации соответствующих коротких имен.
Длинные имена поддерживаются не только новыми файловыми системами, но и новыми версиями хорошо известных файловых систем. Например, в ОС Windows 95 используется файловая система VFAT, представляющая собой существенно измененный вариант FAT. Среди многих других усовершенствований одним из главных достоинств VFAT является поддержка длинных имен. Кроме проблемы генерации эквивалентных коротких имен, при реализации нового варианта FAT важной задачей была задача хранения длинных имен при условии, что принципиально метод хранения и структура данных на диске не должны были измениться.
Обычно разные файлы могут иметь одинаковые символьные имена. В этом случае файл однозначно идентифицируется так называемым составным именем, представляющем собой последовательность символьных имен каталогов. В некоторых системах одному и тому же файлу не может быть дано несколько разных имен, а в других такое ограничение отсутствует. В последнем случае операционная система присваивает файлу дополнительно уникальное имя, так, чтобы можно было установить взаимно-однозначное соответствие между файлом и его уникальным именем. Уникальное имя представляет собой числовой идентификатор и используется программами операционной системы. Примером такого уникального имени файла является номер индексного дескриптора в системе UNIX.
В UNIX для файла существует три типа имени - краткое, полное и относительное. Краткое имя идентифицирует файл в пределах одного каталога. Оно может состоять не более чем из 14 символов и содержать так называемый суффикс, отделяемый точкой. Полное имя однозначно определяет файл. Оно состоит из цепочки имен каталогов, через которые проходит маршрут от корневого каталога до данного файла. Имена каталогов разделяются символами "/", при этом имя корневого каталога не указывается, например, /mnt/rk2/test.c, где mnt и rk2 - имена каталогов, а test.c - имя файла. Каждому полному имени в ОС соответствует только один файл, однако файл может иметь несколько различных имен, так как ссылки на один и тот же файл могут содержаться в разных каталогах (жесткие связи). Относительное имя файла связано с понятием "текущий каталог", то есть каталог, имя которого задавать не нужно, так как оно подразумевается по умолчанию. Имя файла относительно текущего каталога называется относительным. Оно представляет собой цепочку имен каталогов, через которые проходит маршрут от текущего каталога до данного файла. Относительное имя в отличие от полного не начинается с символа "/". Так, если в предыдущем примере принять за текущий каталог /mnt, то относительное имя файла test.c будет rk2/test.c.
Именованные конвейеры
Конвейер - это средство обмена данными между процессами. Конвейер буферизует данные, поступающие на его вход, таким образом, что процесс, читающий данные на его выходе, получает их в порядке "первый пришел - первый вышел" (FIFO). В ранних версиях UNIX для обмена данными между процессами использовались неименованные конвейеры - pipes, которые представляли собой очереди байт в оперативной памяти. Однако, из-за отсутствия имен, такие конвейеры могли использоваться только для передачи данных между родственными процессами, получившими указатель на конвейер в результате копирования сегмента данных из адресного пространства процесса-прародителя. Именованные конвейеры позволяют обмениваться данными произвольной паре процессов, т.к. каждому такому конвейеру соответствует файл на диске. Никакие данные не связываются с файлом-конвейером, но все равно в каталоге содержится запись о нем, и он имеет индексный дескриптор. В UNIX System V Release 4 конвейеры реализуются с использованием коммуникационных модулей STREAMS.
Интерфейс файлового сервиса
Для любого файлового сервиса, независимо от того, централизован он или распределен, самым главным является вопрос, что такое файл? Во многих системах, таких как UNIX и MS DOS, файл - это неинтерпретируемая последовательность байтов. Значение и структура информации в файле является заботой прикладных программ, операционную систему это не интересует.
В ОС мейнфреймов поддерживаются разные типы логической организации файлов, каждый с различными свойствами. Файл может быть организован как последовательность записей, и у операционной системы имеются вызовы, которые позволяют работать на уровне этих записей. Большинство современных распределенных файловых систем поддерживают определение файла как последовательности байтов, а не последовательности записей. Файл характеризуется атрибутами: именем, размером, датой создания, идентификатором владельца, адресом и другими.
Важным аспектом файловой модели является возможность модификации файла после его создания. Обычно файлы могут модифицироваться, но в некоторых распределенных системах единственными операциями с файлами являются СОЗДАТЬ и ПРОЧИТАТЬ. Такие файлы называются неизменяемыми. Для неизменяемых файлов намного легче осуществить кэширование файла и его репликацию (тиражирование), так как исключается все проблемы, связанные с обновлением всех копий файла при его изменении.
Файловый сервис может быть разделен на два типа в зависимости от того, поддерживает ли он модель загрузки-выгрузки или модель удаленного доступа. В модели загрузки-выгрузки пользователю предлагаются средства чтения или записи файла целиком. Эта модель предполагает следующую схему обработки файла: чтение файла с сервера на машину клиента, обработка файла на машине клиента и запись обновленного файла на сервер. Преимуществом этой модели является ее концептуальная простота. Кроме того, передача файла целиком очень эффективна. Главным недостатком этой модели являются высокие требования к дискам клиентов. Кроме того, неэффективно перемещать весь файл, если нужна его маленькая часть.
Другой тип файлового сервиса соответствует модели удаленного доступа, которая предполагает поддержку большого количества операций над файлами: открытие и закрытие файлов, чтение и запись частей файла, позиционирование в файле, проверка и изменение атрибутов файла и так далее. В то время как в модели загрузки-выгрузки файловый сервер обеспечивал только хранение и перемещение файлов, в данном случае вся файловая система выполняется на серверах, а не на клиентских машинах. Преимуществом такого подхода являются низкие требования к дисковому пространству на клиентских машинах, а также исключение необходимости передачи целого файла, когда нужна только его часть.
Интерфейс сервиса каталогов
Природа сервиса каталогов не зависит от типа используемой модели файлового сервиса. В распределенных системах используются те же принципы организации каталогов, что и в централизованных, в том числе многоуровневая организация каталогов.
Принципиальной проблемой, связанной со способами именования файлов, является обеспечение прозрачности. В данном контексте прозрачность понимается в двух слабо различимых смыслах. Первый - прозрачность расположения - означает, что имена не дают возможности определить месторасположение файла. Например, имя /server1/dir1/ dir2/x говорит, что файл x расположен на сервере 1, но не указывает, где расположен этот сервер. Сервер может перемещаться по сети, а полное имя файла при этом не меняется. Следовательно, такая система обладает прозрачностью расположения.
Предположим, что файл x очень большой, а на сервере 1 мало места, предположим далее, что на сервере 2 места много. Система может захотеть переместить автоматически файл x на сервер 2. К сожалению, когда первый компонент всех имен - это имя сервера, система не может переместить файл на другой сервер автоматически, даже если каталоги dir1 и dir2 находятся на обоих серверах. Программы, имеющие встроенные строки имен файлов, не будут правильно работать в этом случае. Система, в которой файлы могут перемещаться без изменения имен, обладает свойством независимости от расположения. Распределенная система, которая включает имена серверов или машин непосредственно в имена файлов, не является независимой от расположения. Система, базирующаяся на удаленном монтировании, также не обладает этим свойством, так как в ней невозможно переместить файл из одной группы файлов в другую и продолжать после этого пользоваться старыми именами. Независимости от расположения трудно достичь, но это желаемое свойство распределенной системы.
Большинство распределенных систем используют какую-либо форму двухуровневого именования: на одном уровне файлы имеют символические имена, такие как prog.c, предназначенные для использования людьми, а на другом - внутренние, двоичные имена, для использования самой системой. Каталоги обеспечивают отображение между двумя этими уровнями имен. Отличием распределенных систем от централизованных является возможность соответствия одному символьному имени нескольких двоичных имен. Обычно это используется для представления оригинального файла и его архивных копий. Имея несколько двоичных имен, можно при недоступности одной из копий файла получить доступ к другой. Этот метод обеспечивает отказоустойчивость за счет избыточности.
Использование магистрального протокола
Хорошим решением был бы переход на единый стек протоколов, но вряд ли эта перспектива осуществится в ближайшем будущем. Попытка введения единого стека коммуникационных протоколов сделана в 1990 году правительством США, которое обнародовало программу GOSIP - Government OSI Profile, в соответствии с которой стек протоколов OSI должен стать общим знаменателем для всех сетей, устанавливаемых в правительственных организациях США. Но, понимая бесполезность силовых мер, программа GOSIP не ставит задачу немедленного перехода на стек OSI, а принуждает пока к использованию этого стека в качестве "второго языка" правительственных сетей, наряду с родным, первым.
История и общая характеристика семейства операционных систем UNIX
UNIX имеет долгую и интересную историю. Начавшись как несерьезный и почти "игрушечный" проект молодых исследователей, UNIX стал многомиллионной индустрией, включив в свою орбиту университеты, многонациональные корпорации, правительства и международные организации стандартизации.
UNIX зародился в лаборатории Bell Labs фирмы AT&T более 20 лет назад. В то время Bell Labs занималась разработкой многопользовательской системы разделения времени MULTICS (Multiplexed Information and Computing Service) совместно с MIT и General Electric, но эта система потерпела неудачу, отчасти из-за слишком амбициозных целей, не соответствовавших уровню компьютеров того времени, а отчасти и из-за того, что она разрабатывалась на языке PL/1, а компилятор PL/1 задерживался и вообще плохо работал после своего запоздалого появления. Поэтому Bell Labs вообще отказалась от участия в проекте MULTICS, что дало возможность одному из ее исследователей, Кену Томпсону, заняться поисковой работой в направлении улучшения операционной среды Bell Labs. Томпсон, а также сотрудник Bell Labs Денис Ритчи и некоторые другие разрабатывали новую файловую систему, многие черты которой вели свое происхождение от MULTICS. Для проверки новой файловой системы Томпсон написал ядро ОС и некоторые программы для компьютера GE-645, который работал под управлением мультипрограммной системы разделения времени GECOS. У Кена Томпсона была написанная им еще во времена работы над MULTICS игра "Space Travel" - "Космическое путешествие". Он запускал ее на компьютере GE-645, но она работала на нем не очень хорошо из-за невысокой эффективности разделения времени. Кроме этого, машинное время GE-645 стоило слишком дорого. В результате Томпсон и Ритчи решили перенести игру на стоящую в углу без дела машину PDP-7 фирмы DEC, имеющую 4096 18-битных слов, телетайп и хороший графический дисплей. Но у PDP-7 было неважное программное обеспечение, и, закончив перенос игры, Томпсон решил реализовать на PDP-7 ту файловую систему, над который он работал на GE-645.
Из этой работы и возникла первая версия UNIX, хотя она и не имела в то время никакого названия. Но она уже включала характерную для UNIX файловую систему, основанную на индексных дескрипторах inode, имела подсистему управления процессами и памятью, а также позволяла двум пользователям работать в режиме разделения времени. Система была написана на ассемблере. Имя UNIX (Uniplex Information and Computing Services) было дано ей еще одним сотрудником Bell Labs, Брайаном Керниганом, который первоначально назвал ее UNICS, подчеркивая ее отличие от многопользовательской MULTICS. Вскоре UNICS начали называть UNIX.
Первыми пользователями UNIX'а стали сотрудники отдела патентов Bell Labs, которые нашли ее удобной средой для создания текстов.
Большое влияние на судьбу UNIX оказала перепись ее на языке высокого уровня С, разработанного Денисом Ритчи специально для этих целей. Это произошло в 1973 году, UNIX насчитывал к этому времени уже 25 инсталляций, и в Bell Labs была создана специальная группа поддержки UNIX.
Широкое распространение UNIX получил с 1974 года, после описания этой системы Томпсоном и Ритчи в компьютерном журнале CACM. UNIX получил широкое распространение в университетах, так как для них он поставлялся бесплатно вместе с исходными кодами на С. Широкое распространение эффективных C-компиляторов сделало UNIX уникальной для того времени ОС из-за возможности переноса на различные компьютеры. Университеты внесли значительный вклад в улучшение UNIX и дальнейшую его популяризацию. Еще одним шагом на пути получения признания UNIX как стандартизованной среды стала разработка Денисом Ритчи библиотеки ввода-вывода stdio. Благодаря использованию этой библиотеки для компилятора С, программы для UNIX стали легко переносимыми.
Рис. 5.1. История развития UNIX
Широкое распространение UNIX породило проблему несовместимости его многочисленных версий. Очевидно, что для пользователя весьма неприятен тот факт, что пакет, купленный для одной версии UNIX, отказывается работать на другой версии UNIX.
Периодически делались и делаются попытки стандартизации UNIX, но они пока имели ограниченный успех. Процесс сближения различных версий UNIX и их расхождения носит циклический характер. Перед лицом новой угрозы со стороны какой-либо другой операционной системы различные производители UNIX-версий сближают свои продукты, но затем конкурентная борьба вынуждает их делать оригинальные улучшения и версии снова расходятся. В этом процессе есть и положительная сторона - появление новых идей и средств, улучшающих как UNIX, так и многие другие операционные системы, перенявшие у него за долгие годы его существования много полезного.
На рисунке 5.1 показана упрощенная картина развития UNIX, которая учитывает преемственность различных версий и влияние на них принимаемых стандартов. Наибольшее распространение получили две весьма несовместимые линии версий UNIX: линия AT&T - UNIX System V, и линия университета Berkeley-BSD. Многие фирмы на основе этих версий разработали и поддерживают свои версии UNIX: SunOS и Solaris фирмы Sun Microsystems, UX фирмы Hewlett-Packard, XENIX фирмы Microsoft, AIX фирмы IBM, UnixWare фирмы Novell (проданный теперь компании SCO), и список этот можно еще долго продолжать.
Наибольшее влияние на унификацию версий UNIX оказали такие стандарты как SVID фирмы AT&T, POSIX, созданный под эгидой IEEE, и XPG4 консорциума X/Open. В этих стандартах сформулированы требования к интерфейсу между приложениями и ОС, что дает возможность приложениям успешно работать под управлением различных версий UNIX.
Независимо от версии, общими для UNIX чертами являются:
многопользовательский режим со средствами защиты данных от несанкционированного доступа,
реализация мультипрограммной обработки в режиме разделения времени, основанная на использовании алгоритмов вытесняющей многозадачности (preemptive multitasking),
использование механизмов виртуальной памяти и свопинга для повышения уровня мультипрограммирования,
унификация операций ввода-вывода на основе расширенного использования понятия "файл",
иерархическая файловая система, образующая единое дерево каталогов независимо от количества физических устройств, используемых для размещения файлов,
переносимость системы за счет написания ее основной части на языке C,
разнообразные средства взаимодействия процессов, в том числе и через сеть,
кэширование диска для уменьшения среднего времени доступа к файлам.
Далее мы подробно остановимся на основных концепциях версии UNIX System V Release 4, которая вобрала в себя лучшие черты линий UNIX System V и UNIX BSD.
Версия UNIX System V Release 4 - это незаконченная коммерческая версия операционной системы, т.к. в ее кодах отсутствуют многие системные утилиты, необходимые для успешной эксплуатации ОС, например утилиты администрирования или менеджер графического интерфейса. Версия SVR4 является скорее стандартной реализацией кода ядра, вобравшая в себя наиболее популярные и эффективные решения из различных версий ядра UNIX, такие как виртуальная файловая система VFS, отображаемые в память файлы и т.п. Код SVR4 (частично доработанный) лег в основу многих современных коммерческих версий UNIX, таких как HP-UX, Solaris, AIX и т.д.
