Aladdin
| Тип защиты: | Защита от несанкционированного использования. Метод реализации - электронный ключ |
| Способ преодоления защиты: | Новая версия еще не вскрыта (теоретический способ взлома - эмуляция HASP и анализ исполняемого кода) |
| Аппаратная совместимость (cd/dvd-приводы разных производителей): | - |
| Наличие особой аппаратуры для защиты серии: | Требуется электронный ключ |
| Предоставление SDK для производителей: | ДА |
| Защита мелких партий (CD/R/RW): | ДА |
| Фирма - производитель: | "Аладдин" () |
| Коммерческие продукты, использующие данный вид защиты: | |
| 1С, АСКОН | |
| Особенности защиты: | |
| Защита базируется на использовании внешних электронных ключей, подключаемых к портам компьютеров. Заявлены разные модели HASP для портов USB, , COM. Платы ISA, PCI. Используются мощные уникальные ключи. Защита снабжается SDK. Слабое место защиты - обращение к портам, которые можно эмулировать. Из особенностей SDK можно отметить легкость освоения. При использовании возможностей HASP4 возможно создать защиту высокого уровня. ЕДИНСТВЕННАЯ ИЗ ПРЕДСТАВЛЕННЫХ ЗАЩИТ ИМЕЕТ В НАЛИЧИИ СЕТЕВЫЕ ЛИЦЕНЗИИ |
При выпуске мелких партий продуктов возможно использование защиты с использованием электронных ключей. Недостаток данного метода заключается в стоимости ключа. Самый надежный ключ - является самым дорогим и навороченным.
Разброс цен следующий: от 13,5 у.е. (самый дешевый ключ+большой объем поставки) до 270 у.е. (самый дорогой в кол-ве 1 штуки). Все зависит от модели ключа; сетевой он / не сетевой; размера поставки). В отличии от SF, у "Алладина" имеются сетевые ключи, что позволяет организовать доступ по принципу клиент-сервер.
Стоимость SDK варьируется 25 до 45 у.е., в зависимости от модели ключа - для ключей HASP; для Hardlock - DK - от 30 до 34 у.е., мастер-комплекты (отличаются от DK наличием криптоплаты) - до 104 у.е.
Устанавливать дешевый ключ не выгодно, так как независимо от устойчивости к взлому приложения, ключ очень уязвим. Для программного продукта необходимо выбирать ключ средней и высокой категории, используя все его возможности по максимуму. В итоге получается, что ключом можно защитить программное обеспечение стоимостью выше 200-400 долларов. Стоимость достаточна высока, поэтому данный тип защиты более ориентирован на корпоративный рынок дорогих программных систем.
Анализ рынка средств защиты от копирования и взлома программных средств
, независимый консультант
, независимый консультант
Сокращеный вариант статьи опубликован в Pc Week, #6/2004
Аппаратные ключи
Часто для реализации нераспространения продукта при его эксплуатации используются в электронные ключи (HASP) или Sentinel.
HASP представляет собой программно-аппартный комплекссодержащий код, процедуры или любые другие уникальные данные, по которым защита может идентифицировать легальность запуска.
Современные электронные ключи подключаются практически ко всем портам компьютера: от LPT до USB, а также слотам ISA и PCI, при возникновении такой необходимости.
Основой ключей HASP является специализированная заказная микросхема (микроконтроллер) - ASIC (Application Specific Integrated Circuit), имеющая уникальный для каждого ключа алгоритм работы.
Принцип защиты состоит в том, что в процессе выполнения защищённая программа опрашивает подключённый к компьютеру ключ HASP. Если HASP возвращает правильный ответ и работает по требуемому алгоритму, программа выполняется нормально. В противном случае (по усмотрению), она может завершаться, переключаться в демонстрационный режим или блокировать доступ к каким-либо функциям программы.
Большинство моделей ключей HASP имеют энергонезависимую программно-перезаписываемую память (так называемую EEPROM). В зависимости от реализации HASP память может быть от одного до четырех килобитов).
Наличие энергонезависимой памяти дает возможность программировать HASP, размещая внутри модуля различные процедуры, либо хранить дополнительные ключи, а также:
управлять доступом к различным программным модулям и пакетам программ;
назначать каждому пользователю защищенных программ уникальный номер;
сдавать программы в аренду и распространять их демо-версии с ограничением количества запусков;
хранить в ключе пароли, фрагменты кода программы, значения переменных и другую важную информацию.
У каждого ключа HASP с памятью имеется уникальный опознавательный номер, или идентификатор (ID-number), доступный для считывания защищёнными программами. Идентификаторы позволяют различать пользователей программы. Проверяя в программе идентификатор HASP, пользователь имеет возможность предпринимать те или иные действия в зависимости от наличия конкретного ключа. Идентификатор присваивается электронному ключу в процессе изготовления, что делает невозможным его замену, но гарантирует надежную защиту от повтора. С использованием идентификатора можно шифровать содержимое памяти и использовать возможность ее дистанционного перепрограммирования.
Система HASP позволяет защищать программное обеспечение двумя различными способами: автоматически (стандартно) и вручную (через специальный API).
CD-COPS
| Тип защиты: | Измерение физических характеристик без нанесения особых меток на носитель |
| Способ преодоления защиты: | "Кряк" |
| Аппаратная совместимость (cd/dvd-приводы разных производителей): | Средняя (совместима только с популярными приводами) |
| Наличие особой аппаратуры для защиты серии: | НЕ требуется |
| Предоставление SDK для производителей: | ДА |
| Защита мелких партий (CD/R/RW): | НЕТ |
| Фирма - производитель: | Link Data Security () |
| Коммерческие продукты, использующие данный вид защиты: | |
| Interactive English / De Agostini National encyklopediа Agostini Atlas 99 Agostini Basetera BMM DK Kort Lademanns'99 |
|
| Особенности защиты: | |
| Данная программа пользуется самой эффективной системой защитой от копирования, основанной не на нанесении физических меток, а на способе измерения специфических характеристик CD\DVD-ROM. По словам производителя, система анализирует физический угол между прошлым и текущими логическими блоками на компакт-диске. Слабое место защиты - это сам код, анализирующий углы. Фирме пока не удалось найти эффективного способа противодействия дизассемблерам и отладчикам. |
Цена вопроса
Давайте рассмотрим во что обойдется внедрение защиты.
Дизассемблеры и дамперы
Про дизассемблер было сказано выше, а вот про дампер можно добавить то, что это практически тот же дизассемблер, только транслирует он не файл, находящийся на диске в Ассемблерный код, а содержимое оперативной памяти на тот момент, когда приложение начало нормально исполняться (то есть, пройдены все защиты). Это один из коварных средств взлома, при котором хакеру не надо бороться с механизмами, противодействующими отладке, он лишь ждет, когда приложение закончит все проверки на легальность запуска, проверяя метки на диске, и начинает нормальную работу. В этот момент дампер и снимает "чистенький" код без примесей. К всеобщей радости не все защиты могут просто так себя раскрыть! Об этом поподробнее:
Шифрование. Самый простой и эффективный способ противодействия. Подразумевает, что определенная часть кода никогда не появляется в свободном виде. Код дешифруется только перед передачей ему управления. То есть вся программа или ее часть находится в зашифрованном виде, а расшифровывается только перед тем как исполниться. Соответственно, чтобы проанализировать ее код надо воспользоваться отладчиком, а его работу можно очень и очень осложнить (см. выше)!
Шифрование и дешифрование (динамическое изменение кода). Более продвинутый способ шифрования, который не просто дешифрует часть кода при исполнении, но и шифрует его обратно, как только он был исполнен. При такой защите хакеру придется проводить все время с отладчиком, и взлом защиты затянется на очень и очень долгое время.
Использование виртуальных машин. Еще одна модернизация шифрования. Способ заключается в том, чтобы не просто шифровать и дешифровать целые фрагменты кода целиком, а делать это покомандно, подобно тому, как действует отладчик или виртуальная машина: взять код, преобразовать в машинный и передать на исполнение, и так пока весь модуль не будет исполнен. Этот способ гораздо эффективнее предыдущих, так как функции приложения вообще никогда не бывают открытыми для хакера. Естественно, что его трудно реализовать, но реализовав, можно оградить себя от посягательств любых хакеров. В этом способе кроется также и недостаток - снижение производительности, ведь на подобное транслирование требуется много времени, и, соответственно, способ хорош для защиты только критических участков кода.
Дополнительные способы противодействия
Здесь уже даются общие вводные, ведь защита может быть эффективной только тогда, когда каждый ее модуль написан на совесть с использованием различных ухищрений. То есть все рецепты, о которых говорилось выше, должны в той или иной форме присутствовать в любой системе.
Использовать для хранения данных защиты системные ресурсы Windows: дополнительную память, выделяемую для параметров окон и локальные хранилища потоков. Суть способа состоит в нестандартном использовании стандартных областей, скажем, хранить ключи, пароли… и т.п., совсем не там, где их будут искать при взломе в первую очередь.
Использовать операции сравнения нестандартными способами, во избежание их явного присутствия. Для сравнения есть определенные инструкции микропроцессора, о которых знают и разработчики и хакеры. А если попытаться использовать нестандартные виды сравнения, то можно слегка запутать хакера, ожидающего стандартного ответа.
Избегать обращений к переменным, относящимся к защите напрямую. То есть использовать любые косвенные способы доступа к специальным областям.
Использовать метод "зеркалирования" событий, то есть применять нестандартные действия на стандартные вызовы. Об этом говорилось выше.
Использовать для шифрования надежные, проверенные временем алгоритмы.
Выше перечислены даже не основные, а общеизвестные подходы. Об оригинальных разработках мы узнаем позже, как только хакеры смогут взломать очередную уникальную защиту.
Информационная безопасность
Рекомендации, такие же, как и выше. Необходимо использовать SDK защиты. Особенно, в игровой программе необходимо защищать ресурсы от несанкционированных действий, таких как изменений ресурсов (нелегальный перевод картинок и звуков), вывод ресурсов из состава игры.
Приведенные выше рекомендации были общими, без привязки к конкретной реализации защиты. Напомню, что мы выбираем из двух защит, принципиально отличающихся по цене и типу привязки. Это Star-force (привязка к компакт диску и характеристикам компьютера, отсутствие сетевых лицензий) и "Аладдин" (привязка к электронным ключам, наличие сетевых лицензий). Рекомендации также учитывали такой немаловажный критерий как традиционность защиты для данного сегмента рынка. Данный критерий, даже, некоторым образом отодвинул на второй план такой главенствующий фактор, как эффективность защиты. Также во внимание принимался такой фактор, как планируемый тираж программного продукта и его ориентация (не только по шкале корпоративный-частный, но и по шкале отечественный-зарубежный).
Давайте, посмотрим на таблицу Таблица 5.
Таблица 5. Рекомендации по выбору защиты
| Программа для ЭВМ | Объект защиты | Рекомендуемая защита | Причины |
| LSHead | EXE, DLL plug-in к 3D-MAX и Maya | "Аладдин" | Традиционный выбор для данного сектора рынка; Стоимость продукта значительно превышает стоимость электронного ключа нового поколения - HASP4; Наличие сетевых лицензий; |
| LSHead Pro | EXE, DLL plug-in к 3D-MAX и Maya | "Аладдин" | Традиционный выбор для данного сектора рынка; Стоимость продукта значительно превышает стоимость электронного ключа нового поколения - HASP4; Наличие сетевых лицензий; |
| LSHead SDK | LIB | Star-Force | Абсолютно эффективная защита; Защита с привязкой к диску традиционно применяется в игровом секторе; Эффективно действует в том случае, если производитель игры также пользуется данной защитой. В противном случае необходимо пользоваться HASP |
| LSHead WWW | ActiveX | N\A | На данный момент нет эффективной реализации защиты для данного сегмента. |
| PsyTest | EXE | Star-Force | Направленность данного продукта на российский рынок корпоративных и частных пользователей обуславливает выбор эффективной защиты; Имеется опыт применения подобной защиты в неигровых программах (Большая Советская Энциклопедия). |
| Game | EXE | Star-Force | Самый эффективный и не дорогой способ защиты игровых программ (можно, конечно, воспользоваться и HASP, но, думаю, что игроманы этого не поймут). |
Подведем некоторый итог для каждой компании, так как явного победителя нам выбрать не удалось. Каждая из защит эффективна только для своего сегмента рынка.
Star-Force это:
Надежная защита;
Защита не только кода, но и данных;
Привязка к компакт-диску и характеристикам компьютера;
Не слишком большое удорожание стоимости продукта;
Недорогая защита мелких партий (на cd-r\rw);
Эффективное SDK.
"Аладдин" - это:
Сетевые лицензии;
Надежные электронные ключи;
Быстрое в изучении SDK;
Защита не только кода но и данных;
Возможности реализации различных маркетинговых схем.
Эмулирование CD
Данный подход заключается в формировании виртуальных драйверов устройств и имитации обращения к диску. Это уже чистой воды взлом, поскольку для нормальной работы вскрытого приложения в систему инсталлируется специальный драйвер, который имитирует обращение к нестабильной метке на диске и возвращает вскрытой программе именно те данные, которые она ожидает "увидеть". Подобный способ довольно часто применяется на первых порах, когда хакеру известен способ получения метки на диске, но ему не очень хочется разбираться с программой методом дизассемблирования.
Противодействием может служить работа с устройствами чтения/записи на низком уровне, когда невозможно перехватить вызовы к оборудованию. Здесь нужно еще внести одно пояснение: для того, чтобы защищенному приложению обратиться к CD, и проверить его на наличие специальной метки, необходимо воспользоваться одной из функций чтения/записи, которые предоставляет Windows. Хакерами уже наработан ряд механизмов, позволяющих перехватывать стандартные обращения к функциям Windows, а раз можно перехватить обращение, значит можно имитировать чтение, целиком заменяя стандартные вызовы на собственные. Как говорилось выше, противодействием данному способу взлома может быть только обращение к накопителю не через стандартные вызовы.
Эмулирование электронных ключей (HASP)
Эмулирование устройств данного типа осуществляется так же, как и для CD, однако основную сложность представляет собой эмулирование обмена ключ - драйвер - ключ. Одна из основных возможностей электронных ключей защиты заключается в кодировании с помощью ключа данных, используемых защищенным приложением.
Противодействием эмуляции является частое использование функций кодирования данных, применение декодированных данных непосредственно в работе защищенного приложения (без предварительного сравнения).
В случае аппаратной реализации алгоритмов кодирования полная эмуляция ключей защиты становится практически невозможна, злоумышленники стараются снять защиту путем взлома программного модуля.
Эмулирование данного типа устройств осуществляется так же, как и для CD, если не проще. Вызовы к электронному ключу проще (относительно) перехватить и построить эмулятор.
Противодействием является программирование доступа к ключу на низком уровне, без использования стандартных механизмов, но и тут необходимо быть осторожными.
Коммерческий аспект
Давайте ответим на простой вопрос: а зачем нужна защита для создаваемого ПО, если она в итоге ломается?
Ответ очень прост. При выпуске программного продукта (игрового или корпоративного) может случиться так, что кряк ил сломанная версия появятся на рынке даже раньше полноценного релиза (что зачастую и происходит). Эта судьба касается практически всех программных продуктов, независимо от того защищены они специальным образом или нет.
Что же получается? Компания производитель лишается своей прибыли. Если говорить о западных компаниях, то они все равно получают свою прибыль от легального сектора экономики, и пиратство для них, конечно же ощутимо, но не смертельно. Если мы возьмем нашу компанию, то получим полное банкротство, так как никто не будет покупать легальное ПО, когда рядом лежит тоже самое по цене несоизмеримо меньше.
Что же позволит сделать эффективная защита для выпускаемого ПО?
Во-первых, устойчивая к взлому защита позволит существенно снизить цены на собственную продукцию со стороны производителей ПО, то есть сделать так, чтобы было бы не выгодно вкладывать деньги во взлом ПО со стороны пиратов. А для пользователей не имело бы смысла искать сломанную копию программного обеспечения.
Во-вторых, устойчивая защита позволяет производителю программного обеспечения гарантировать возврат инвестиций. Говоря простым языком, если защита вскрывается за 4-5 месяцев, то компания-производитель может продать достаточное количество копий своего продукта, чтобы покрыть все расходы на разработку и производство и получить прибыль. А если новая версия продукта выходит через 7-8 месяцев, то коммерческий успех можно повторять до бесконечности.
Иными словами недорогая и эффективная защита поможет компаниям-разработчикам в возврате вложенных средств. Также интересен такой аспект как управление продажами, при котором возможен индивидуальный подход к каждому клиенту.
LaserLock
| Тип защиты: | Физическое нанесение метки на носитель |
| Способ преодоления защиты: | Копирование (BlindRead), "кряк", эмуляция (D-Tools) |
| Аппаратная совместимость (cd/dvd-приводы разных производителей): | Низкая |
| Наличие особой аппаратуры для защиты серии: | ДА, требуется |
| Предоставление SDK для производителей: | ДА |
| Защита мелких партий (CD/R/RW): | НЕТ |
| Фирма - производитель: | MLS LaserLock International () |
| Коммерческие продукты, использующие данный вид защиты: | |
| Asghard, Fallout 2, Icewind Dale, Jagged Alliance 2, Messiah, Metro Police, Outcast, Shogo, SpecOps | |
| Особенности защиты: | |
| Использует уникальную маркировку. Каждое приложение на CD имеет уникальную блокировку параметра, который отвечает конечную защиту от копирования. Много слов, а мало дела. Продукт уже вскрыт всеми возможными методами. Разработчики системы явно не успевают вносить изменения в код защиты для противодействия уловкам пиратов. |
Лицензирование
Суть любой из систем лицензирования заключается в том, что после установки программного обеспечения на локальный компьютер пользователю необходимо получить от производителя ключ, который был бы тем или иным образом привязан к компьютеру (в основном), хотя это может быть и банальный пароль, и вовсе необязательно этот ключ привязан к компьютеру. Системы лицензирования бывают как "одна лицензия - один компьютер" так и "одна лицензия - один пользователь". Как правило, для этих целей используют механизм заполнения анкеты на сайте производителя (для идентификации пользователей) + пересылку (на тот же сайт) специального идентификатора компьютера, на основе которого и выполняется генерация ключа. Как правило, в ключе, в зашифрованном виде, содержится информация о пользователе, продукте, числе лицензий и другой информации.
Ярким представителем системы лицензирования является Globertrotter FlexLM. Система лицензирования, которую используют многие компании, работающие на корпоративном рынке. Данной системой пользуются такие крупные компании как Rational, AliasWavefront и многие другие.
FlexLM (и ряд других компаний) предлагает два типа лицензий: Floating и NodeLocked.
Floating - плавающий тип лицензий. Данный вид лицензий устанавливается на сервер и оговаривает число одновременно работающих машин в сети. То есть, имея 10 лицензий, с продуктом могут только 10 машин одновременно, но продукт можно инсталлировать на сколь угодно рабочих мест. Данный тип защиты позволяет продукту распространяться, но запускать его одновременно можно только на ограниченном числе машин. Защита наиболее эффективна на корпоративном рынке, где работает много специалистов. Налицо экономическая выгода, основывающаяся на том, что не все пользователи одновременно работают с одними и теми же программами. В случае корпоративного применения возможна экономия от 80% до 50% от общего числа необходимых лицензий.
NodeLocked - фиксированный тип лицензий. Данный способ защиты позволяет работать только на одной машине.
Способ хорошо подходит для индивидуальных пользователей, которым необходимо работать только с одной рабочей машины. Как правило, стоимость Floating лицензии выше, чем NodeLocked в силу вышеуказанных причин. Также лицензии делятся на две категории: постоянные и временные.
Временные - не привязываются к рабочей машине, не ограничивают в функциональности, но ограничивают срок пробной эксплуатации.
Постоянные - снимают все ограничения по срокам, но привязываются к конкретной машине.
Модули лицензирования типа FlexLM являются встроенными системами, то есть они встраиваются в программный продукт уже после его окончательной разработки. Лицензия FlexLM запрашивается либо в момент старта продукта, либо при выполнении определенных операций. В момент запуска проверяется валидность ключа и характеристики компьютера, если он привязан к таковым.
Для идентификации машины используется множество способов. Вот основные способы привязок:
к серийному номеру жесткого диска;
к MAC-адресу сетевой катрты;
к контрольной сумме BIOS;
к различным характеристикам системы.
LSHead и LSHead Pro
Поскольку ноу-хау заказчика составляет оригинальность модуля расчета мимики персонажа в реальном времени, то защитить сразу весь продукт невозможно. Здесь основную роль играет фактор времени… Любая эффективная защита вынуждена определенным образом шифровать области исполняемого модуля, а это дополнительные издержки в производительности. Соответственно, защитив продукт "в лоб" теряется скорость работы. И здесь на помощь приходит SDK. Разработчики заказчика должны сами определить модули, которые необходимо защитить.
LSHead SDK
Самый сложный, с точки зрения защиты программный продукт, так как представляет собой не отдельный исполняемый модуль, а отдельную библиотеку. Защитить полностью без потерь в производительности не представляется возможным. Если заказчик будет поставлять SDK в открытом, виде, то защитить его невозможно совсем. В этом случае можно эффективно организовать защиту рекомендуя компании-производителю программы (использующей данный SDK) пользоваться максимально эффективным способом защиты от взлома и копирования.
LSHead WWW
На данный момент не представляется возможным защитить существующими продуктами.
Метод авторизации через Интернет
В силу того, что ИТ отрасль переходит от платных к продуктов к продуктам Shareware, интересным представляется метод получения ключей через Интернет.
Многие компании - как средние, так и крупные - позволяют пользователям работать со своими продуктами некоторое время бесплатно. Это обоснованное решение, поскольку стоимость лицензий может быть достаточно высокой, а пользователь, зачастую не знает, нужен ему продукт или нет.
FlexLM имеет в своем арсенале временные ключи, не ограничивающие функциональные возможности продукта, но имеющие существенный недостаток. FlexLM рассчитан на сверхчестных пользователей, которые не подкручивают системное время назад, с целью продления срока эксплуатация. Соответственно, в чистом виде подобная защита не подходит большинству компаний-разработчиков ПО.
В отличие от классического временного ключа, активация имеет ряд неоспоримых преимуществ. Схема работы продукта выглядит следующим образом:
При первоначальном запуске, пользователя просят зарегистрироваться, заполнив анкету. После заполнения через Интернет происходит активация продукта для данной машины. Далее сервер начинает отслеживать либо число запусков продукта, либо ведет обратный отсчет времени эксплуатации. Учитывается, что при каждом запуске пользовательский компьютер автоматически через Интернет посылает запрос на сервер регистрации о возможности запуска. Если ключи еще валидны, сервер дает "добро" на запуск приложения.
Данный способ позволяет получить список пользователей, работающих с временными версиями, ограничить сроки эксплуатации и подвинуть людей к официальному приобретению продукта.
К техническим достоинствам можно отнести то, что ни переустановка продукта, ни чистка реестра не позволяют повторно использовать пробный период для одной и той же машины. К недостаткам защиты можно отнести требование выхода в Интернет на момент запуска защищенного продукта. В случае отсутствия соединения продукт не запускается.
Об эффективности защиты
Оба варианта защит предусматривают два способа внедрения в тело программного обеспечения:
Вариант использования готовой защиты;
Использование SDK.
Использование готовой защиты позволит наиболее быстро установить (внедрить) защиту в свой программных продукт, но здесь есть одно "но". Встроенная защита, обычно, очень легко ломается. К сожалению, многие компании идут как раз по пути наименьшего сопротивления, то есть по пути стандартной защиты, получая, в итоге, сломанный пиратами свой программный продукт. Причем, сломанный в кратчайшие сроки. В итоге ломается не только продукт, но и дискредитируется компания, которая производит данную защиту. Хотя компания ни в чем и не виновата.
Использование SDK позволит встроить защиту в разрабатываемое ПО наиболее эффективным образом (так называемый способ размазанной защиты). Этот способ требует некоторых дополнительных издержек на обучение специалистов и написание дополнительного кода в тело имеющегося ПО. Но игра стоит свеч.
Обзор современных средств защиты
В этом разделе приводятся сравнительные характеристики основных игроков на рынке защит. Большинство из них работают в сфере защиты компакт-дисков, однако есть и "защитники" shareware программ (защита от взлома в чистом виде), и компании, организующие аппаратную защиту.
Вы сами можете сравнить различные продукты, пользуясь сведениями, приведёнными ниже, или раскопав больше информации на сайтах производителей или на .
Забегая вперёд, подведу итог исследованиям: на сегодняшний день лидерами в области защиты от копирования являются Star Force и Aladdin. Однако их рынки едва ли пересекаются. Star Force больше рассчитан на защиту мелких и средних продуктов, таких как игры, shareware-программы, и т.п., к тому же эта защита стоит относительно дешево. Защита Aladdin обходится дороже и рассчитана на рынок серьёзных и дорогих систем.
Могу вам только пожелать успешно защищать свою продукцию и сполна получать добываемую суровым программерским трудом прибыль. Удачи!
Отладка
Отладчиков существует великое множество: от отладчиков, являющихся частью среды разработки, до сторонних эмулирующих отладчиков, которые полностью "погружают" отлаживаемое приложение в аналитическую среду, давая разработчику (или хакеру) полную статистику о том, что и как делает приложение. С другой же стороны, подобный отладчик настолько четко имитирует среду, что приложение, исполняясь под ним, считает, что работает с системой напрямую (типичный пример подобного отладчика - NuMega SoftIce).
Способов противодействия отладке существует не меньше чем отладчиков. Это именно способы противодействия, поскольку основная их задача сделать работу отладчика либо совсем невозможной, либо максимально трудоемкой. Опишем основные способы противодействия:
Замусоривание кода программы. Способ, при котором в программу вносятся специальные функции и вызовы, которые выполняют сложные действия, обращаются к накопителям, но по факту ничего не делают. Типичный способ обмана. Хакера нужно отвлечь, создав ответвление, которое и будет привлекать внимание сложными вызовами, и содержать в себе сложные и большие вычисления. Хакер рано или поздно поймет, что его обманывают, но время будет потеряно.
Использование многопоточности. Тоже эффективный способ защиты, использующий возможности Windows по параллельному исполнению функций. Любое приложение может идти как линейно, то есть инструкция за инструкцией, и легко читаться отладчиком, а может разбиваться на несколько потоков, исполняемых одновременно, естественно, в этом случае, нет никакого разговора о линейности кода, а раз нет линейности, то анализ здесь трудноосуществим. Как правило, создание 5-6 и более потоков существенно усложняет жизнь хакеру. А если потоки еще и шифруются, то хакер надолго завязнет, пытаясь вскрыть приложение.
Подавление изменения операционной среды. Программа сама несколько раз перенастраивает среду окружения, либо вообще отказывается работать в измененной среде. Не все отладчики способны на 100% имитировать среду системы, и если "подопытное" приложение будет менять настройки среды, то рано или поздно "неправильный" отладчик может дать сбой. Противодействие постановке контрольных точек. Специальный механизм, поддерживаемы микропроцессором, при помощи которого можно исследовать не всю программу сначала, а, например, только начиная с середины. Для этого в середине программы ставят специальный вызов (контрольную точку - Breakpoint), который передает управление отладчику. Недостаток способа кроется в том, что для осуществления прерывания в код исследуемого приложения надо внести изменение. А если приложение время от времени проверяет себя на наличие контрольных точек, то сделать подобное будет весьма и весьма непросто.
Изменение определенных регистров процессора, на которые отладчики неадекватно реагируют. Также как и со средой. Отладчик тоже программа и тоже пользуется и операционной системой и процессором, который один на всех. Так, если менять определенные регистры микропроцессора, которые отладчик не может эмулировать, то можно существенно "подорвать" его здоровье.
Побитовое копирование CD
Данный способ даже вряд ли можно назвать взломом. Пользователь (не всегда злоумышленник) пытается скопировать имеющийся у него носитель (компакт-диск) с целью создания копии для личного использования или для тиража.
Для осуществления этого могут использоваться различные программы, зачастую входящие в поставку устройств CD-R/RW. Это и официальные Easy CD Creator и Nero, и полуофициальные (полухакерские) CloneCD и BlindRead.
Защита должна уметь противодействовать данному способу, так как с него обычно и начинается взлом, поскольку программ-копировщиков, способных скопировать диски с примитивной защитой, великое множество.
Существуют два способа противодействия копированию. Первый заключается в том, что на диск записывается определенная метка, которая не копируется обычными средствами (например, создается нестабильный сегмент, который не читается носителем, а раз не читается, то и скопированным быть также не может). К сожалению, данный способ не всегда надёжен, поскольку уже существуют программы "продвинутого" копирования (те же CloneCD и BlindRead), которые способны пропускать подобные места (замещать нестабильные области произвольными данными) и проводить копирование до конца.
Второй способ основывается на том, что ничего никуда записывать не надо, а надо лишь определенным образом запоминать физические характеристики диска, которые просто невозможно воспроизвести любым копированием, точнее диск сам по себе копируется, но уже с другой физической структурой. Соответственно, пользователь может спокойно клонировать диски, но ключевым будет тот, который был официально куплен. То есть, в данном случае, диск будет использоваться как ключ доступа к информации. Для примера реализации данного метода можно упомянуть продукт "Большая Советская Энциклопедия", состоящий из 3 дисков, информация с которых свободно копируется, но работа с энциклопедией возможна только при наличии первого диска.
Послесловие
В завершении статьи хотелось бы поблагодарить всех, кто помогал в работе над статьей. Хотелось бы отдельно поблагодарить компанию Lifemi (), для которой, собственно, и проводилась исследовательская работа по выпору защиты для коммерческих продуктов, что и явилось поводом для написания данной статьи. Хочется надеяться, что материал, приведенный в данной статье поможет и другим компаниям-разработчикам сделать правильный выбор.
Предоставление SDK со стороны разработчиков защиты
SDK (Software Developer Kit, комплект разработчика ПО) позволяет детально ознакомиться с продуктом. Для этого в состав SDK включены полная техническая документация, описание утилит и средств разработки.
В комплект разработчика входит все необходимое для начала использования представляемой технологии в собственных программных продуктах - детальные примеры, фрагменты кода, поддержка различных ОС, средств разработки.
Также SDK включает в себя оборудование (hardware) для построения тестовых проектов (например, SDK HASP, который содержит демонстрационные ключи HASP).
Достаточно часто встречающееся приложение к системам защиты. SDK позволит на самых ранних этапах разработки приложения внедрить защиту в приложение. Как известно, защита, которая встраивается в приложение на последнем этапе, достаточно легко нейтрализуется. Нейтрализовать же защиту, встроенную в само приложение достаточно трудно. Примером подобной защиты может служить IBM Rational ClearCase, защита которого настолько "размазана" по продукту, что пирату просто не реально за сколько-нибудь приемлемый промежуток времени провести его анализ и нейтрализовать саму защиту.
Что же происходит при использовании SDK? Как правило, SDK определяет защищенность отдельных областей кода или данных приложения, а также места проверки легальности запуска (например, обращение к ключу/диску). Ниже рассказывается про атаку методом дампинга, противодействовать которому можно только когда приложение НИКОГДА не остается в памяти компьютера в полностью развернутом виде.
SDK позволит разработчикам программного продукта определить какие части приложения будут видны всегда (например, участки кода, направленные на максимальную производительность), а какие необходимо прятать. Тем не менее, SDK тоже бывают разные. Следует оценивать стоимость комплекта, наличие поддержки, и, самое главное, - простоту изучения. Последний критерий достаточно спорный, так как эффективность SDK может быть напрямую связана со сложностью изучения.
Программные и аппаратные методы защиты
Методы защиты можно разделить на программные и аппаратные. К программным относятся методы, реализуемые чисто софтверным путём, в них не затрагиваются физические характеристики носителей информации, специальное оборудование и т.п. К аппаратным относятся методы, использующие специальное оборудование (например, электронные ключи, подключаемые к портам компьютера) или физические особенности носителей информации (компакт-дисков, дискет), чтобы идентифицировать оригинальную версию программы и защитить продукт от нелегального использования.
Рассмотрим различные подходы к защите и характеристики, которые используются в современных продуктах.
PsyTest
Рекомендации, такие же, как и выше. Необходимо использовать SDK защиты. Здесь еще нужно учитывать также не только защиту кода от взлома, но и защиту данных от нелегальных "дополнений" и изменений.
Рекомендации по выбору защиты
Определившись с финалистами, давайте вспомним, что же нам необходимо защищать и подберем защиту для конкретного продукта, имеющегося у Заказчика (Таблица 4).
Таблица 4 - Объект защиты и тип лицензии защищаемого продукта
| Программа для ЭВМ | Тип лицензии | Объект защиты |
| LSHead | Рабочее место | EXE, DLL plug-in к 3D-MAX и Maya |
| LSHead Pro | Рабочее место. Критично по времени исполнения | EXE, DLL plug-in к 3D-MAX и Maya |
| LSHead SDK | % с тиража, время | LIB |
| LSHead WWW | Сайт, время | ActiveX |
| PsyTest | Индивидуальное использование | EXE |
| Game | Индивидуальное использование | EXE |
Учитывая специфику каждого программного продукта, попробуем дать общие рекомендации для организации эффективной защиты без привязки к конкретному производителю.
SafeDisk
| Тип защиты: | Физическое нанесение метки на носитель |
| Способ преодоления защиты: | Копирование (CloneCD), "кряк", эмуляция (D-Tools) |
| Аппаратная совместимость (cd/dvd-приводы разных производителей): | Хорошая |
| Наличие особой аппаратуры для защиты серии: | ДА, требуется |
| Предоставление SDK для производителей: | ДА |
| Защита мелких партий (CD/R/RW): | НЕТ |
| Фирма - производитель: | Macrovision Corporation () |
| Коммерческие продукты, использующие данный вид защиты: | |
| Практически все игры после 01-01-2001 | |
| Особенности защиты: | |
| Здесь также применяется метод нанесения физических меток, для чего требуется дополнительное оборудование. Производитель утверждает о большой эффективности системы, не раскрывая методов, которые применяются в защите. Только пиравтов это не остановило. Все программы, защищенные данной системой уже вскрыты. Способов противодействия защите также найдено несколько. Невзирая на предоставление SDK компаниям-производителям игр не удалось обеспечить надежного противодействия |
SecuRom
| Тип защиты: | Физическое нанесение метки на носитель |
| Способ преодоления защиты: | "Кряк", эмуляция (D-Tools) |
| Аппаратная совместимость (cd/dvd-приводы разных производителей): | Низкая |
| Наличие особой аппаратуры для защиты серии: | ДА, требуется |
| Предоставление SDK для производителей: | НЕТ |
| Защита мелких партий (CD/R/RW): | НЕТ |
| Фирма - производитель: | Sony () |
| Коммерческие продукты, использующие данный вид защиты: | |
| Diablo 2, SimCity 3000, Decent FreeSpace, FIFA 99, Panzer Commander, S.A.G.A: Rage of the Vikings | |
| Особенности защиты: | |
| Используются все те же метки. Достаточно интересным отличием данной защиты является то, что они действительно некопируемые. По крайней мере до сих пор не найдено программ, способных побитово копировать защищенные диски. В остальном же так же как и со многими системами - есть методы обхода защиты, и это невзирая на громкое имя корпорации, производящей защиту. Справедливости ради стоит отметить, что над совершенствованием защиты ведутся постоянные работы. Кто знает, может им и удастся стать абсолютно непроницаемыми. Некопируемая метка уже есть. |
Схема внедрения защиты
Внедрение любой стороннего инструментария, в том числе и защиты, сопровождается сложностями. Сложности внедрения защиты связано с тем, что помимо изучения вопроса безопасности необходимо расширить круг обязанностей разработчиков и службы технической поддержки.
Разработчики должны изучить функции SDK, представляемого SF и Аладдин, на уровне достаточном для реализации функций и задач интеграции защиты в новой или разрабатываемое ПО.
Особенно сложности будут при реализации защиты для существующих программных продуктов, так как придется встраивать защиту в исходные тексты, что повлечет за собой затраты на дополнительное тестирование и появление новой версии продукта.
По независимой оценки, специалистов использовавших SDK от SF следует отметить, что сам SDK можно отнести к среднему уровню сложности для понимания разработчиками (к примеру, SDK Алладина на порядок проще), но она укладывается в разумные рамки по времени, необходимому на изучение (порядка 1 человек осваивает систему за 3-4 дня).
В целях удешевления общей стоимости внедрения рекомендуется провести пробное обучение специалистов Заказчика и выполнить пилотный проект, после чего принять решение о дальнейшем развитии системы защиты на базе Заказчика. Общую поэтапную схему можно увидеть на рисунке (Рисунок 1)
Дополнительно трудности возникают в осуществлении службой технической поддержки несвойственных ранее функций: Обращения пользователей по поводу неработающих CD (если защита не срабатывает на редком приводе) и отказов электронных ключей.
Расход на расширение службы технической поддержки также необходимо учитывать при оценке общей стоимости защиты.
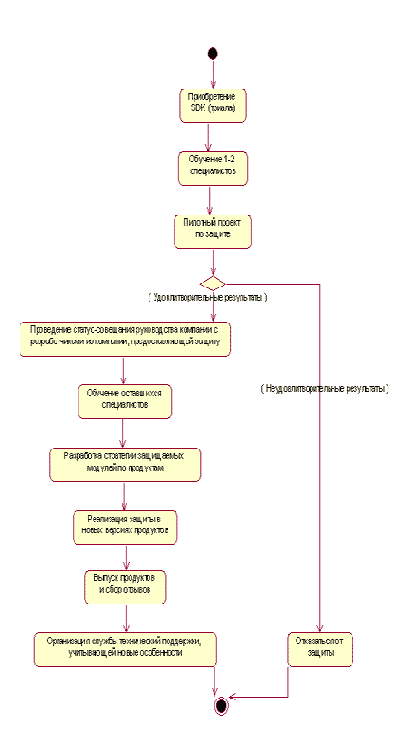
Рисунок 1. Схема внедрения защит Star-Force или "Аладдин"
Сложность тех. Поддержки защищенных продуктов
Ранее основной проблемой всех систем, включая SF, была несовместимость защиты с некоторыми видами приводов CD\DVD (продукцией No-name, и рядом устройств для ноутбуков). SF успешно решила данную проблему двумя способами. Во-первых, список совместимость с приводами постоянно растет. Во-вторых, в системе имеется возможность введения универсального кода, который позволит запустить приложение, если диск не аутентифицируется.
Последняя функция, безусловно, является дырой в защите. Но ее наличие или отсутствие определяет копания, выпускающая программное обеспечение (паблишер).
В случае использования данной функции необходимо организовать службу поддержки, регистрирующей запросы от пользователей и создающей Rescue ключи (служба получает запросы от пользователей и генерирует ключи через сервер SF). В случае выбора защиты "Алладин" технической поддержке придется отвечать на вопросы об установке драйверов и о работе с портами.
Сравнение с конкурентами
Если обратиться к ценам (зарубежных) конкурентов, то можно получить следующую картину относительно объема партии 5000 CD и с учетом того, что данными системами можно защищать только печатные диски, а не CD\r\rw:
SecuROM: криптовка $500 + плата за каждый диск (роялти) $0.13
SafeDisc: криптовка $500 + плата за каждый диск (роялти) $0.14
Получается, что использование отечественной защиты, естественно, удорожает стоимость конечного продукта, но не на много.
Считаем, что цена SF является приемлемой и даже низкой.
Цена защиты делает ее наиболее эффективной для рынка индивидуальных пользователей.
Star Force
| Тип защиты: | Измерение физических характеристик без нанесения особых меток на носитель |
| Способ преодоления защиты: | Способ не найден (теоретически взлом возможен путем пошаговой отладки нестандартным отладчиком в среде эмуляции операционной системы) |
| Аппаратная совместимость (cd/dvd-приводы разных производителей): | 100% (за счет возможности ввода специального ключа) |
| Наличие особой аппаратуры для защиты серии: | НЕ требуется |
| Предоставление SDK для производителей: | ДА |
| Защита мелких партий (CD/R/RW): | ДА |
| Фирма - производитель: | Protection Technology () |
| Коммерческие продукты, использующие данный вид защиты: | |
| 1С (игры), Нивал, Softmax Co, Q-puncture Inc, Scholastic, Hypnosys World, руссобит-м (игры) Российские клиенты компании: 1С, Диасофт, Руссобит, Лукойл, Бука, Акела |
|
| Особенности защиты: | |
| Данная программа так же, как CD-COPS и TAGES, пользуется самой эффективной системой защитой от копирования, основанной на способе измерения специфических характеристик CD\DVD-ROM. Поскольку защита не вскрыта, то не известен и способ, которым производителям удается идентифицировать различные диски. Заявленная 100% совместимость с любой аппаратурой и 100% идентификация дисков подтверждается независимыми сайтами.
Защита эффективно противодействует отладчикам и дизассемблерам. Эффективность защиты подтверждает тот факт, что за год существования не нашелся способ ее нейтрализации. Дополнительный лоск защите придает возможность защиты мелких партий дисков (CD-R\RW) и наличие SDK, при помощи которого разработчики игр могут шифровать отдельные фрагменты кода и данных. Отдельно можно воспользоваться функцией шифрования игровых данных от несанкционированного "перевода" или "адаптации". |
В таблице Таблица 3 продемонстрированы цены и объект защиты.
Таблица 3. Стоимость услуг SF
| Тираж программного продукта, компакт-дисков | Выплата с диска, USD (по накопительному принципу) | Шифрование выполняемых файлов (EXE, DLL), USD |
| До 1 000 | 0.2 | 300 |
| 1 000 … 3 000 | 0.15 | |
| 3 000 …10 000 | 0.1 | |
| Свыше 10 000 | 0.05 |
TAGES
| Тип защиты: | Измерение физических характеристик без нанесения особых меток на носитель |
| Способ преодоления защиты: | Эмуляция, "Кряк" |
| Аппаратная совместимость (cd/dvd-приводы разных производителей): | Высокая |
| Наличие особой аппаратуры для защиты серии: | НЕ требуется |
| Предоставление SDK для производителей: | НЕТ |
| Защита мелких партий (CD/R/RW): | НЕТ |
| Фирма - производитель: | Thomson & MPO () |
| Коммерческие продукты, использующие данный вид защиты: | |
| Moto Racer 3 | |
| Особенности защиты: | |
| Защита основана на достаточно оригинальном методе многократного чтения одного и того же сектора с последующим сравнением результатов. Вполне возможно, что здесь происходит анализ физических характеристик носителя. Слабое место защиты ее программный модуль, который уже вскрыт |
Устойчивость к прямому копированию
Основой любой защиты можно считать ее способность к идентификации носителя, с которым она попала к пользователю. И не просто к идентификации, а к способности отличить данный носитель от нелегальной копии. Причем, уровень защиты на данном этапе должен быть такими, чтобы та условная метка или характеристика, которая была присуща данному носителю, не воспроизводилась любыми средствами битового копирования. Эффективность данного этапа определяет стойкость защиты к элементарному копированию, когда пользователю достаточно запустить CloneCD, и не о чем больше не думать.
Следует отметить, что многие системы защиты используют различные физические метки, по которым программа сможет идентифицировать валидность носителя. Как правило, физически установленные метки плохо копируются, но неплохо эмулируются специальными драйверами, что делает защиту, основанную только на физических метках, очень уязвимой. Еще, как правило, все системы защиты представляют собой "вставную челюсть". То есть модуль, который отвечает за идентификацию диска, в большинстве случаев не может противостоять хакерской атаке, в то время как менее важные участки кода оказываются хорошо защищенными.
Наиболее эффективным можно считать способ, при котором на диск не наносятся специальные метки, то есть, когда диск спокойно можно копировать, и распространять его содержимое, но старт будет производиться только при наличии оригинального диска.
Подобные защиты основываются на том факте, что любой диск (СD/DVD/R/RW) имеет ряд уникальных характеристик, присущих только одному диску, и эти характеристики теряются при копировании на другой диск. Их реализация в конкретных системах (Star-Force, Tages) остается тайной за семью печатями.
Устойчивость к взлому
Второй по счету, но не по важности компонент защиты - это устойчивость к взлому. Если защиту не удается обойти копированием и эмулированием, хакеру необходимо при помощи механизмов дизассемблирования и пошаговой отладки просканировать приложение, выделить логику защиты и нейтрализовать ее. Соответственно, если у защиты имеется надежный способ работы с метками (или с характеристиками носителя), то есть когда есть возможность однозначно идентифицировать валидность представленного носителя, но модуль идентификации не защищен должным образом, то подобную систему нет смысла использовать, так как она не выдержит даже минимальной хакерской атаки (любительской атаки, которая проводится из интереса). Про специально направленную на взлом данного приложения атаку и говорить не приходится.
В следующем разделе описаны основные методы взлома и противодействия, а пока рассмотрим ещё несколько аспектов, относящихся к средствам защиты.
Виды и характеристики современных средств защиты
Достаточно трудно дать точную характеристику понятию "защита", поскольку оно слишком широко трактуется, и подразумевает практически все аспекты информационной безопасности.
Защита - совокупность действий, направленных на противодействие взлому, нелегальному копированию и несанкционированному доступу.
Спектр данной статьи несколько более узок, но это не слишком сужает спектр мер. Для того, чтобы в последних строках дать совет по выбору наиболее эффективной схемы защиты (с соответствующей программной поддержкой) необходимо рассмотреть основные виды защит и их производителей.
Давайте немного углубимся в смысл словосочетания "защита от копирования". Целью всех современных средств защиты от копирования является ограничение использования программных продуктов. Для достижения этой цели используются самые различные методы.
Несмотря на все усилия различных
Несмотря на все усилия различных организаций во главе с BSA в последние годы продолжается рост компьютерного пиратства. В среднем доля пиратского ПО в глобальном масштабе составляет 40%, то есть каждые четыре из десяти копий программы оказываются в каком-то смысле украденными у производителя и лишают его прибыли. По расчетам BSA в 2002 году убытки софтверной отрасли от пиратства составили порядка 13 миллиардов долларов .
Россия находится на пятом месте в списке стран с наивысшими показателями пиратства, и доля пиратского ПО в нашей стране составляет 89% (!) . Для западных компаний это хоть и приносит ощутимые убытки, но не является критичным для их бизнеса. Для российских же компаний такая распространённость пиратства может оказаться подводной скалой, о которую разобьются все инвестиционные планы.
С пиратством можно бороться различными способами. Основным, наверное, всё же должен быть легитимный. То есть взлом и незаконное распространение программного обеспечения должны быть правильно описаны в соответствующих законах, и государство должно осуществлять преследование пиратов и привлекать их к ответственности. Но наше государство пока еле справляется с исполнением своих обязанностей в других областях.
Ещё одним эффективным методом борьбы с пиратством является экономический. Это когда цена продукта настолько низкая, что может сравниться с ценой взломанного продукта, продаваемого пиратами. В большинстве случаев, если цена будет приблизительно одинаковой, покупатель предпочтёт лицензионный продукт пиратскому. Тем не менее, экономическая конкуренция с пиратством дело очень тяжелое и подходит далеко не всем производителям программного обеспечения. Такие производители (а их большинство) обращаются к третьему методу - защите программного обеспечения от взлома и нелегального копирования. Хорошая защита доставляет больше всего хлопот пиратам и, в конечном счёте, приводит софтверные предприятия к требуемой цели (получению прибыли).
На рис. 1 показаны графики получения прибыли от продаж незащищённого и защищённого продуктов.
Как видно из графиков, если продукт плохо защищён, то его достаточно быстро "вскрывают", и на рынке появляется дешёвая пиратская версия, которая не позволяет лицензионной версии завоевать свою долю рынка, и продажи легального продукта быстро падают. Если же продукт хорошо защищён, то у пиратов уходит достаточно много времени на вскрытие защиты и продукт успевает достичь требуемого уровня продаж и достаточно долго удерживаться на рынке.
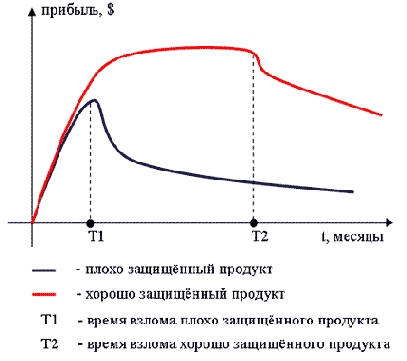
Рис. 1 - Динамическая зависимость прибыли от степени защищённости продукта
Технологии защиты постоянно эволюционируют. Как показывает практика, для взлома новой защиты требуется от нескольких дней, до нескольких месяцев. Также существуют пока не взломанные защиты, о них речь пойдёт ниже.
Целью данной статьи является ознакомление читателя с различными решениями, предлагаемыми сегодня на рынке защит. Этим я постараюсь внести свой посильный вклад в дело борьбы с компьютерным пиратством.
В начале статьи проводится обзор архитектуры и характеристик современных средств защиты. Далее рассматриваются основные способы взлома программных продуктов и методы противодействия. В завершение проводится анализ рынка защит и приводятся сравнительные характеристики основных на сегодняшний день продуктов в этой области. И самое главное, в конце статьи даются рекомендации по выбору. Причем рекомендации не абстрактные, конкретные, ведь написание данной статьи предварила Научно-исследовательская работа по подбору защиты для одной из российских компаний, которая стремительно выходит на отечественный и международный рынок высокотехнологичного ПО и очень нуждается в защите собственных инвестиций от посягательства пиратов разных мастей.
Итак, заказчик изначально имеет несколько программных продуктов, рассчитанных на разные сегменты рынка. Известно, что систем защит существует множество, и не все из них могут удовлетворять заказчика по соотношению цена\качество.
В таблице 1 приведены все исходные данные по программным продуктам.
Особое внимание хочется отметить на ценовые категории и сегмент рынка, хотя каждую позицию в таблице нужно считать ключевой.
Таблица 1. Характеристика программ для ЭВМ.
| Программа для ЭВМ | Ценовая категория ($, тыс.) | Объем продаж | Тип лицензии | Сегмент рынка | Объект защиты |
| LSHead | 0.5-2 | 100-1000 | Раб. место | USA, Индивидуальный | EXE, DLL plug-in к 3D-MAX, Maya |
| LSHead Pro | 10-30 | 10-100 | Раб.место, время | USA, Корпоративный | EXE, DLL plug-in к 3D-MAX, Maya |
| LSHead SDK | 10-30 | 10-20 | % с тиража, время | USA, Корпоративный | LIB |
| LSHead WWW | 3-10 | 10-100 | Сайт, время | USA, Корпоративный | ActiveX |
| PsyTest | 0.4-2 | 100-1000 | Раб.место | РФ, Корпоративный | EXE |
| Game | 1-20 | 100-1000 | Раб.место | РФ, частный сектор | EXE |
Итак, мы имеем 6 программных продуктов, для которых необходимо подобрать защиту.
Кратко опишем каждый из продуктов
Таблица 2. Описание программных продуктов Заказчика
| Продукт | Краткое описание |
| LSHead | Дополнительный модуль расширения к трехмерным программам, предназначенный для отображения мимики лица персонажей в реальном масштабе времени |
| LSHead Pro | Дополнительный модуль расширения к трехмерным программам, предназначенный для отображения мимики лица персонажей в реальном масштабе времени. Профессиональный вариант. |
| LSHead SDK | Набор библиотек и документов для компаний-разработчиков игрового ПО, которые хотят использовать технологию мимики персонажей в своих играх |
| LSHead WWW | |
| PsyTest | Программа психологического тестирования |
| Game | Условно-игровая программа с элементами квеста и аркады |
Прошу обратить особое внимание читателей на стоимость каждого программного продукта. Так как любая система защиты удорожает исходный продукт, то нужно выбрать именно ту защиту, которая не одинаково удорожает стоимость продукта для каждой отдельной категории.
Рассмотрим основные требования, которые можно предъявить к современной системе защиты:
Защита должна быть с большим запасом прочности. Учитывать высокий уровень пиратов вообще, и Российских в частности, способная противостоять их натиску долгое время;
Известно, что абсолютно надежной защиты не бывает, но выбранная система должна обеспечить компании-разработчику достаточную фору во времени, пока пираты не научатся вскрывать данный продукт.
По возможности не привязываться к аппаратной конфигурации компьютера, поскольку персональный компьютер не есть вещь в себе, и его отдельные компоненты могут и должны быть заменяемыми по мере старения;
Данный критерий в процессе работы над отчетом менялся довольно часто, поскольку компании-разработчики защиты смогли сделать так, что привязка к оборудованию не вызывает особых проблем при работе. не следует привязываться к аппаратной конфигурации компьютера (правильно - логичнее привязывать защиту к ключу или компакт-диску). Ключи - вещь хорошая, с их помощью можно реализовывать различные схемы продаж. Но, самое главное,- ключами осмысленно защищать достаточно дорогой софт. И совсем противоположная ситуация с дисками - для них подходят и недорогие программные продукты
По возможности не использовать для защиты дорогие дополнительные аппаратные приспособления, которые только повышают стоимость защиты, а стало быть, и конечного продукта;
Защиту от проникновения и копирования можно организовать разными способами. При этом учитывается, что для недорогой программы нельзя использовать дорогую защиту. Во-вторых, при расчете стоимости защиты учитываем стоимость защищаемого программного продукта
Должна быть основана на оригинальных принципах защиты от взлома. Показателем критерия может служить тот факт, что защита еще не взломана, либо взломана, но всеми возможными способами;
Это критерий прогрессирования. Защита может быть эффективной, если она находится в состоянии постоянного развития. Если разработчики защиты отслеживают хакерские форумы и делают выводы о дырах собственных систем.
Не препятствует свободному копированию защищенных данных (должна запрещать только несанкционированный запуск, то есть копируется копировщиком, но не исполняется);
В принципе можно рассматривать отдельно защиту от копирования и от распространения (или нераспространения). Данный критерий предполагает свободное копирование, но авторизованный запуск.
Защита должна быть подобрана с учетом традиций данного сегмента рынка ПО.
Самый интересный критерий, изменивший начальный расклад советов по выбору. Поскольку заказчик хочет выйти на мировой рынок, то используемая защита, должна быть типичной для того сегмента, на который направлена программа. Так, например, мало кто решится ставить защиту, основанную на электронных ключах на игровую программу, поскольку НИКТО из производителей в данном сегменте не пользуется такой защитой.
Соответственно, защита НЕ ДОЛЖНА вызывать отторжения у конечного пользователя своей экстравагантностью.
Стоимость защиты для разработчика и покупателя должна соотноситься со стоимостью программы.
Выбор защиты
В приложении 2 приведены характеристики защит. Здесь нет необходимости описывать какая защита лучше, а какая хуже. Из сравнительной таблицы и так видно кто есть кто.
Из имеющихся на данное время систем защит мы имеем две системы:
Защиту от копирования и взлома - StarForce;
Защиту от копирования и взлома - "Аладдин".
Обе системы предлагают защиту, но она (защита) основана на разных принципах: в случае StarForce предполагается использовать привязки защищаемой программы к компакт-диску, в случае компании "Аладдин", предполагается использовать электронный ключ, подключаемый к порту компьютера. Писать какой способ лучше, а какой хуже, наверное, можно, но полемика здесь сравнима с полемикой, о том, какой язык программирования луче - и в чистом виде ни к чему не ведет. Отмечу, что у каждой системы свои достоинства и недостатки (о которых будет рассказано ниже), но главное в том, что каждая из систем направлена строго на определенный сегмент рынка: StarForce ориентирован, в первую очередь, на рынок игровых программ, или, иными словами, на рынок индивидуальных пользователей, в то время как HASP больше направлен на рынок корпоративных пользователей.
Взлом программного модуля
Это следующий уровень взлома. В том случае если не удалось скопировать приложение (также не удалось пропустить диск/HASP через эмулятор), а способ его защиты также неизвестен, то хакер переходит на следующий уровень взлома - на исследование логики самой программы, с той целью, чтобы, проанализировав весь код приложения, выделить блок защиты и деактивировать его.
Взлом программ осуществляется двумя основными способами. Это отладка (или пошаговое исполнение) и дизассемблирование.
Отладка - это специальный режим, создаваемый специальным ПО - отладчиком, который позволяет по шагам исполнять любое приложение, передавая ему всю среду и делая все так, как будто приложение работает только с системой, а сам отладчик невидим. Механизмами отладки пользуются все, а не только хакеры, поскольку это единственный способ для разработчика узнать, почему его детище работает неправильно. Естественно, что любую благую идею можно использовать и во зло. Чем и пользуются хакеры, анализируя код приложения в поиске модуля защиты.
Это так называемый, пошаговый режим исполнения, или, иными словами интерактивный. А есть еще и второй - дизассемблирование - это способ преобразования исполняемых модулей в язык программирования, понятный человеку - Ассемблер. В этом случае хакер получает распечатку того, что делает приложение. Правда распечатка может быть очень и очень длинной, но никто и не говорил, что защиты снимать легко.
Хакеры активно пользуются обоими механизмами взлома, поскольку иногда приложение проще пройти по шагам, а иногда проще получить листинг и проанализировать его.
Теперь рассмотрим основные методы взлома и противодействия ему.
Анализ специфических языковых конструкций и алгебраические преобразования
В качестве второго примера мы выбрали запутанную программу, которая существенно использует специфические языковые конструкции. Эта программа - победитель 1998 года международного конкурса запутанного кода на Си [12]. В конкурсе участвуют программы на языке Си, запутанные вручную. Победители выявляются в таких номинациях, как "самый предательский код на Си", "лучшее анти-использование ANSI C".

Рис. 4. Конвертер ASCII/код Морзе (автор Frans van Dorsselaer).
Программа выполняет перекодирование символов, считываемых со стандартного потока, из кода Морзе и обратно. Она имеет запутанную структуру графа потока управления, её внутренние таблицы закодированы. Для распутывания программы были проделаны следующие шаги:
Программа была оттранслирована во внутреннее представление. Умышленно трудновоспринимаемые идентификаторы (I, l) были переименованы в более простые a, b, c и т. д. Над программой во внутреннем представлении были выполнены некоторые эквивалентные алгебраические преобразования, например (a-1)[strlen(a)] было заменено на a[strlen(a)-1]. Анализ алиасов позволил установить, что только элемент a[0] изменяется в процессе работы программы, следовательно в вызовах функций strspn, memchr вместо массива a могут использоваться строковые литералы. Анализ доменов позволил определить, что выражения, записанные в условном операторе, могут принимать всего два или три значения. Решая Диофантовы уравнения, можно значительно упростить условия. В анализируемой программе далее были проведены анализ избыточных выражений (partial redundancy elimination), анализ нулевых выражений (zero-value analysis). Все это позволило разделить один внутренний цикл на два независимых цикла.

Рис. 5. Конвертер ASCII/MORSE после преобразований.
Программа из внутреннего представления была переведена обратно в Си, при этом был проведён структурный анализ графа потока управления для выявления циклов и представления их в высокоуровневой форме.
На рис. 5 приведён текст программы после всех описанных преобразований. Несмотря на то, что он стал больше, чем текст исходной программы, его структура стала намного проще и понятнее. После этого не составляет труда установить правила перекодирования кода Морзе в код ASCII и обратно.

Рис. 6. Распутанная программа решения задачи "8 ферзей"
Анализ запутанных программ
В данном разделе мы сопоставим методы запутывания, описанные в разделе 2, и методы анализа программ, рассмотренные в разделе 3. На основании этого сопоставления вводится новая мера устойчивости запутывающих преобразований, а именно.
| Метод запутывания | Метод распутывания |
| искажение имён переменных | переименование переменных |
| использование специфических языковых конструкций | упрощение специфических языковых конструкций |
| развёртка цикла | визуализация графа потока управления функции для выделения потенциальных кандидатов на свертку в цикл; выявление индуктивной переменной, что требует (интерактивного) сравнения базовых блоков и (интерактивных) эквивалентных преобразований выражений, причём при таких преобразованиях выражение может даже (незначительно) усложняться; свёртка цикла |
| использование уникальных переменных в базовых блоках | продвижение копий (статическое и статистическое), минимизация количества используемых переменных |
| введение детерминированного диспетчера | статистическое восстановление графа потока управления |
| введение недетерминированного диспетчера | сравнение трасс, полученных на одном и том же наборе входных данных |
| переплетение кода нескольких базовых блоков в один запутанный базовый блок | статистическое устранение мёртвого кода |
| введение непрозрачных предикатов | статистический анализ покрытия для выявления потенциальных непрозрачных предикатов, поиск по образцам известных непрозрачных предикатов, алгебраическое упрощение, доказательство теорем |
| все методы | свёртка констант, продвижение констант, продвижение копий, статическое устранение мёртвого кода - могут выполняться после каждого шага распутывающих преобразований |
Таблица 1. Методы запутывания программ и методы, которые могут применятся для их анализа.
запутывающее преобразование называется устойчивым относительно некоторого класса методов анализа программ, если методы этого класса не позволяют надёжно раскрыть данное запутывающее преобразование Перечисление некоторых методов запутывания программ с точки зрения методов их возможного распутывания дано в таблице 1.
| Преобразование | Сложность распутывания (необходимый тип анализа) | Автоматизируемость (тип распутывателя) |
| Удаление комментариев | Одностороннее преобразование | hh |
| Переформатирование программы | Синтаксический | автомат. |
| Удаление отладочной информации | Одностороннее преобразование | hh |
| Изменение имён идентификаторов | Синтаксический | полуавтомат. |
| Языково-специфические преобразования | Синтаксический | автомат. |
| Открытая вставка функций | Одностороннее преобразование | поддерж. |
| Вынос группы операторов | Синтаксический | автомат. |
| Непрозрачные предикаты и выражения | Синтаксический - статистический (зависит от вида предиката) | автомат. - поддерж. |
| Внесение недостижимого кода | Зависит от стойкости непрозрачных предикатов | автомат., полуавтомат. |
| Внесение мёртвого кода | Синтаксический - статистический | автомат., полуавтомат. |
| Внесение избыточного кода | Синтаксический - статистический | автомат., поддерж. |
| Внесение несводимости в граф | Статический, но зависит от стойкости непрозрачных предикатов | автомат., полуавтомат. |
| Устранение библиотечных вызовов | Одностороннее преобразование | поддерж. |
| Переплетение функций | Статический - статистический | автомат. - поддерж. |
| Клонирование функций или базовых блоков | Статический | автомат. - поддерж. |
| Развёртка циклов | Одностороннее преобразование | поддерж. |
| Разложение циклов | Статический | автомат. - поддерж. |
| Введение диспетчера | Статический - статистический | автомат., полуавтомат. |
| Локализация переменных в базовом блоке | Статический - статистическийе | автомат., полуавтомат. |
| Расширение области действия переменных | Статический - статистический | автомат., полуавтомат. |
В таблице 2 приведена классификация методов запутывания по отношению к требуемым методам анализа программ. В третьем столбце таблицы указана степень, в которой возможно автоматическое распутывание. Степень автоматизма оценивается по следующей шкале: автоматический - поиск в программе запутанных фрагментов и их распутывание возможны полностью автоматически; полуавтоматический - поиск в программе подозрительных фрагментов и их распутывание по отдельности выполняются автоматически, но пользователь должен подтвердить применение распутывающего преобразования; поддерживаемый - поиск в программе запутанных фрагментов и применение распутывающих преобразований требуют существенного участия человека, но процесс может быть поддержан специальными инструментальными средствами; неавтоматизируемый - автоматизация выполнения распутывающего преобразования принципиально затруднена.
Для некоторых видов запутывающих преобразований требуемые инструменты (синтаксические, статические, статистические) зависят от того, каким способом было реализовано преобразование. Например, непрозрачные предикаты могут быть самого разного вида, от простейших if(0), до очень сложных. Для анализа и устранения простейших непрозрачных предикатов достаточно инструментов уровня синтаксического анализа, которые работают автоматически, а для устранения сложных непрозрачных предикатов требуется статистический анализ, либо сложные инструменты, такие как полуавтоматический доказатель теорем. Поэтому некоторые ячейки таблицы содержат несколько необходимых видов анализа или несколько оценок автоматизируемости.
Аннотация
Запутанной (obfuscated) называется программа, которая на всех допустимых для исходной программы входных данных выдаёт тот же самый результат, что и оригинальная программа, но более трудна для анализа, понимания и модификации. Запутанная программа получается в результате применения к исходной незапутанной программе запутывающих преобразований (obfuscating transformations).
Данная работа посвящена анализу запутывающих преобразований графа потока управления программы (функции), опубликованных в открытой печати, с точки зрения их устойчивости к различным видам анализа программы. В данной работе запутывание изучается на уровне языка Си, то есть исходная программа написана на языке Си, и целевая запутанная программа генерируется также на языке Си.
В работе приведена классификация запутывающих преобразований с точки зрения методов анализа программ, которые могут быть использованы для их распутывания. Показано, что для каждого класса рассмотренных запутывающих преобразований существуют методы анализа, которые позволяют эффективно противодействовать таким преобразованиям. Для иллюстрации этого приведены несколько практических примеров распутывания программ, запутанных как вручную, так и автоматическими запутывателями.
Методы анализа программ
В данном разделе мы рассмотрим методы, которые применяются при анализе программ в компиляторах. Цель таких методов - выявление зависимостей между компонентами программы, что даёт возможность применить определённые оптимизационные преобразования, или накладывает ограничения на проводимые оптимизационные преобразования.
Методы анализа программ могут быть разделены на 4 группы:
Синтаксические. К этой группе относятся методы, основанные только на результатах лексического, синтаксического и семантического анализа программы.
Статические. К этой группе относятся методы анализа потоков управления и данных и методы, основанные на результатах анализа потоков управления и данных. Статические методы анализа работают с программой, не используя информацию о работе программы на конкретных начальных данных.
Динамические. Динамические методы анализа программ используют информацию, полученную в результате "наблюдения" за работой программы на конкретных входных данных. Заметим, что сами по себе динамические методы редко применяются для анализа программ, поскольку, как правило, необходима информация о поведении программы на разных наборах входных данных, которая собирается с помощью статистических методов анализа.
Статистические. Статистические методы используют информацию, собранную в результате значительного количества запусков программы на большом количестве наборов входных данных.
Краткая характеристика важнейших для нас методов анализа программ приведена ниже.
Методы динамического и статистического анализа
Статистический анализ покрытия базовых блоков программы позволяет установить, выполнялся ли когда-либо при выполнении программы на заданном множестве наборов входных данных заданный базовый блок.
Статистическое сравнение трасс позволяет выявить, одинаковы ли трассы программы, полученные при разных запусках на одном и том же наборе входных данных.
Статистическое построение графа потока управления строит граф потока управления на основании информации о порядке следования базовых блоков на одном наборе или на множестве наборов входных данных.
Динамическое продвижение копий вдоль трасс необходимо для точного межпроцедурного анализа зависимостей по данным на основе трассы выполнения программы. Поскольку трасса выполнения программы, по сути, является одним большим базовым блоком, продвижение копий - несложная задача.
Динамическое выделение мёртвого кода позволяет выявить инструкции программы, которые выполнялись при данном запуске программы, но не оказали никакого влияния на результат работы программы. Если анализируется совокупность запусков программы на множестве наборов входных данных, можно говорить о статистическом выделении мёртвого кода.
Динамический слайсинг оставляет в трассе программы только те инструкции, которые повлияли на вычисление данного значения в данной точке программы (прямой динамический слайсинг), или только те инструкции, на которые повлияло присваивание значения данной переменной в данной точке программы.
Заметим, что о точности динамических методов анализа можно говорить, только если известно полное тестовое покрытие программы (построение полного тестового покрытия - алгоритмически неразрешимая задача). В противном случае статистическое выявление свойств программы не позволяет нам утверждать, что данное свойство справедливо на всех допустимых наборах входных данных. Например, условие if (leap_year(current_data)) всегда будет равно значению "истина", если текущий год високосный, и значению "ложь" в противном случае, однако удаление этого ператора из программы приведёт к её неправильной работе.
Поэтому описанные выше динамические методы не могут применяться в автоматическом инструменте анализа программ. Роль этих методов в том, чтобы привлечь внимание пользователя инструмента анализа программ к особенностям работы программы. В дальнейшем пользователь может изучить "подозрительный" фрагмент кода более детально с применением других инструментов, чтобы подтвердить или опровергнуть выдвинутую гипотезу.
Если непрозрачные предикаты и недостижимый код устраняются только на основании статистического анализа, всегда остаётся возможность, что предикат был существенным (как в примере выше). Чтобы всё же упростить программу, можно, например, вынести предположительно недостижимый код из общего графа потока управления функции в обработчик специального исключения, которое возбуждается каждый раз, когда предикат примет значение, отличное от обычного. С одной стороны, граф потока управления и потока данных основной программы в результате упростится, а с другой стороны, программа сохранит свою функциональность.
Методы статического анализа
Статический анализ алиасов (alias analysis) [11] необходим в языках, в которых несколько имён могут быть использованы для доступа к одной и той же области памяти. Например, некоторый элемент массива a может быть адресован в программе как a[0] (каноническое имя элемента массива), как a[j] или вообще как b[-4]. В результате анализа алиасов каждому оператору, выполняющему косвенную запись в память или косвенное чтение из памяти, ставится в соответствие множество имён переменных, которые могут затрагиваться данной операцией.
Если язык допускает алиасы, проведение в той или иной мере анализа указателей необходимо для корректного анализа потоков данных и для преобразования программ. В случае доступа к элементам массивов и полям структур мы можем в простейшем случае предполагать, что считывается или модифицируется сразу весь массив или вся структура. Для указателей или ссылок в простейшем случае ("консервативный" анализ) мы можем исходить из предположения о том, что косвенное чтение из памяти затрагивает все локальные и глобальные переменные, а косвенная запись в память может все их модифицировать. Такая схема слишком груба и в действительности блокирует глубокую трансформацию практически любой программы.
Известно, что общая задача точного анализа указателей как минимум NP-трудна. В настоящее время существуют методы, работающие за полиномиальное время, для указателей на локальные переменные в случае нерекурсивных функций.
Анализ указателей не может быть непосредственно использован для запутывания или распутывания программы, но он является ключевым для точного анализа свойств программы.
Статическое устранение мёртвого кода (dead-code elimination) [19], разд. 18.10. имеет целью выявить в программе код, который выполняется, но не оказывает влияние на результат работы программы.
Статическая минимизация количества переменных (variable minimization) [19], разд. 16.3. имеет целью уменьшить количество используемых в функции локальных переменных за счёт объединения переменных, времена жизни значений в которых не пересекаются, в одну переменную.
Стандартная техника, которая используется для минимизации количества переменных, состоит в построении графа перекрытия переменных с помощью итерационного решения уравнения потока данных и последующей раскраске вершин этого графа в минимальное или близкое к минимальному количество цветов.
Статическое продвижение констант и копий (constant and copy propagation) [19], разд. 12.5, 12.6. заключается в продвижении константных выражений как можно дальше по тексту функции. Если выражение использует только значения переменных, которые в данной точке программы заведомо содержат одно известное при анализе программы значение, такое выражение может быть вычислено на этапе анализа программы. Если в выражении используется переменная, которая в данной точке программы заведомо является копией какой-то другой переменной, в выражение может быть подставлена исходная переменная.
Статический анализ доменов (domain analysis) является расширением алгоритма продвижения констант. Он позволяет определить множество значений, которые может принимать данная переменная в данной точке программы, если это множество не велико.
Статический слайсинг (slicing) [21] - это построение "сокращённой" программы, из которой удалён весь код, не влияющий на вычисление заданной переменной в заданной точке (обратный слайс), но при этом программа остаётся синтаксически и семантически корректной и может быть выполнена. Кроме описанного выше обратного слайсинга разработаны алгоритмы прямого слайсинга. Прямой слайсинг оставляет в программе только те операторы, которые зависят от значения переменной, вычисленного в данной точке программы. Методы слайсинга могут быть полезны при разделении "переплетённых" вычислений, когда одновременно вычисляются две независимые друг от друга величины. Например, в одном цикле может вычисляться скалярное произведение двух векторов, а также минимальный и максимальный элемент каждого вектора, и такие циклы могут быть расщеплены с помощью построения слайсов.
Описание запутывающих преобразований
Запутывающие преобразования можно разделить на несколько групп в зависимости от того, на трансформацию какой из компонент программы они нацелены.
Преобразования форматирования, которые изменяют только внешний вид программы. К этой группе относятся преобразования, удаляющие комментарии, отступы в тексте программы или переименовывающие идентификаторы.
Преобразования структур данных, изменяющие структуры данных, с которыми работает программа. К этой группе относятся, например, преобразование, изменяющее иерархию наследования классов в программе, или преобразование, объединяющее скалярные переменные одного типа в массив. В данной работе мы не будем рассматривать запутывающие преобразования этого типа.
Преобразования потока управления программы, которые изменяют структуру её графа потока управления, такие как развёртка циклов, выделение фрагментов кода в процедуры, и другие. Данная статья посвящена анализу именно этого класса запутывающих преобразований.
Превентивные преобразования, нацеленные против определённых методов декомпиляции программ или использующие ошибки в определённых инструментальных средствах декомпиляции.
Определение
Приводимое здесь определение сформулировано В. А. Захаровым.
Эффективное вычисление - это вычисление, требующее полиномиального от длины входа времени и полиномиальной от длины входа памяти. Эффективная программа (машина Тьюринга) - программа, работающая полиномиальное от длины входа время и требующая полиномиальную от длины входа рабочую память на всех входах, на которых программа завершается.
Пусть П - множество всех программ (машин Тьюринга), удовлетворяющих сформулированным выше ограничениям, и пусть программа p

подмножество

Пусть


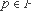
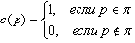
Другими словами, для функционального свойства
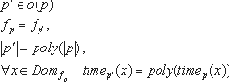
Здесь у=poly(x) означает, что y ограничен полиномом некоторой степени от переменной x ,timep(x) - время выполнения программы p на входе x , |p| - размер программы p.
b) (трудность определения свойств по запутанной программе). Для любого полинома q и для любой программы (вероятностной машины Тьюринга) a такой, что a(o(P))={0,1} , и для любой

Другими словами, вероятность определить свойство
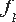
Универсальный запутыватель - это программа O , которая для любого класса программ P и любого свойства
Практическое использование
В данном разделе мы приведём примеры использования арсенала анализирующих преобразований для анализа запутанных программ.
Преобразования форматирования
К преобразованиям форматирования относятся удаление комментариев, переформатирование программы, удаление отладочной информации, изменение имён идентификаторов.
Удаление комментариев и переформатирование программы применимы, когда запутывание выполняется на уровне исходного кода программы. Эти преобразования не требуют только лексического анализа программы. Хотя удаление комментариев - одностороннее преобразование, их отсутствие не затрудняет сильно обратную инженерию программы, так как при обратной инженерии наличие хороших комментариев к коду программы является скорее исключением, чем правилом. При переформатировании программы исходное форматирование теряется безвозвратно, но программа всегда может быть переформатирована с использованием какого-либо инструмента для автоматического форматирования программ (например, indent для программ на Си).
Удаление отладочной информации применимо, когда запутывание выполняется на уровне объектной программы. Удаление отладочной информации приводит к тому, что имена локальных переменных становятся невосстановимы.
Изменение имён локальных переменных требует семантического анализа (привязки имён) в пределах одной функции. Изменение имён всех переменных и функций программы помимо полной привязки имён в каждой единице компиляции требует анализа межмодульных связей. Имена, определённые в программе и не используемые во внешних библиотеках, могут быть изменены произвольным, но согласованным во всех единицах компиляции образом, в то время как имена библиотечных переменных и функций меняться не могут. Данное преобразование может заменять имена на короткие автоматически генерируемые имена (например, все переменные программы получат имя v в соответствии с их некоторым порядковым номером). С другой стороны, имена переменных могут быть заменены на длинные, но бессмысленные (случайные) идентификаторы в расчёте на то, что длинные имена хуже воспринимаются человеком.
Преобразования потока управления
Преобразования потока управления изменяют граф потока управления одной функции. Они могут приводить к созданию в программе новых функций. Краткая характеристика методов приведена ниже.
Открытая вставка функций (function inlining) [5], п. 6.3.1 заключается в том, что тело функции подставляется в точку вызова функции. Данное преобразование является стандартным для оптимизирующих компиляторов. Это преобразование одностороннее, то есть по преобразованной программе автоматически восстановить вставленные функции невозможно. В рамках данной статьи мы не будем рассматривать подробно прямую вставку функций и её эффект на запутывание и распутывание программ.
Вынос группы операторов (function outlining) [5], п. 6.3.1. Данное преобразование является обратным к предыдущему и хорошо дополняет его. Некоторая группа операторов исходной программы выделяется в отдельную функцию. При необходимости создаются формальные параметры. Преобразование может быть легко обращено компилятором, который (как было сказано выше) может подставлять тела функций в точки их вызова.
Отметим, что выделение операторов в отдельную функцию является сложным для запутывателя преобразованием. Запутыватель должен провести глубокий анализ графа потока управления и потока данных с учётом указателей, чтобы быть уверенным, что преобразование не нарушит работу программы.
Непрозрачные предикаты (opaque predicates) [5], п. 6.1. Основной проблемой при проектировании запутывающих преобразований графа потока управления является то, как сделать их не только дешёвыми, но и устойчивыми. Для обеспечения устойчивости многие преобразования основываются на введении непрозрачных переменных и предикатов. Сила таких преобразований зависит от сложности анализа непрозрачных предикатов и переменных.
Переменная v является непрозрачной, если существует свойство
Непрозрачные предикаты могут быть трёх видов: PF - предикат, который всегда имеет значение "ложь", PT - предикат, который всегда имеет значение "истина", и P? - предикат, который может принимать оба значения, и в момент запутывания текущее значение предиката известно.
В работах [3], [7], [23] разработаны методы построения непрозрачных предикатов и переменных, основанные на "встраивании" в программу вычислительно сложных задач, например, задачи 3-выполнимости . Некоторые возможные способы введения непрозрачных предикатов и непрозрачных выражений вкратце перечислены ниже.
Использование разных способов доступа к элементы массива [23]. Например, в программе может быть создан массив (скажем, a), который инициализируется заранее известными значениями, далее в программу добавляются несколько переменных (скажем, i}, j), в которых хранятся индексы элементов этого массива. Теперь непрозрачные предикаты могут иметь вид a[i] == a[j]. Если к тому же переменные i} и j в программе изменяются, существующие сейчас методы статического анализа алиасов позволят только определить, что и i, и j могут указывать на любой элемент массива a.
Использование указателей на специально создаваемые динамические структуры [7]. В этом подходе в программу добавляются операции по созданию ссылочных структур данных (списков, деревьев), и добавляются операции над указателями на эти структуры, подобранные таким образом, чтобы сохранялись некоторые инварианты, которые и используются как непрозрачные предикаты.
Конструирование булевских выражений специального вида [3].
Построение сложных булевских выражений с помощью эквивалентных преобразований из формулы true. В простейшем случае мы можем взять k произвольных булевских переменных x1...xk и построить из них тождество

Использование комбинаторных тождеств, например
Внесение недостижимого кода (adding unreachable code). Если в программу внесены непрозрачные предикаты видов PF или PT, ветки условия, соответствующие условию "истина" в первом случае и условию "ложь" во втором случае, никогда не будут выполняться. Фрагмент программы, который никогда не выполняется, называется недостижимым кодом. Эти ветки могут быть заполнены произвольными вычислениями, которые могут быть похожи на действительно выполняемый код, например, собраны из фрагментов той же самой функции. Поскольку недостижимый код никогда не выполняется, данное преобразование влияет только на размер запутанной программы, но не на скорость её выполнения. Общая задача обнаружения недостижимого кода, как известно, алгоритмически неразрешима. Это значит, что для выявления недостижимого кода должны применяться различные эвристические методы, например, основанные на статистическом анализе программы.
Внесение мёртвого кода (adding dead code) [5], п. 6.2.1. В отличие от недостижимого кода, мёртвый код в программе выполняется, но его выполнение никак не влияет на результат работы программы. При внесении мёртвого кода запутыватель должен быть уверен, что вставляемый фрагмент не может влиять на код, который вычисляет значение функции. Это практически значит, что мёртвый код не может иметь побочного эффекта, даже в виде модификации глобальных переменных, не может изменять окружение работающей программы, не может выполнять никаких операций, которые могут вызвать исключение в работе программы.
Внесение избыточного кода (adding redundant code) [5], п. 6.2.6. Избыточный код, в отличие от мёртвого кода выполняется, и результат его выполнения используется в дальнейшем в программе, но такой код можно упростить или совсем удалить, так как вычисляется либо константное значение, либо значение, уже вычисленное ранее. Для внесения избыточного кода можно использовать алгебраические преобразования выражений исходной программы или введение в программу математических тождеств.
Например, можно воспользоваться комбинаторным тождеством

Подобные алгебраические преобразования ограничены целыми значениями, так как при выполнении операций с плавающей точкой возникает проблема накопления ошибки вычислений. Например, выражение sin2x+cso2x при вычислении на машине практически никогда не даст в результате значение 1. С другой стороны, при операциях с целыми значениями возникает проблема переполнения. Например, если использование 32-битной целой переменной x заменено на выражение x * p / q, где p и q гарантированно имеют одно и то же значение, при выполнении умножения x * p может произойти переполнение разрядной сетки, и после деления на q получится результат не равный p. В качестве частичного решения задачи можно выполнять умножение в 64-битных целых числах.
Преобразование сводимого графа потока управления к несводимому (transforming reducible to non-reducible flow graph) [5], п. 6.2.3. Когда целевой язык (байт-код или машинный язык) более выразителен, чем исходный, можно использовать преобразования, "противоречащие" структуре исходного языка. В результате таких преобразований получаются последовательности инструкций целевого языка, не соответствующие ни одной из конструкций исходного языка.
Например, байт-код виртуальной машины Java содержит инструкцию goto, в то время как в языке Java оператор goto отсутствует. Графы потока управления программ на языке Java оказываются всегда сводимыми, в то время как в байт-коде могут быть представлены и несводимые графы.
Можно предложить запутывающее преобразование, которое трансформирует сводимые графы потока управления функций в байт-коде, получаемых в результате компиляции Java-программ, в несводимые графы. Например, такое преобразование может заключаться в трансформации структурного цикла в цикл с множественными заголовками с использованием непрозрачных предикатов.
С одной стороны, декомпилятор может попытаться выполнить обратное преобразование, устраняя несводимые области в графе, дублируя вершины или вводя новые булевские переменные. С другой строны, распутыватель может с помощью статических или статистических методов анализа определить значение непрозрачных предикатов, использованных при запутывании, и устранить никогда не выполняющиеся переходы. Однако, если догадка о значении предиката окажется неверна, в результате получится неправильная программа.
Устранение библиотечных вызовов (eliminating library calls) [5], п. 6.2.4. Большинство программ на языке Java существенно используют стандартные библиотеки. Поскольку семантика библиотечных функций хорошо известна, такие вызовы могут дать полезную информацию при обратной инженерии программ. Проблема усугубляется ещё и тем, что ссылки на классы библиотеки Java всегда являются именами, и эти имена не могут быть искажены.
Во многих случаях можно обойти это обстоятельство, просто используя в программе собственные версии стандартных библиотек. Такое преобразование не изменит существенно время выполнения программы, зато значительно увеличит её размер и может сделать её непереносимой.
Для программ на традиционных языках эта проблема стоит менее остро, так как стандартные библиотеки, как правило, могут быть скомпонованы статически вместе с самой программой. В данном случае программа не содержит никаких имён функций из стандартной библиотеки.
Переплетение функции (function interleaving) [5], п. 6.3.2. Идея этого запутывающего преобразования в том, что две или более функций объединяются в одну функцию. Списки параметров исходных функций объединяются, и к ним добавляется ещё один параметр, который позволяет определить, какая функция в действительности выполняется.
Клонирование функций (function cloning) [5], п. 6.3.3. При обратной инженерии функций в первую очередь изучается сигнатура функции, а также то, как эта функция используется, в каких местах программы, с какими параметрами и в каком окружении вызывается.
Анализ контекста использования функции можно затруднить, если каждый вызов некоторой функции будет выглядеть как вызов какой-то другой, каждый раз новой функции. Может быть создано несколько клонов функции, и к каждому из клонов будет применён разный набор запутывающих преобразований.
Развёртка циклов (loop unrolling) [5], п. 6.3.4. Развёртка циклов применяется в оптимизирующих компиляторах для ускорения работы циклов или их распараллеливания. Развёрка циклов заключается в том, что тело цикла размножается два или более раз, условие выхода из цикла и оператор приращения счётчика соответствующим образом модифицируются. Если количество повторений цикла известно в момент компиляции, цикл может быть развёрнут полностью.
Разложение циклов (loop fission) [5], п. 6.3.4. Разложение циклов состоит в том, что цикл с сложным телом разбивается на несколько отдельных циклов с простыми телами и с тем же пространством итерирования.
Реструктуризация графа потока управления [24]. Структура графа потока управления, наличие в графе потока управления характерных шаблонов для циклов, условных операторов и т. д. даёт ценную информацию при анализе программы. Например, по повторяющимся конструкциям графа потока управления можно легко установить, что над функцией было выполнено преобразование развёртки циклов, а далее можно запустить специальные инструменты, которые проанализируют развёрнутые итерации цикла для выделения индуктивных переменных и свёртки цикла. В качестве меры противодействия может быть применено такое преобразование графа потока управления, которое приводит граф к однородному ("плоскому") виду. Операторы передачи управления на следующие за ними базовые блоки, расположенные на концах базовых блоков, заменяются на операторы передачи управления на специально созданный базовый блок диспетчера, который по предыдущему базовому блоку и управляющим переменным вычисляет следующий блок и передаёт на него управление. Технически это может быть сделано перенумерованием всех базовых блоков и введением новой переменной, например state, которая содержит номер текущего исполняемого базового блока.
Запутанная функция вместо операторов if, for и т. д. будет содержать оператор switch, расположенный внутри бесконечного цикла.
Локализация переменных в базовом блоке [3]. Это преобразование локализует использование переменных одним базовым блоком. Для каждого запутываемого базового блока функции создаётся свой набор переменных. Все использования локальных и глобальных переменных в исходном базовом блоке заменяются на использование соответствующих новых переменных. Чтобы обеспечить правильную работу программы между базовыми блоками вставляются так называемые связующие (connective) базовые блоки, задача которых скопировать выходные переменные предыдущего базового блока в входные переменные следующего базового блока.
Применение такого запутывающего преобразование приводит к появлению в функции большого числа новых переменных, которые, однако, используются только в одном-двух базовых блоках, что запутывает человека, анализирующего программу.
При реализации этого запутывающего преобразования возникает необходимость точного анализа указателей и контекстно-зависимого межпроцедурного анализа. В противном случае нельзя гарантировать, что запись по какому-либо указателю или вызов функции не модифицируют настоящую переменную, а не текущую рабочую копию.
Расширение области действия переменных [5], п. 7.1.2. Данное преобразование по смыслу обратно предыдущему. Это преобразование пытается увеличить время жизни переменных настолько, насколько можно. Например, вынося блочную переменную на уровень функции или вынося локальную переменную на статический уровень, расширяется область действия переменной и усложняется анализ программы. Здесь используется то, что глобальные методы анализа (то есть, методы, работающие над одной функцией в целом) хорошо обрабатывают локальные переменные, но для работы со статическими переменными требуются более сложные методы межпроцедурного анализа.
Для дальнейшего запутывания можно объединить несколько таких статических переменных в одну переменную, если точно известно, что переменные не могут использоваться одновременно.Очевидно, что преобразование может применяться только к функциям, которые никогда не вызывают друг друга непосредственно или через цепочку других вызовов.
Применение запутывающих преобразований
Существующие методы запутывания и инструменты для запутывания программ используют не единственное запутывающее преобразование, а некоторую их комбинацию. В данном разделе мы рассмотрим некоторые используемые на практике методы запутывания.
В работах Ч. Ванг [23][24] предлагается метод запутывания, и описывается его реализация в инструменте для запутывания программ на языке Си. Предложенный метод запутывания использует преобразование введения "диспетчера" в запутываемую функцию. Номер следующего базового блока вычисляется непосредственно в самом выполняющемся базовом блоке прямым присваиванием переменной, которая хранит номер текущего базового блока. Для того чтобы затруднить статический анализ, номера базовых блоков помещаются в массив, каждый элемент которого индексируется несколькими разными способами. Таким образом, для статического прослеживания порядка выполнения базовых блоков необходимо провести анализ указателей.
В работе [3] предлагается метод запутывания, основанный на следущих запутывающих преобразованиях: каждый базовый блок запутываемой функции разбивается на более мелкие части (т. н. piece) и клонируется один или несколько раз. В каждом фрагменте базового блока переменные локализуются, и для связывания базовых блоков создаются специальные связующие базовые блоки. Далее в каждый фрагмент вводится мёртвый код. Источником мёртвого кода может быть, например, фрагмент другого базового блока той же самой функции или фрагмент базового блока другой функции. Поскольку каждый фрагмент использует свой набор переменных, объединяться они могут безболезненно (при условии отсутствия в программе указателей и вызовов функций с побочным эффектом). Далее из таких комбинированных фрагментов собирается новая функция, в которой для переключения между базовыми блоками используется диспетчер. Диспетчер принимает в качестве параметров номер предыдущего базового блока и набор булевских переменных, которые используются в базовых блоках для вычисления условий перехода, и вычисляет номер следующего блока.
При этом следующий блок может выбираться из нескольких эквивалентных блоков, полученных в результате клонирования. Выражая функцию перехода в виде булевской формулы, можно добиться того, что задача статического анализа диспетчера будет PSPACE-полна. Работа [3] описывает алгоритм запутывания, но не указывает, реализован ли этот алгоритм в какой-либо системе.
Запутыватели для языка Java, например Zelix KlassMaster [25], как правило, используют следующее сочетание преобразований: из .class-файлов удаляется вся отладочная информация, включая имена локальных переменных; классы и методы переименовываются в короткие и семантически неосмысленные имена; граф потока управления запутываемой функции преобразовывается к несводимому графу, чтобы затруднить декомпиляцию обратно в язык Java.
Побочным эффектом такого запутывания является существенное ускорение работы программы. Во-первых, удаление отладочной информации делает .class|-файлы существенно меньше, и соответственно их загрузка (особенно по медленным каналам связи) ускоряется. Во-вторых, резкое уменьшение длины имён методов приводит к тому, что ускоряется поиск метода по имени, выполняемый каждый раз при вызове. Как следствие, запутывание Java-программ часто рассматривается как один из способов их оптимизации.
Список литературы
А. В. Чернов. Интегрированная среда для исследования "обфускации" программ. Доклад на конференции, посвящённой 90-летию со дня рождения А.А.Ляпунова. Россия, Новосибирск, 8-11 октября 2001 года. http://www.ict.nsc.ru/ws/Lyap2001/2350/
B. Barak, O. Goldreich, R. Impagliazzo, S. Rudich, A. Sahai, S. Vadhan, K. Yang. On the (Im)possibility of Obfuscating Programs. LNCS, 2001, 2139, pp. 1-18. S. Chow, Y. Gu, H. Johnson, V. Zakharov. An approach to the obfuscation of control-flow of sequential computer programs. LNCS, 2001, 2200, pp. 144-155. C. Cifuentes, K. J. Gough. Decompilation of Binary Programs. Technical report FIT-TR-1994-03. Queensland University of Technology, 1994. http://www.fit.qut.edu.au/TR/techreports/FIT-TR-94-03.ps
C. Collberg, C. Thomborson, D. Low. A Taxonomy of Obfuscating Transformations. Department of Computer Science, The University of Auckland, 1997. http://www.cs.arizona.edu/~collberg/Research/Publications/CollbergThomborsonLow97a
C. Collberg, C. Thomborson, D. Low. Breaking Abstractions and Unstructuring Data Structures. In IEEE International Conference on Computer Languages, ICCL'98, Chicago, IL, May 1998. C. Collberg, C. Thomborson, D. Low. Manufacturing Cheap, Resilient, and Stealthy Opaque Constructs. In Principles of Programming Languages 1998, POPL'98, San Diego, CA, January 1998. C. Collberg, C. Thomborson. On the Limits of Software Watermarking. Technical Report #164. Department of Computer Science, The University of Auckland, 1998. http://www.cs.arizona.edu/~collberg/Research/Publications/CollbergThomborson98e
C. Collberg, C. Thomborson. Watermarking, Tamper-Proofing, and Obfuscation - Tools for Software Protection. Technical Report 2000-03. Department of Computer Science, University of Arizona, 2000. http://www.cs.arizona.edu/~collberg/Research/Publications/CollbergThomborson2000a
G. Hachez, C. Vasserot. State of the Art in Software Protection. Project FILIGRANE (Flexible IPR for Software Agent Reliance) deliverable/V2.
http://www.dice.ucl.ac.be/crypto/filigrane/External/d21.pdf
M. Hind, A. Pioli. Which pointer analysis should I use? In ACM SIGSOFT International Symposium on Software Testing and Analysis, pp. 113-123, August 2000. The International Obfuscated C Code Contest. http://www.ioccc.org
M. Jalali, G. Hachez, C. Vasserot. FILIGRANE (Flexible IPR for Software Agent Reliance). A security framework for trading of mobile code in Internet. In Autonomous Agent 2000 Workshop: Agents in Industry, 2000. H. Lai. A comparative survey of Java obfuscators available on the Internet. http://www.cs.auckland.ac.nz/~cthombor/Students/hlai
D. Low. Java Control Flow Obfuscation. MSc Thesis. University of Auckland, 1998. http://www.cs.arizona.edu/~collberg/Research/Students/DouglasLow/thesis.ps
J. MacDonald. On Program Security and Obfuscation. 1998. http://www.xcf.berkeley.edu/~jmacd/cs261.pdf
M. Mambo, T. Murayama, E. Okamoto. A Tentative Approach to Constructing Tamper-Resistant Software. In ACM New Security Paradigms Workshop, Langdale, Cumbria UK, 1998. A. von Mayrhauser, A. M. Vans. Program Understanding: Models and Experiments. In M. Yovits, M. Zelkowitz (eds.), Advances in Computers, Vol. 40, 1995. San Diego: Academic Press, pp. 1-38. S. Muchnick. Advanced Compiler Design and Implementation. Morgan Kaufmann Publishers, 1997. SourceAgain Java decompiler. http://www.ahpah.com
F. Tip. A survey of program slicing techniques. Journal of Programming Languages, 3(3): 121-189, September 1995. E. Walle. Methodology and Applications of Program Code Obfuscation. Faculty of Computer and Electrical Engineering, University of Waterloo, 2001. http://walle.dyndns.org/morass/misc/wtr3b.doc C. Wang. A Security Architecture for Survivability Mechanisms. PhD Thesis. Department of Computer Science, University of Virginia, 2000. http://www.cs.virginia.edu/~survive/pub/wangthesis.pdf
C. Wang, J. Davidson, J. Hill, J. Knight. Protection of Software-based Survivability Mechanisms. Department of Computer Science, University of Virginia, 2001.http://www.cs.virginia.edu/~jck/publications/dsn_distribute.pdf
Zelix KlassMaster Java Code Obfuscator and Obfuscation. http://www.zelix.com
Стоимость запутывающих преобразований
Запутывание преобразует программу, затрудняя её обратную инженерию. В результате запутанная программа может оказаться больше по размеру и работать медленнее. Стоимость (cost) преобразования [5] - это метрика, которая позволяет оценить, насколько больше требуется ресурсов (памяти, процессорного времени) для выполнения запутанной программы, чем для выполнения исходной программы. Стоимость определяется по следующей шкале: (бесплатная, дешёвая, умеренная, дорогая).
Стоимость преобразования позволяет оценить, насколько увеличивается размер функции в результате запутывания. Бесплатное преобразование увеличивает размер функции на O(1), дешевое преобразование увеличивает размер на O(m), где m - размер функции, умеренное по стоимости преобразование увеличивает размер функции на O(mp), где p>1. Наконец, дорогое преобразование экспоненциально увеличивает размер запутанной функции по сравнению с исходной.
Стоимость выполнения позволяет оценить, насколько больше требуется ресурсов при выполнении программы. Стоимость оценивается как функция от характерного размера входных данных n.
Преобразование оценивается как бесплатное, если выполнение преобразованной программы p` требует на O(1) больше ресурсов, чем выполнение оригинальной программы. Преобразование оценивается как дешёвое, если выполнение программы p` требует на O(n) ресурсов больше, чем выполнение исходной программы, где n - размер входных данных. Преобразование оценивается как умеренное по стоимости, если выполнение программы p` требует на O(np) больше ресурсов, где p>1 . Преобразование оценивается как дорогое, если выполнение программы p` требует экспоненциально больше ресурсов, чем выполнение исходной программы. Практически применимыми являются, по-видимому, только бесплатные и дешёвые методы запутывания.
Устранение диспетчера на основе динамического анализа
Рассмотрим в качестве простейшего примера запутывание функции fib, которая принимает один параметр n и вычисляет n-е число Фибоначчи. Преобразуем её граф потока управления введением диспетчера. Текст исходной функции и текст функции с введённым диспетчером приведены на рис. 1.

Рис. 1. Исходный текст функции fib и её запутанный вариант

Рис. 2. Граф потока управления исходной и запутанной функции fib
Рис. 3. Исходный граф потока управления функции и восстановленный по трассам граф потока управления функции.
Для анализа запутанной программы были проделаны следующие действия:
Запутанная программа была проинструментирована для сбора трасс. В начало каждого базового блока был добавлен вызов специальной функции, которая записывала в файл трассы номер базового блока.
По собранным трассам был построен граф потока управления, вид которого совпадал с графом потока управления запутанной функции, поскольку собранные трассы обеспечивали полное покрытие.
Поскольку граф потока управления, построенный по трассам, имел характерную регулярную структуру, указывающую на использование диспетчера, блок диспетчера был в трассах проигнорирован, что позволило вскрыть изначальный порядок следования базовых блоков в функции.
Сравнение графа потока управления исходной программы и графа потока управления, полученного в результате анализа трасс, приведено на рис. 3.
Устранение мёртвого кода и свёртка циклов
В качестве третьего примера мы опишем анализ программы, запутанной одним из коммерческих запутывателей программ на Си. Распутывание программы состояло из следующих шагов.
Был построен граф потока управления запутанной программы. Вид графа показал, что запутанная программа имеет две ветки условного оператора, не отличающиеся структурой потока управления друг от друга. Каждая из веток состояла из повторяющегося 8 раз фрагмента, что позволило предположить, что при запутывании была выполнена развёртка цикла.
Поскольку запутанная программа была представлена на языке Си, и содержала некоторые конструкции, использованные специально для увеличения размера и затруднения восприятия программы, все избыточные конструкции (ключевое слово register, ключевое слово signed в типе signed int, ненужные приведения типов и ненужные скобки) были удалены. В результате размер программы сократился на 20 Кб.
Далее было проведено статическое устранение мёртвого кода, которое позволило уменьшить размер программы до 64 Кб.
Далее была выполнена минимизация количества локальных переменных. Запутанная программа определяла в начале функции около 800 локальных переменных, время жизни которых в функции было невелико. Был применён алгоритм минимизации количества переменных, который выявил всего 11 необходимых переменных. Лишние определения переменных были удалены. Новые переменные получили имена вида r_1, r_2 вместо использовавшихся в запутанной программе имён вида r_dddddd, где d - десятичная цифра. В результате всех преобразований размер программы сократился до 26 Кб.
Далее в программы были выполнены преобразования по свёртке цикла. Были идентифицированы точные границы итерации цикла; все тела итерации цикла были сопоставлены друг с другом, в результате определились места, зависящие от номера итерации; выражения, зависящие от номера итерации, были переписаны в виде, позволившем ввести переменную цикла. Данные шаги были проведены полуавтоматически с использованием простейших средств сравнения базовых блоков (на текстуальном уровне). Это преобразование привело к тому, что размер программы достиг 3.5 Кб.
На заключительном шаге, применив эквивалентные алгебраические преобразования и выявив принципы кодирования данных, программа была ещё более упрощена. Размер программы составил примерно 1.5 Кб, структура потока управления и структура данных, с которыми манипулировала программа, стали полностю очевидны. Текст распутанной программы приведен на рис. 6.
В данной работе исследуется проблема
В данной работе исследуется проблема анализа запутывающих преобразований графа потока управления функций на языке Си. В работе сделана попытка анализа запутывающих преобразований, опубликованных в открытой печати, с точки зрения их устойчивости к различным видам статического и динамического анализа программ. Запутывание изучается на уровне языка Си, то есть и исходная программа написана на языке Си, и целевая запутанная программа генерируется также на языке Си.
В работе приведена классификация запутывающих преобразований с точки зрения методов анализа программ, которые могут быть использованы для их распутывания. Показано, что для каждого класса рассмотренных запутывающих преобразований существуют методы анализа, которые позволяют эффективно противодействовать таким преобразованиям. Для иллюстрации этого приведены несколько практических примеров распутывания программ, запутанных как вручную, так и автоматическими запутывателями.
Задачи запутывания и анализа запутанных программ имеют три аспекта: теоретический, включающий в себя разработку новых алгоритмов преобразования графа потока управления или трансформации данных программы, а также теоретическую оценку сложности их анализа и раскрытия. Прикладной аспект включает в себя разработку конкретных методов запутывания (распутывания), то есть наилучших комбинаций алгоритмов, эмпирический сравнительный анализ различных методов, эмпирический анализ устойчивости методов, и т. д.
Третий аспект, психологический пока не поддаётся формализации, но не может игнорироваться. Обратная инженерия (понимание) программ - это процесс, результатом которого является некоторое знание субъекта, изучающего программу, который является неотъемлемой частью процесса понимания [18]. Методы запутывания должны максимально использовать свойства (точнее, слабости) человеческой психики.
Не умаляя ценности теоретических исследований, следует заметить, что теоретические выводы должны подтверждаться результатами практического применения предложенных методов.
В данной работе исследуется прикладной аспект задачи запутывания.
В настоящее время широко распространены языки программирования, такие как Java, в которых "исполняемой" формой программы является не машинный код для некоторого типа процессоров, но машинно-нейтральное представление. Задача декомпиляции программы из такого представления обратно в программу на языке Java значительно проще, чем декомпиляция из машинного кода. Существует большое число декомпиляторов для языка Java как распространяемых свободно, так и коммерческих, например [20], что упрощает несанкционированное использование, обратную инженерию и модификацию Java-программ. В качестве одного из способов борьбы с этим рассматривается запутывание программ.
Уже разработано около двух десятков различных запутывателей Java-программ, среди которых есть и коммерческие, например [25]. Простые запутыватели удаляют таблицы символов и отладочную информацию из скомпилированных классов и заменяют исходные имена методов бессмысленными короткими именами. В результате размер файлов уменьшается (до 50\%), а скорость выполнения программы значительно возрастает, поэтому такое запутывание может рассматриваться и как один из способов оптимизации программ. Более развитые запутыватели программ на языке Java, а также запутыватели программ на других языках программирования выполняют преобразования графа потока управления программы и её структур данных. Методы, используемые в них, как правило, подобраны эмпирически и слабо обоснованы теоретически. Сравнительный анализ запутывателей Java-программ, доступных через Интернет, проведён в работе [14].
Возможны разные уровни постановки задачи запутывания и анализа запутывающих преобразований. Во-первых, запутывание может рассматриваться в рамках языка Java. В этом случае исходная программа написана на языке Java, и запутанная программа также написана на языке Java. Однако язык Java допускает только структурные программы, то есть графы потока управления Java-программ всегда сводимые, что существенно ограничивает диапазон применимых преобразований графа потока управления.
Мы рассматриваем задачу анализа запутывающих преобразований в рамках языка Си. Поскольку Си - язык более низкого уровня, чем Java или даже байт-код Java, задачи запутывания и анализа для этих языков оказываются вложенными в соответствующие задачи для языка Си.
Возможна постановка задачи запутывания на ещё более низком уровне, когда запутывается программа на языке ассемблера или даже объектная программа в машинном коде (в последнем случае она должна генерироваться специальным запутывающим компилятором). В ассемблерных и объектных программах можно использовать специфические особенности работы целевой машины, добившись того, что восстановление программы на Си будет крайне затруднено [17]. Но с другой стороны, методы запутывания, применимые к одной архитектуре, могут оказаться неприменимы к другой архитектуре. Заметим, что проблема низкоуровневого запутывания в настоящее время исследована слабо. Нам не известно каких-либо опубликованных методов низкоуровневого запутывания программ, поэтому проблему низкоуровневого запутывания мы в этой работе рассматривать не будем.
Если программа для анализа представлена в исполняемом или объектном коде, и известно, что к программе не применялись низкоуровневые методы запутывания, задача анализа таких программ может быть разбита на две относительно независимых подзадачи. На первом этапе программа декомпилируется [4] в программу на языке Си, затем программа на языке Си распутывается, то есть применяются алгоритмы анализа программ, которые приводят к её возможной перестройке, выделению в ней циклов, условных операторов и других конструкций высокого уровня. Декомпиляция программ - самостоятельная задача, которая может решаться отдельно.
В данной работе мы ограничим класс запутываемых программ программами пакетной обработки, то есть программами, которые получают все исходные данные в начале работы и выдают результат по ходу работы. Во время работы программа не взаимодействует с пользователем и другими программами. Кроме того, потребуем, чтобы программа не использовала аппарат исключений в работе.
Появление исключительной ситуации приводит к завершению работы программы. Эти ограничения связаны с тем, что все опубликованные методы запутывания применимы только к таким программам.
Запутывание программ - достаточно молодое направление исследований. Обзор (таксономия) запутывающих преобразований, известных на тот момент, был опубликован в работе [5] группы, возглавляемой К. Колбергом и К. Томборсоном. В дальнейших работах [6], [7],[8], [9], [15] этой группы опубликованы результаты исследований конкретных алгоритмов запутывания графа потока управления и данных программы, а также приложения запутывания программ к смежным областям, таким как обеспечение устойчивости программы к несанкционированной модификации (tamper-resistance) или внесение в программу "водяных знаков" (watermarking).
Классификация, введённая в работе [5], широко используется, и получила дальнейшее развитие в работах [10], [13], [22].
В работах [23], [24] был предложен новый подход к запутыванию графа потока управления программы, который заключается в преобразовании графа в "плоскую" форму. Чтобы затруднить статическое определение порядка следования базовых блоков используется преобразование, вводящее в программу алиасы. Показывается, что статический анализ запутанной программы с целью восстановления порядка следования базовых блоков является NP-трудной задачей.
В дальнейшем этот подход был развит в работе [3], которая дополнительно предлагает использовать переплетение базовых блоков совместно запутываемых функций и недетерминированный выбор следующего базового блока из множества эквивалентных альтернатив. Доказывается, что статический анализ запутанной программы с целью восстановления порядка следования базовых блоков является PSPACE-трудной задачей.
В работе [2] получен результат, который определяет верхний предел силы запутывающих преобразований. Авторы доказали, что универсального запутывателя не существует. Под универсальным понимается такой запутыватель, который для любой программы строит запутанную программу, такую что определение любого свойства программы, легко определимого по исходной программе, неэффективно по запутанной программе.
Тем не менее, можно показать, что если взять некоторое специальное свойство программ, то запутыватель для этого свойства всё же существует. Вопрос о том, для каких классов программ и каких свойств запутыватель существует, остаётся открытым. В данной работе рассматриваются только запутывающие преобразования графа потока управления программы. Мы сознательно оставляем в стороне преобразования данных программы, а также так называемые превентивные преобразования, которые нацелены против определённых методик декомпиляции программы, реализованных в определённых декомпиляторах.
Мы не пытаемся подтвердить или опровергнуть тезис работы [2] о невозможности запутывания программ, но мы делаем попытку показать, что для всех опубликованных в открытой печати методов запутывания программ существуют достаточно эффективные практически, хотя, возможно, пока не совсем обоснованные теоретически способы противодействия.
Данная работа имеет следующую структуру. В разделе 2 даётся формальное определение понятия запутывания, приводится классификация запутывающих преобразований, описываются запутывающие преобразования графа потока управления. В разделе 3 описываются наиболее важные методы, которые применяются на различных стадиях работы компилятора и могут быть использованы для получения информации о запутанной программе, а также специальные методы анализа запутанных программ. В разделе 4 методы запутывания программ сопоставляются с методами их анализа, вводится классификация методов запутывания по уровню необходимых преобразований распутывания. В разделе 0 приводятся примеры применения некоторых методов анализа программы для распутывания программ. Наконец, в разделе 5.3 подводятся итоги и указываются направления дальнейшей работы.
В данной работе мы рассмотрели
В данной работе мы рассмотрели запутывание программ с точки зрения устойчивости запутывающих преобразований к различным методам статического и динамического анализа программ. Мы сделали попытку определить, какие методы анализа программ могут использоваться для противодействия большинству из описанных методов запутывания программ. Для иллюстрации нашего подхода мы привели примеры распутывания программ, запутанных как вручную, так и с помощью специальных запутывателей.
Поскольку теория запутывания программ сейчас находится в стадии активного формирования, кроме того, разрабатываются всё новые и новые эмпирические методы запутывания, существует потребность в среде как наборе инструментов, которая выступает в роли "испытательного стенда" для проверки как теоретических положений, так и новых методов запутывания. Для исследования различных вопросов, связанных с запутыванием программ, нами разрабатывается интегрированная среда (ИС) для изучения запутывания программ Poirot [1].
Цель разработки - получить удобную и мощную ИС для исследования методов и алгоритмов преобразования программ. С её помощью можно быстро получить прототип нового запутывающего преобразования программ, проверить его устойчивость против разнообразных известных методов анализа, либо проверять устойчивость уже существующих алгоритмов запутывания программ. ИС Poirot уже содержит многие инструменты синтаксического, статического, динамического и статического анализа, с помощью которых можно анализировать методы запутывания программ и сами запутанные программы. Заметим, что такая ИС полезна и потому, что реализация методов анализа программ, описанных выше, намного более трудоёмка, чем их использование, а польза этих методов несомненна.
Как было уже упомянуто выше, методы запутывания должны учитывать свойства человеческой психики и пытаться ставить в тупик человека, который управляет системой анализа программ. Можно отметить следующие свойства, которым должна удовлетворять запутанная программа:
Запутывание должно быть замаскированным. То, что к программе были применены запутывающие преобразования, не должно бросаться в глаза.
Запутывание не должно быть регулярным. Регулярная структура запутанной программы или её фрагмента позволяет человеку отделить запутанные части и даже идентифицировать алгоритм запутывания.
Применение стандартных синтаксических и статических методов анализа программ на начальном этапе её анализа не должно давать существенных результатов, так как быстрый результат может воодушевлять человека, а его отсутствие, наоборот, угнетать.
Нам не известно ни одного метода запутывания, который бы удовлетворял всем этим признакам. Разработка таких методов является одним из направлений дальнейших исследований.
Другим направлением является разработка методов запутывания и методов анализа запутанных программ на уровне языка ассемблера (машинного кода). Хотя методы запутывания низкого уровня могут оказаться непереносимыми на другие архитектуры, в низкоуровневом запутывании скрыт большой потенциал.
Запутывание
В этом разделе мы дадим формальное определение запутывателя свойства
В дальнейшем мы будем рассматривать программы из класса П неинтерактивных, нереактивных программ. Программе поступают на вход данные характерного размера n. При работе программа не возбуждает и не использует исключительных ситуаций.
